 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRenyuan Xu
Neural Network-Based Score Estimation in Diffusion Models: Optimization and Generalization
Feb 06, 2024
Diffusion models have emerged as a powerful tool rivaling GANs in generating high-quality samples with improved fidelity, flexibility, and robustness. A key component of these models is to learn the score function through score matching. Despite empirical success on various tasks, it remains unclear whether gradient-based algorithms can learn the score function with a provable accuracy. As a first step toward answering this question, this paper establishes a mathematical framework for analyzing score estimation using neural networks trained by gradient descent. Our analysis covers both the optimization and the generalization aspects of the learning procedure. In particular, we propose a parametric form to formulate the denoising score-matching problem as a regression with noisy labels. Compared to the standard supervised learning setup, the score-matching problem introduces distinct challenges, including unbounded input, vector-valued output, and an additional time variable, preventing existing techniques from being applied directly. In this paper, we show that with a properly designed neural network architecture, the score function can be accurately approximated by a reproducing kernel Hilbert space induced by neural tangent kernels. Furthermore, by applying an early-stopping rule for gradient descent and leveraging certain coupling arguments between neural network training and kernel regression, we establish the first generalization error (sample complexity) bounds for learning the score function despite the presence of noise in the observations. Our analysis is grounded in a novel parametric form of the neural network and an innovative connection between score matching and regression analysis, facilitating the application of advanced statistical and optimization techniques.
Fast Policy Learning for Linear Quadratic Control with Entropy Regularization
Dec 03, 2023This paper proposes and analyzes two new policy learning methods: regularized policy gradient (RPG) and iterative policy optimization (IPO), for a class of discounted linear-quadratic control (LQC) problems over an infinite time horizon with entropy regularization. Assuming access to the exact policy evaluation, both proposed approaches are proven to converge linearly in finding optimal policies of the regularized LQC. Moreover, the IPO method can achieve a super-linear convergence rate once it enters a local region around the optimal policy. Finally, when the optimal policy for an RL problem with a known environment is appropriately transferred as the initial policy to an RL problem with an unknown environment, the IPO method is shown to enable a super-linear convergence rate if the two environments are sufficiently close. Performances of these proposed algorithms are supported by numerical examples.
Risk-sensitive Markov Decision Process and Learning under General Utility Functions
Nov 22, 2023Reinforcement Learning (RL) has gained substantial attention across diverse application domains and theoretical investigations. Existing literature on RL theory largely focuses on risk-neutral settings where the decision-maker learns to maximize the expected cumulative reward. However, in practical scenarios such as portfolio management and e-commerce recommendations, decision-makers often persist in heterogeneous risk preferences subject to outcome uncertainties, which can not be well-captured by the risk-neural framework. Incorporating these preferences can be approached through utility theory, yet the development of risk-sensitive RL under general utility functions remains an open question for theoretical exploration. In this paper, we consider a scenario where the decision-maker seeks to optimize a general utility function of the cumulative reward in the framework of a Markov decision process (MDP). To facilitate the Dynamic Programming Principle and Bellman equation, we enlarge the state space with an additional dimension that accounts for the cumulative reward. We propose a discretized approximation scheme to the MDP under enlarged state space, which is tractable and key for algorithmic design. We then propose a modified value iteration algorithm that employs an epsilon-covering over the space of cumulative reward. When a simulator is accessible, our algorithm efficiently learns a near-optimal policy with guaranteed sample complexity. In the absence of a simulator, our algorithm, designed with an upper-confidence-bound exploration approach, identifies a near-optimal policy while ensuring a guaranteed regret bound. For both algorithms, we match the theoretical lower bounds for the risk-neutral setting.
Policy Gradient Converges to the Globally Optimal Policy for Nearly Linear-Quadratic Regulators
Mar 23, 2023Nonlinear control systems with partial information to the decision maker are prevalent in a variety of applications. As a step toward studying such nonlinear systems, this work explores reinforcement learning methods for finding the optimal policy in the nearly linear-quadratic regulator systems. In particular, we consider a dynamic system that combines linear and nonlinear components, and is governed by a policy with the same structure. Assuming that the nonlinear component comprises kernels with small Lipschitz coefficients, we characterize the optimization landscape of the cost function. Although the cost function is nonconvex in general, we establish the local strong convexity and smoothness in the vicinity of the global optimizer. Additionally, we propose an initialization mechanism to leverage these properties. Building on the developments, we design a policy gradient algorithm that is guaranteed to converge to the globally optimal policy with a linear rate.
