 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobert Kleinberg
Faster Recalibration of an Online Predictor via Approachability
Oct 25, 2023
Predictive models in ML need to be trustworthy and reliable, which often at the very least means outputting calibrated probabilities. This can be particularly difficult to guarantee in the online prediction setting when the outcome sequence can be generated adversarially. In this paper we introduce a technique using Blackwell's approachability theorem for taking an online predictive model which might not be calibrated and transforming its predictions to calibrated predictions without much increase to the loss of the original model. Our proposed algorithm achieves calibration and accuracy at a faster rate than existing techniques arXiv:1607.03594 and is the first algorithm to offer a flexible tradeoff between calibration error and accuracy in the online setting. We demonstrate this by characterizing the space of jointly achievable calibration and regret using our technique.
U-Calibration: Forecasting for an Unknown Agent
Jun 30, 2023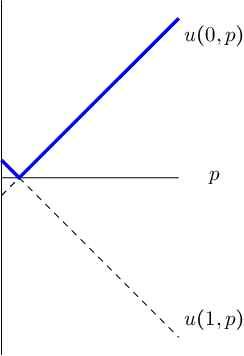
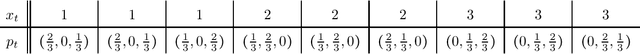
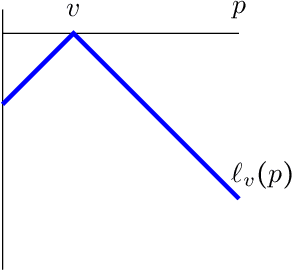
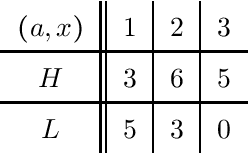
We consider the problem of evaluating forecasts of binary events whose predictions are consumed by rational agents who take an action in response to a prediction, but whose utility is unknown to the forecaster. We show that optimizing forecasts for a single scoring rule (e.g., the Brier score) cannot guarantee low regret for all possible agents. In contrast, forecasts that are well-calibrated guarantee that all agents incur sublinear regret. However, calibration is not a necessary criterion here (it is possible for miscalibrated forecasts to provide good regret guarantees for all possible agents), and calibrated forecasting procedures have provably worse convergence rates than forecasting procedures targeting a single scoring rule. Motivated by this, we present a new metric for evaluating forecasts that we call U-calibration, equal to the maximal regret of the sequence of forecasts when evaluated under any bounded scoring rule. We show that sublinear U-calibration error is a necessary and sufficient condition for all agents to achieve sublinear regret guarantees. We additionally demonstrate how to compute the U-calibration error efficiently and provide an online algorithm that achieves $O(\sqrt{T})$ U-calibration error (on par with optimal rates for optimizing for a single scoring rule, and bypassing lower bounds for the traditionally calibrated learning procedures). Finally, we discuss generalizations to the multiclass prediction setting.
Non-Stochastic CDF Estimation Using Threshold Queries
Jan 13, 2023Estimating the empirical distribution of a scalar-valued data set is a basic and fundamental task. In this paper, we tackle the problem of estimating an empirical distribution in a setting with two challenging features. First, the algorithm does not directly observe the data; instead, it only asks a limited number of threshold queries about each sample. Second, the data are not assumed to be independent and identically distributed; instead, we allow for an arbitrary process generating the samples, including an adaptive adversary. These considerations are relevant, for example, when modeling a seller experimenting with posted prices to estimate the distribution of consumers' willingness to pay for a product: offering a price and observing a consumer's purchase decision is equivalent to asking a single threshold query about their value, and the distribution of consumers' values may be non-stationary over time, as early adopters may differ markedly from late adopters. Our main result quantifies, to within a constant factor, the sample complexity of estimating the empirical CDF of a sequence of elements of $[n]$, up to $\varepsilon$ additive error, using one threshold query per sample. The complexity depends only logarithmically on $n$, and our result can be interpreted as extending the existing logarithmic-complexity results for noisy binary search to the more challenging setting where noise is non-stochastic. Along the way to designing our algorithm, we consider a more general model in which the algorithm is allowed to make a limited number of simultaneous threshold queries on each sample. We solve this problem using Blackwell's Approachability Theorem and the exponential weights method. As a side result of independent interest, we characterize the minimum number of simultaneous threshold queries required by deterministic CDF estimation algorithms.
