 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRatnadira Widyasari
A Systematic Literature Review on Explainability for Machine/Deep Learning-based Software Engineering Research
Jan 26, 2024
The remarkable achievements of Artificial Intelligence (AI) algorithms, particularly in Machine Learning (ML) and Deep Learning (DL), have fueled their extensive deployment across multiple sectors, including Software Engineering (SE). However, due to their black-box nature, these promising AI-driven SE models are still far from being deployed in practice. This lack of explainability poses unwanted risks for their applications in critical tasks, such as vulnerability detection, where decision-making transparency is of paramount importance. This paper endeavors to elucidate this interdisciplinary domain by presenting a systematic literature review of approaches that aim to improve the explainability of AI models within the context of SE. The review canvasses work appearing in the most prominent SE & AI conferences and journals, and spans 63 papers across 21 unique SE tasks. Based on three key Research Questions (RQs), we aim to (1) summarize the SE tasks where XAI techniques have shown success to date; (2) classify and analyze different XAI techniques; and (3) investigate existing evaluation approaches. Based on our findings, we identified a set of challenges remaining to be addressed in existing studies, together with a roadmap highlighting potential opportunities we deemed appropriate and important for future work.
Multi-Granularity Detector for Vulnerability Fixes
May 23, 2023

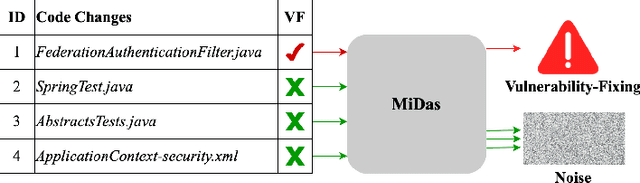
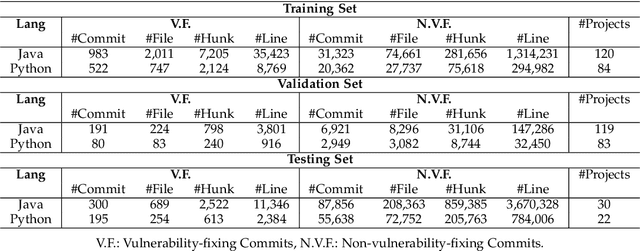
With the increasing reliance on Open Source Software, users are exposed to third-party library vulnerabilities. Software Composition Analysis (SCA) tools have been created to alert users of such vulnerabilities. SCA requires the identification of vulnerability-fixing commits. Prior works have proposed methods that can automatically identify such vulnerability-fixing commits. However, identifying such commits is highly challenging, as only a very small minority of commits are vulnerability fixing. Moreover, code changes can be noisy and difficult to analyze. We observe that noise can occur at different levels of detail, making it challenging to detect vulnerability fixes accurately. To address these challenges and boost the effectiveness of prior works, we propose MiDas (Multi-Granularity Detector for Vulnerability Fixes). Unique from prior works, Midas constructs different neural networks for each level of code change granularity, corresponding to commit-level, file-level, hunk-level, and line-level, following their natural organization. It then utilizes an ensemble model that combines all base models to generate the final prediction. This design allows MiDas to better handle the noisy and highly imbalanced nature of vulnerability-fixing commit data. Additionally, to reduce the human effort required to inspect code changes, we have designed an effort-aware adjustment for Midas's outputs based on commit length. The evaluation results demonstrate that MiDas outperforms the current state-of-the-art baseline in terms of AUC by 4.9% and 13.7% on Java and Python-based datasets, respectively. Furthermore, in terms of two effort-aware metrics, EffortCost@L and Popt@L, MiDas also outperforms the state-of-the-art baseline, achieving improvements of up to 28.2% and 15.9% on Java, and 60% and 51.4% on Python, respectively.