 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRan Yu
SATac: A Thermoluminescence Enabled Tactile Sensor for Concurrent Perception of Temperature, Pressure, and Shear
Feb 01, 2024
Most vision-based tactile sensors use elastomer deformation to infer tactile information, which can not sense some modalities, like temperature. As an important part of human tactile perception, temperature sensing can help robots better interact with the environment. In this work, we propose a novel multimodal vision-based tactile sensor, SATac, which can simultaneously perceive information of temperature, pressure, and shear. SATac utilizes thermoluminescence of strontium aluminate (SA) to sense a wide range of temperatures with exceptional resolution. Additionally, the pressure and shear can also be perceived by analyzing Voronoi diagram. A series of experiments are conducted to verify the performance of our proposed sensor. We also discuss the possible application scenarios and demonstrate how SATac could benefit robot perception capabilities.
Growing from Exploration: A self-exploring framework for robots based on foundation models
Jan 24, 2024Intelligent robot is the ultimate goal in the robotics field. Existing works leverage learning-based or optimization-based methods to accomplish human-defined tasks. However, the challenge of enabling robots to explore various environments autonomously remains unresolved. In this work, we propose a framework named GExp, which enables robots to explore and learn autonomously without human intervention. To achieve this goal, we devise modules including self-exploration, knowledge-base-building, and close-loop feedback based on foundation models. Inspired by the way that infants interact with the world, GExp encourages robots to understand and explore the environment with a series of self-generated tasks. During the process of exploration, the robot will acquire skills from beneficial experiences that are useful in the future. GExp provides robots with the ability to solve complex tasks through self-exploration. GExp work is independent of prior interactive knowledge and human intervention, allowing it to adapt directly to different scenarios, unlike previous studies that provided in-context examples as few-shot learning. In addition, we propose a workflow of deploying the real-world robot system with self-learned skills as an embodied assistant.
Creating Knowledge Graphs for Geographic Data on the Web
Feb 17, 2023

Geographic data plays an essential role in various Web, Semantic Web and machine learning applications. OpenStreetMap and knowledge graphs are critical complementary sources of geographic data on the Web. However, data veracity, the lack of integration of geographic and semantic characteristics, and incomplete representations substantially limit the data utility. Verification, enrichment and semantic representation are essential for making geographic data accessible for the Semantic Web and machine learning. This article describes recent approaches we developed to tackle these challenges.
Global Spectral Filter Memory Network for Video Object Segmentation
Oct 12, 2022



This paper studies semi-supervised video object segmentation through boosting intra-frame interaction. Recent memory network-based methods focus on exploiting inter-frame temporal reference while paying little attention to intra-frame spatial dependency. Specifically, these segmentation model tends to be susceptible to interference from unrelated nontarget objects in a certain frame. To this end, we propose Global Spectral Filter Memory network (GSFM), which improves intra-frame interaction through learning long-term spatial dependencies in the spectral domain. The key components of GSFM is 2D (inverse) discrete Fourier transform for spatial information mixing. Besides, we empirically find low frequency feature should be enhanced in encoder (backbone) while high frequency for decoder (segmentation head). We attribute this to semantic information extracting role for encoder and fine-grained details highlighting role for decoder. Thus, Low (High) Frequency Module is proposed to fit this circumstance. Extensive experiments on the popular DAVIS and YouTube-VOS benchmarks demonstrate that GSFM noticeably outperforms the baseline method and achieves state-of-the-art performance. Besides, extensive analysis shows that the proposed modules are reasonable and of great generalization ability. Our source code is available at https://github.com/workforai/GSFM.