Non-monotonic Resource Utilization in the Bandits with Knapsacks Problem
Sep 24, 2022Bandits with knapsacks (BwK) is an influential model of sequential decision-making under uncertainty that incorporates resource consumption constraints. In each round, the decision-maker observes an outcome consisting of a reward and a vector of nonnegative resource consumptions, and the budget of each resource is decremented by its consumption. In this paper we introduce a natural generalization of the stochastic BwK problem that allows non-monotonic resource utilization. In each round, the decision-maker observes an outcome consisting of a reward and a vector of resource drifts that can be positive, negative or zero, and the budget of each resource is incremented by its drift. Our main result is a Markov decision process (MDP) policy that has constant regret against a linear programming (LP) relaxation when the decision-maker knows the true outcome distributions. We build upon this to develop a learning algorithm that has logarithmic regret against the same LP relaxation when the decision-maker does not know the true outcome distributions. We also present a reduction from BwK to our model that shows our regret bound matches existing results.
Procrastinating with Confidence: Near-Optimal, Anytime, Adaptive Algorithm Configuration
Feb 14, 2019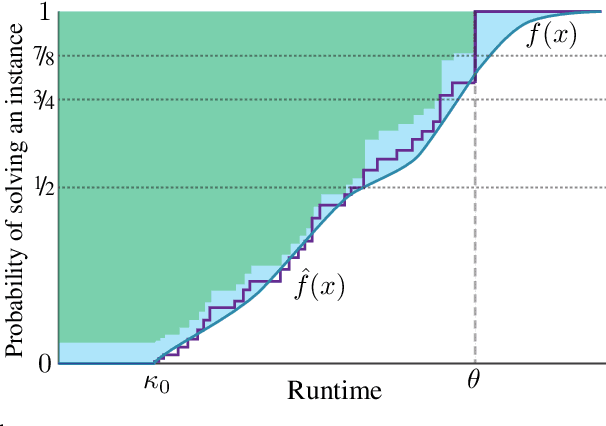
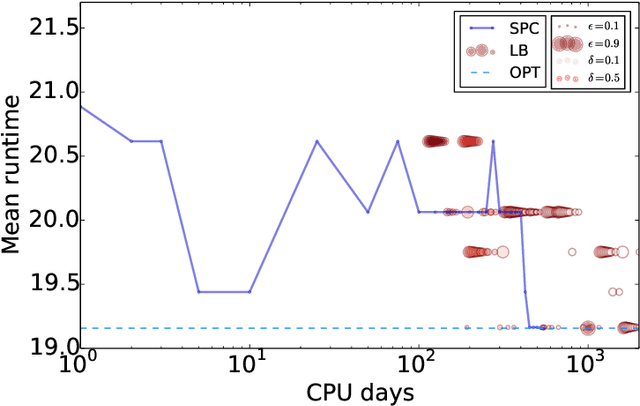
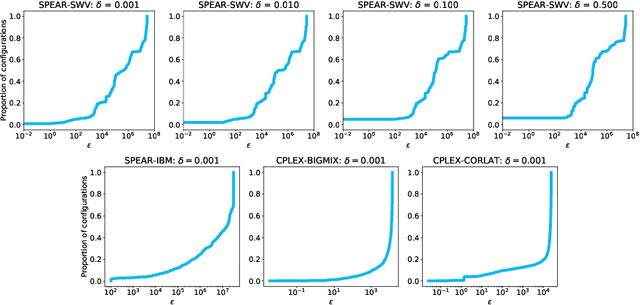
Algorithm configuration methods optimize the performance of a parameterized heuristic algorithm on a given distribution of problem instances. Recent work introduced an algorithm configuration procedure ('Structured Procrastination') that provably achieves near optimal performance with high probability and with nearly minimal runtime in the worst case. It also offers an $\textit{anytime}$ property: it keeps tightening its optimality guarantees the longer it is run. Unfortunately, Structured Procrastination is not $\textit{adaptive}$ to characteristics of the parameterized algorithm: it treats every input like the worst case. Follow-up work ('Leaps and Bounds') achieves adaptivity but trades away the anytime property. This paper introduces a new algorithm configuration method, 'Structured Procrastination with Confidence', that preserves the near-optimality and anytime properties of Structured Procrastination while adding adaptivity. In particular, the new algorithm will perform dramatically faster in settings where many algorithm configurations perform poorly; we show empirically that such settings arise frequently in practice.