Asymptotic Analysis of Deep Residual Networks
Dec 15, 2022



We investigate the asymptotic properties of deep Residual networks (ResNets) as the number of layers increases. We first show the existence of scaling regimes for trained weights markedly different from those implicitly assumed in the neural ODE literature. We study the convergence of the hidden state dynamics in these scaling regimes, showing that one may obtain an ODE, a stochastic differential equation (SDE) or neither of these. In particular, our findings point to the existence of a diffusive regime in which the deep network limit is described by a class of stochastic differential equations (SDEs). Finally, we derive the corresponding scaling limits for the backpropagation dynamics.
Risk-Aware Linear Bandits: Theory and Applications in Smart Order Routing
Aug 04, 2022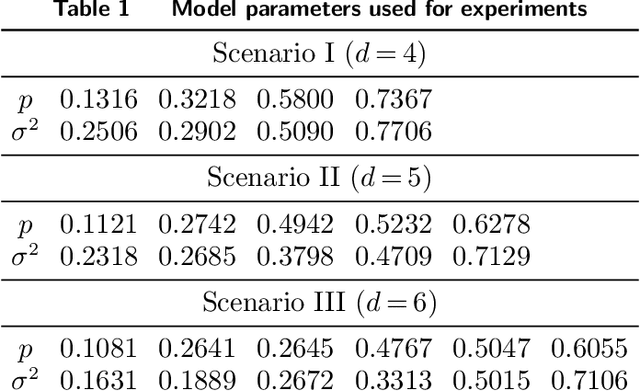
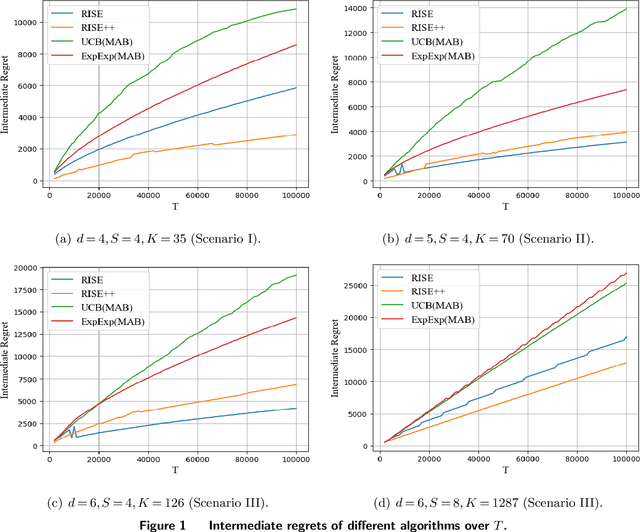
Motivated by practical considerations in machine learning for financial decision-making, such as risk-aversion and large action space, we initiate the study of risk-aware linear bandits. Specifically, we consider regret minimization under the mean-variance measure when facing a set of actions whose rewards can be expressed as linear functions of (initially) unknown parameters. Driven by the variance-minimizing G-optimal design, we propose the Risk-Aware Explore-then-Commit (RISE) algorithm and the Risk-Aware Successive Elimination (RISE++) algorithm. Then, we rigorously analyze their regret upper bounds to show that, by leveraging the linear structure, the algorithms can dramatically reduce the regret when compared to existing methods. Finally, we demonstrate the performance of the algorithms by conducting extensive numerical experiments in a synthetic smart order routing setup. Our results show that both RISE and RISE++ can outperform the competing methods, especially in complex decision-making scenarios.
