 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRamchalam Kinattinkara Ramakrishnan
An Empirical Study of Low Precision Quantization for TinyML
Mar 10, 2022
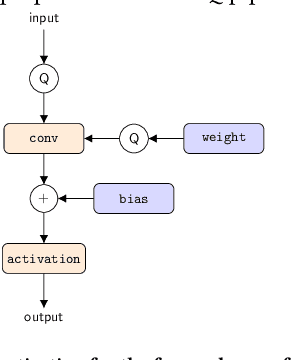

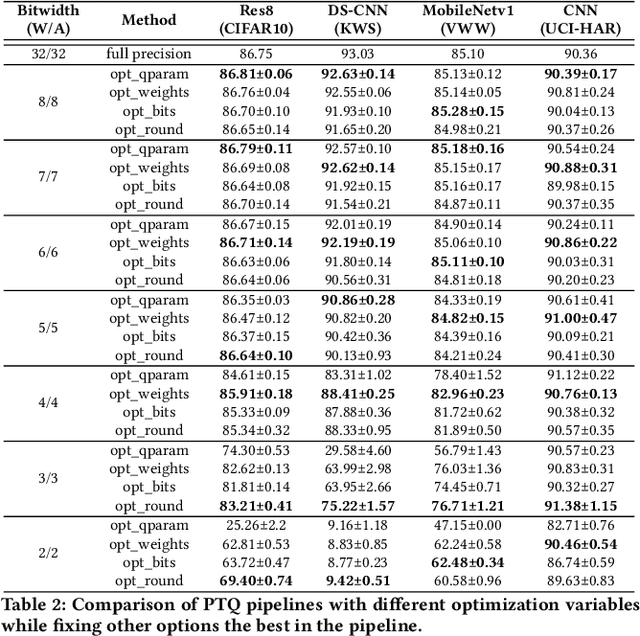
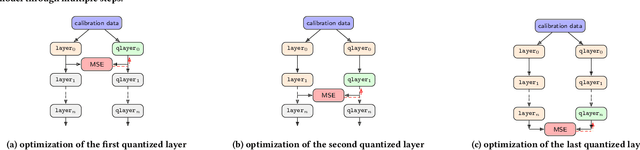
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.
Differentiable Mask Pruning for Neural Networks
Sep 10, 2019



Pruning of neural networks is one of the well-known and promising model simplification techniques. Most neural network models are large and require expensive computations to predict new instances. It is imperative to compress the network to deploy models on low resource devices. Most compression techniques, especially pruning have been focusing on computer vision and convolution neural networks. Existing techniques are complex and require multi-stage optimization and fine-tuning to recover the state-of-the-art accuracy. We introduce a \emph{Differentiable Mask Pruning} (DMP), that simplifies the network while training, and can be used to induce sparsity on weight, filter, node or sub-network. Our method achieves competitive results on standard vision and NLP benchmarks, and is easy to integrate within the deep learning toolbox. DMP bridges the gap between neural model compression and differentiable neural architecture search.
Deep Demosaicing for Edge Implementation
Apr 12, 2019



Most digital cameras use sensors coated with a Color Filter Array (CFA) to capture channel components at every pixel location, resulting in a mosaic image that does not contain pixel values in all channels. Current research on reconstructing these missing channels, also known as demosaicing, introduces many artifacts, such as zipper effect and false color. Many deep learning demosaicing techniques outperform other classical techniques in reducing the impact of artifacts. However, most of these models tend to be over-parametrized. Consequently, edge implementation of the state-of-the-art deep learning-based demosaicing algorithms on low-end edge devices is a major challenge. We provide an exhaustive search of deep neural network architectures and obtain a pareto front of Color Peak Signal to Noise Ratio (CPSNR) as the performance criterion versus the number of parameters as the model complexity that beats the state-of-the-art. Architectures on the pareto front can then be used to choose the best architecture for a variety of resource constraints. Simple architecture search methods such as exhaustive search and grid search require some conditions of the loss function to converge to the optimum. We clarify these conditions in a brief theoretical study