An Alternative View: When Does SGD Escape Local Minima?
Aug 16, 2018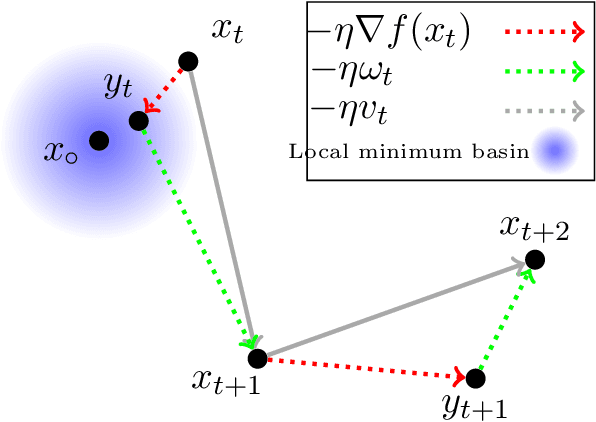
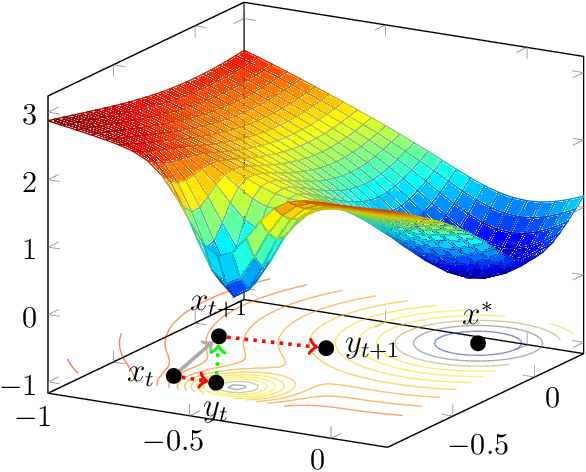
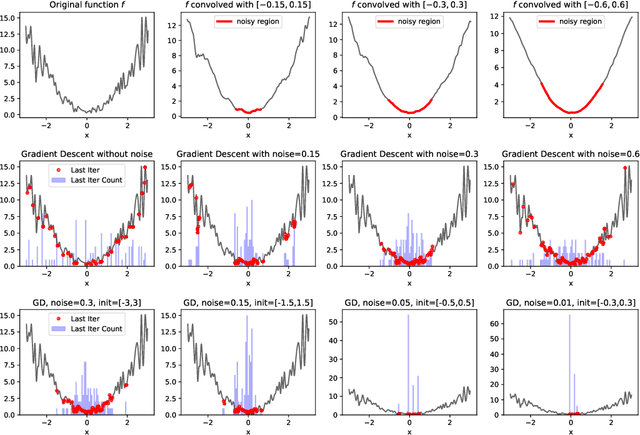
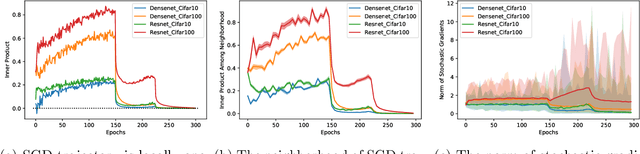
Stochastic gradient descent (SGD) is widely used in machine learning. Although being commonly viewed as a fast but not accurate version of gradient descent (GD), it always finds better solutions than GD for modern neural networks. In order to understand this phenomenon, we take an alternative view that SGD is working on the convolved (thus smoothed) version of the loss function. We show that, even if the function $f$ has many bad local minima or saddle points, as long as for every point $x$, the weighted average of the gradients of its neighborhoods is one point convex with respect to the desired solution $x^*$, SGD will get close to, and then