Recent Advances in Reinforcement Learning in Finance
Dec 21, 2021
The rapid changes in the finance industry due to the increasing amount of data have revolutionized the techniques on data processing and data analysis and brought new theoretical and computational challenges. In contrast to classical stochastic control theory and other analytical approaches for solving financial decision-making problems that heavily reply on model assumptions, new developments from reinforcement learning (RL) are able to make full use of the large amount of financial data with fewer model assumptions and to improve decisions in complex financial environments. This survey paper aims to review the recent developments and use of RL approaches in finance. We give an introduction to Markov decision processes, which is the setting for many of the commonly used RL approaches. Various algorithms are then introduced with a focus on value and policy based methods that do not require any model assumptions. Connections are made with neural networks to extend the framework to encompass deep RL algorithms. Our survey concludes by discussing the application of these RL algorithms in a variety of decision-making problems in finance, including optimal execution, portfolio optimization, option pricing and hedging, market making, smart order routing, and robo-advising.
Mean-Field Multi-Agent Reinforcement Learning: A Decentralized Network Approach
Aug 05, 2021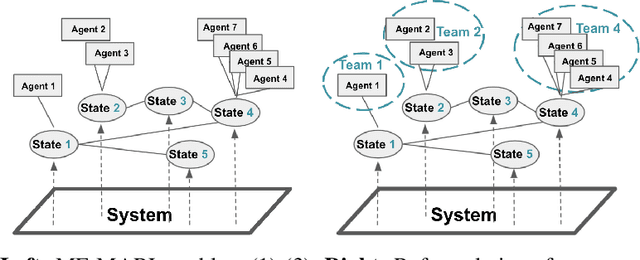
One of the challenges for multi-agent reinforcement learning (MARL) is designing efficient learning algorithms for a large system in which each agent has only limited or partial information of the entire system. In this system, it is desirable to learn policies of a decentralized type. A recent and promising paradigm to analyze such decentralized MARL is to take network structures into consideration. While exciting progress has been made to analyze decentralized MARL with the network of agents, often found in social networks and team video games, little is known theoretically for decentralized MARL with the network of states, frequently used for modeling self-driving vehicles, ride-sharing, and data and traffic routing. This paper proposes a framework called localized training and decentralized execution to study MARL with network of states, with homogeneous (a.k.a. mean-field type) agents. Localized training means that agents only need to collect local information in their neighboring states during the training phase; decentralized execution implies that, after the training stage, agents can execute the learned decentralized policies, which only requires knowledge of the agents' current states. The key idea is to utilize the homogeneity of agents and regroup them according to their states, thus the formulation of a networked Markov decision process with teams of agents, enabling the update of the Q-function in a localized fashion. In order to design an efficient and scalable reinforcement learning algorithm under such a framework, we adopt the actor-critic approach with over-parameterized neural networks, and establish the convergence and sample complexity for our algorithm, shown to be scalable with respect to the size of both agents and states.
Policy Gradient Methods Find the Nash Equilibrium in N-player General-sum Linear-quadratic Games
Jul 27, 2021



We consider a general-sum N-player linear-quadratic game with stochastic dynamics over a finite horizon and prove the global convergence of the natural policy gradient method to the Nash equilibrium. In order to prove the convergence of the method, we require a certain amount of noise in the system. We give a condition, essentially a lower bound on the covariance of the noise in terms of the model parameters, in order to guarantee convergence. We illustrate our results with numerical experiments to show that even in situations where the policy gradient method may not converge in the deterministic setting, the addition of noise leads to convergence.
Scaling Properties of Deep Residual Networks
Jun 10, 2021



Residual networks (ResNets) have displayed impressive results in pattern recognition and, recently, have garnered considerable theoretical interest due to a perceived link with neural ordinary differential equations (neural ODEs). This link relies on the convergence of network weights to a smooth function as the number of layers increases. We investigate the properties of weights trained by stochastic gradient descent and their scaling with network depth through detailed numerical experiments. We observe the existence of scaling regimes markedly different from those assumed in neural ODE literature. Depending on certain features of the network architecture, such as the smoothness of the activation function, one may obtain an alternative ODE limit, a stochastic differential equation or neither of these. These findings cast doubts on the validity of the neural ODE model as an adequate asymptotic description of deep ResNets and point to an alternative class of differential equations as a better description of the deep network limit.