Learning Quality-aware Dynamic Memory for Video Object Segmentation
Jul 16, 2022
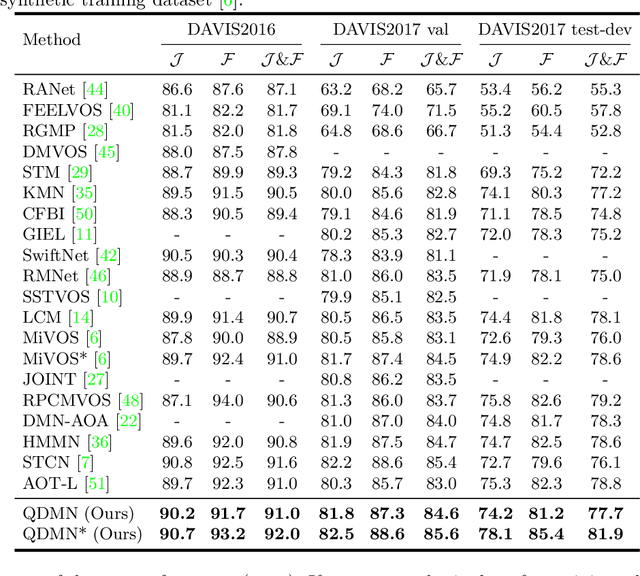
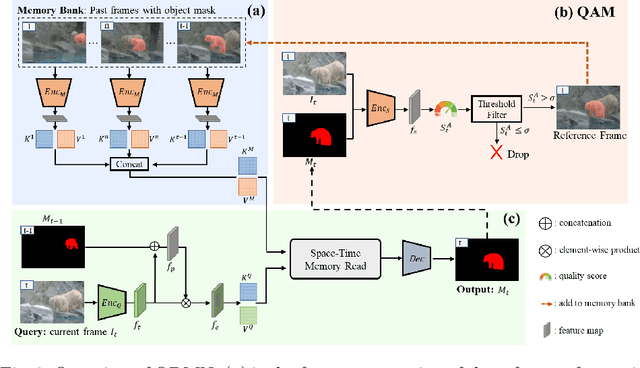
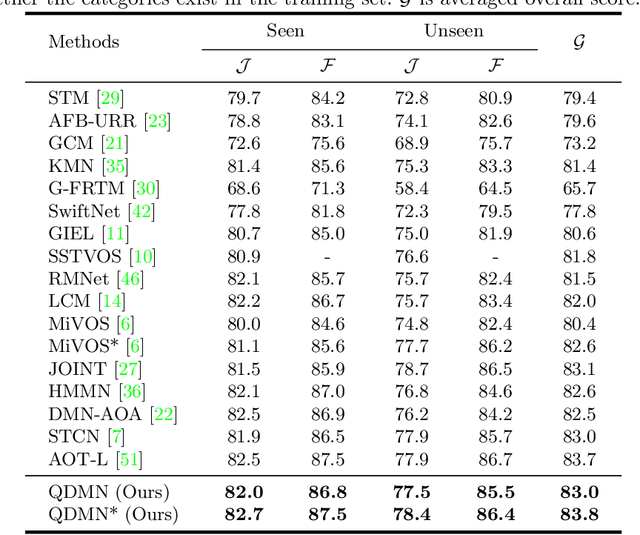
Recently, several spatial-temporal memory-based methods have verified that storing intermediate frames and their masks as memory are helpful to segment target objects in videos. However, they mainly focus on better matching between the current frame and the memory frames without explicitly paying attention to the quality of the memory. Therefore, frames with poor segmentation masks are prone to be memorized, which leads to a segmentation mask error accumulation problem and further affect the segmentation performance. In addition, the linear increase of memory frames with the growth of frame number also limits the ability of the models to handle long videos. To this end, we propose a Quality-aware Dynamic Memory Network (QDMN) to evaluate the segmentation quality of each frame, allowing the memory bank to selectively store accurately segmented frames to prevent the error accumulation problem. Then, we combine the segmentation quality with temporal consistency to dynamically update the memory bank to improve the practicability of the models. Without any bells and whistles, our QDMN achieves new state-of-the-art performance on both DAVIS and YouTube-VOS benchmarks. Moreover, extensive experiments demonstrate that the proposed Quality Assessment Module (QAM) can be applied to memory-based methods as generic plugins and significantly improves performance. Our source code is available at https://github.com/workforai/QDMN.
