 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYicheng Lin
Breaking of brightness consistency in optical flow with a lightweight CNN network
Oct 24, 2023




Sparse optical flow is widely used in various computer vision tasks, however assuming brightness consistency limits its performance in High Dynamic Range (HDR) environments. In this work, a lightweight network is used to extract illumination robust convolutional features and corners with strong invariance. Modifying the typical brightness consistency of the optical flow method to the convolutional feature consistency yields the light-robust hybrid optical flow method. The proposed network runs at 190 FPS on a commercial CPU because it uses only four convolutional layers to extract feature maps and score maps simultaneously. Since the shallow network is difficult to train directly, a deep network is designed to compute the reliability map that helps it. An end-to-end unsupervised training mode is used for both networks. To validate the proposed method, we compare corner repeatability and matching performance with origin optical flow under dynamic illumination. In addition, a more accurate visual inertial system is constructed by replacing the optical flow method in VINS-Mono. In a public HDR dataset, it reduces translation errors by 93\%. The code is publicly available at https://github.com/linyicheng1/LET-NET.
An Empirical Study of Low Precision Quantization for TinyML
Mar 10, 2022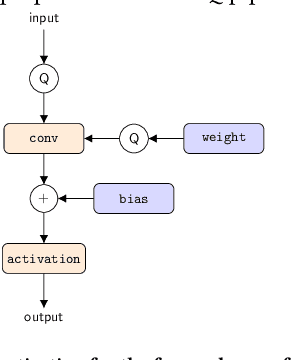

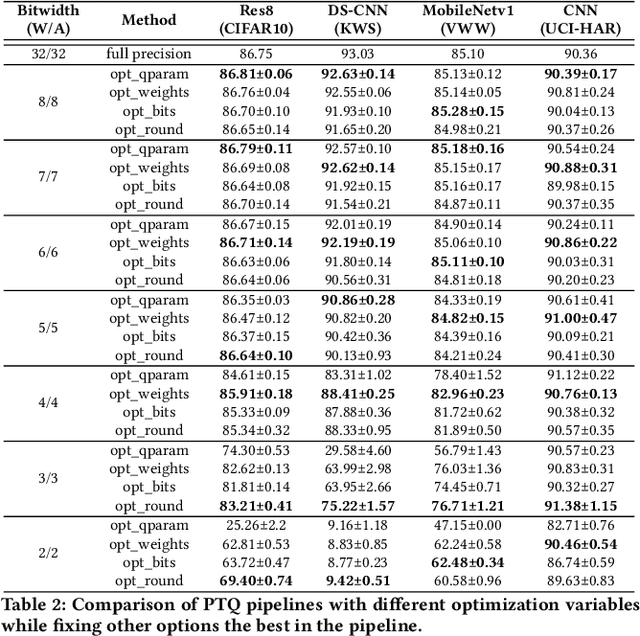
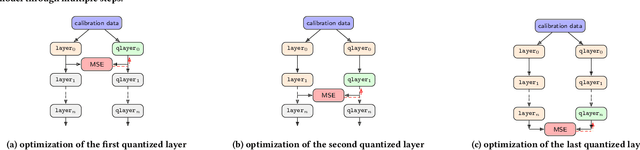
Tiny machine learning (tinyML) has emerged during the past few years aiming to deploy machine learning models to embedded AI processors with highly constrained memory and computation capacity. Low precision quantization is an important model compression technique that can greatly reduce both memory consumption and computation cost of model inference. In this study, we focus on post-training quantization (PTQ) algorithms that quantize a model to low-bit (less than 8-bit) precision with only a small set of calibration data and benchmark them on different tinyML use cases. To achieve a fair comparison, we build a simulated quantization framework to investigate recent PTQ algorithms. Furthermore, we break down those algorithms into essential components and re-assembled a generic PTQ pipeline. With ablation study on different alternatives of components in the pipeline, we reveal key design choices when performing low precision quantization. We hope this work could provide useful data points and shed lights on the future research of low precision quantization.