Still Haven't Found What You're Looking For -- Detecting the Intent of Web Search Missions from User Interaction Features
Jul 04, 2022



Web search is among the most frequent online activities. Whereas traditional information retrieval techniques focus on the information need behind a user query, previous work has shown that user behaviour and interaction can provide important signals for understanding the underlying intent of a search mission. An established taxonomy distinguishes between transactional, navigational and informational search missions, where in particular the latter involve a learning goal, i.e. the intent to acquire knowledge about a particular topic. We introduce a supervised approach for classifying online search missions into either of these categories by utilising a range of features obtained from the user interactions during an online search mission. Applying our model to a dataset of real-world query logs, we show that search missions can be categorised with an average F1 score of 63% and accuracy of 69%, while performance on informational and navigational missions is particularly promising (F1>75%). This suggests the potential to utilise such supervised classification during online search to better facilitate retrieval and ranking as well as to improve affiliated services, such as targeted online ads.
SaL-Lightning Dataset: Search and Eye Gaze Behavior, Resource Interactions and Knowledge Gain during Web Search
Jan 07, 2022
The emerging research field Search as Learning investigates how the Web facilitates learning through modern information retrieval systems. SAL research requires significant amounts of data that capture both search behavior of users and their acquired knowledge in order to obtain conclusive insights or train supervised machine learning models. However, the creation of such datasets is costly and requires interdisciplinary efforts in order to design studies and capture a wide range of features. In this paper, we address this issue and introduce an extensive dataset based on a user study, in which $114$ participants were asked to learn about the formation of lightning and thunder. Participants' knowledge states were measured before and after Web search through multiple-choice questionnaires and essay-based free recall tasks. To enable future research in SAL-related tasks we recorded a plethora of features and person-related attributes. Besides the screen recordings, visited Web pages, and detailed browsing histories, a large number of behavioral features and resource features were monitored. We underline the usefulness of the dataset by describing three, already published, use cases.
WorldKG: A World-Scale Geographic Knowledge Graph
Sep 21, 2021



OpenStreetMap is a rich source of openly available geographic information. However, the representation of geographic entities, e.g., buildings, mountains, and cities, within OpenStreetMap is highly heterogeneous, diverse, and incomplete. As a result, this rich data source is hardly usable for real-world applications. This paper presents WorldKG -- a new geographic knowledge graph aiming to provide a comprehensive semantic representation of geographic entities in OpenStreetMap. We describe the WorldKG knowledge graph, including its ontology that builds the semantic dataset backbone, the extraction procedure of the ontology and geographic entities from OpenStreetMap, and the methods to enhance entity annotation. We perform statistical and qualitative dataset assessment, demonstrating the large scale and high precision of the semantic geographic information in WorldKG.
Real-time Human-Centric Segmentation for Complex Video Scenes
Aug 16, 2021
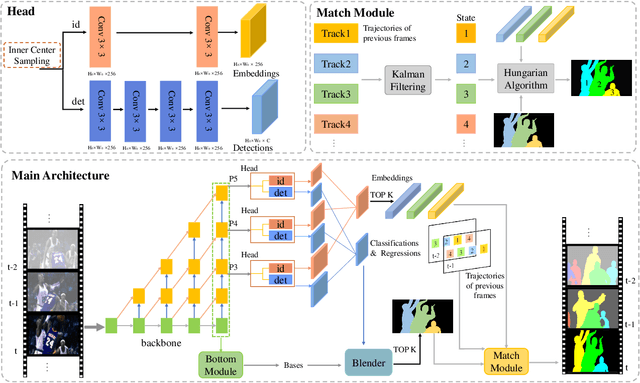

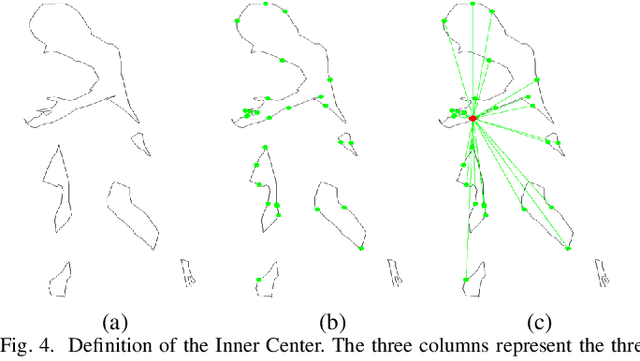
Most existing video tasks related to "human" focus on the segmentation of salient humans, ignoring the unspecified others in the video. Few studies have focused on segmenting and tracking all humans in a complex video, including pedestrians and humans of other states (e.g., seated, riding, or occluded). In this paper, we propose a novel framework, abbreviated as HVISNet, that segments and tracks all presented people in given videos based on a one-stage detector. To better evaluate complex scenes, we offer a new benchmark called HVIS (Human Video Instance Segmentation), which comprises 1447 human instance masks in 805 high-resolution videos in diverse scenes. Extensive experiments show that our proposed HVISNet outperforms the state-of-the-art methods in terms of accuracy at a real-time inference speed (30 FPS), especially on complex video scenes. We also notice that using the center of the bounding box to distinguish different individuals severely deteriorates the segmentation accuracy, especially in heavily occluded conditions. This common phenomenon is referred to as the ambiguous positive samples problem. To alleviate this problem, we propose a mechanism named Inner Center Sampling to improve the accuracy of instance segmentation. Such a plug-and-play inner center sampling mechanism can be incorporated in any instance segmentation models based on a one-stage detector to improve the performance. In particular, it gains 4.1 mAP improvement on the state-of-the-art method in the case of occluded humans. Code and data are available at https://github.com/IIGROUP/HVISNet.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 27, 2021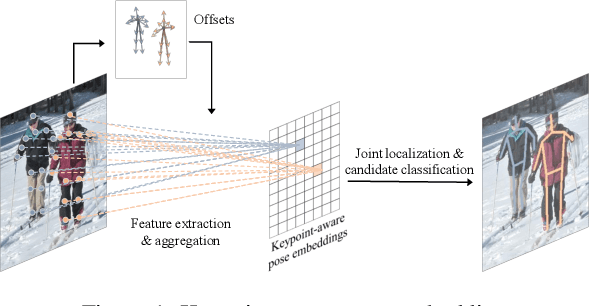
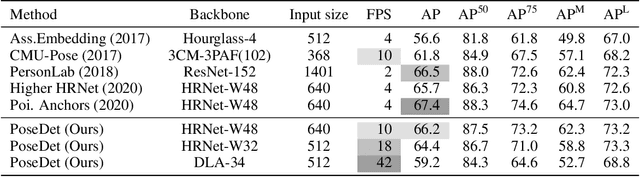
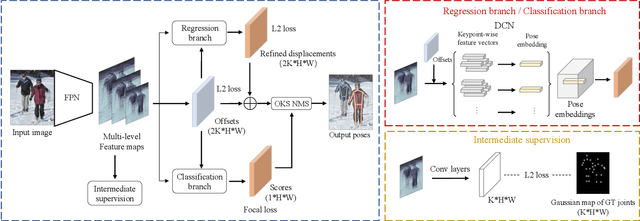
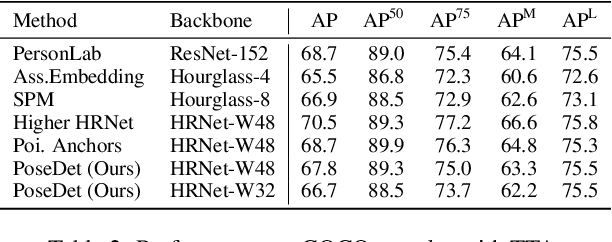
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.