stay around $x^*$ with constant probability. More specifically, SGD will not get stuck at "sharp" local minima with small diameters, as long as the neighborhoods of these regions contain enough gradient information. The neighborhood size is controlled by step size and gradient noise. Our result identifies a set of functions that SGD provably works, which is much larger than the set of convex functions. Empirically, we observe that the loss surface of neural networks enjoys nice one point convexity properties locally, therefore our theorem helps explain why SGD works so well for neural networks.
Can Deep Reinforcement Learning Solve Erdos-Selfridge-Spencer Games?
Jun 29, 2018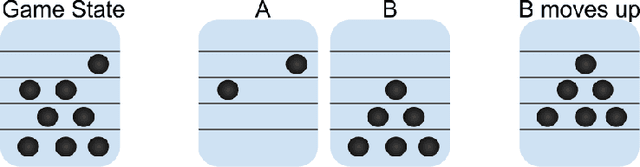
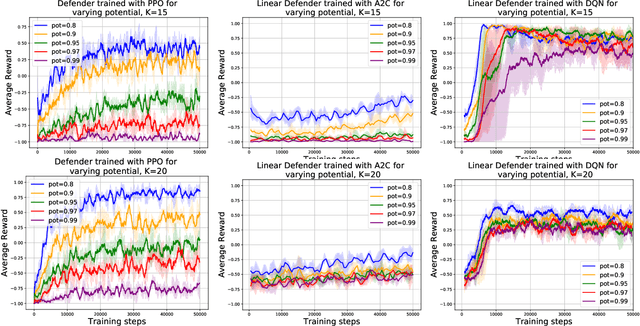
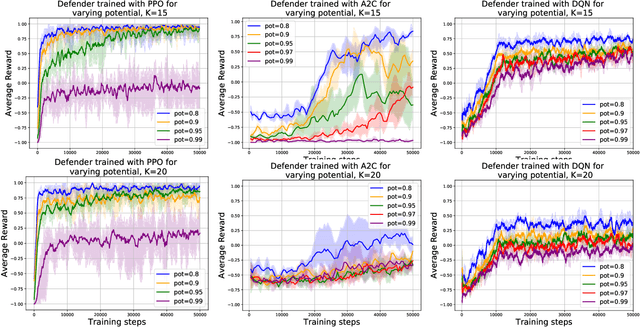
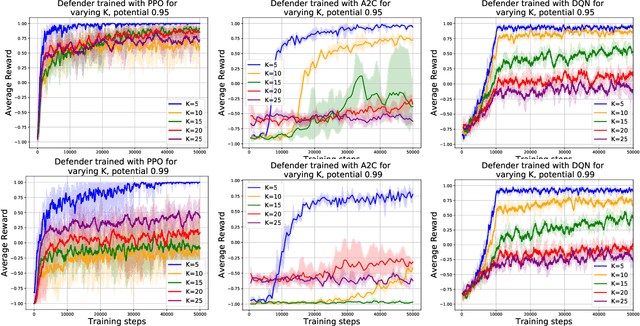
Deep reinforcement learning has achieved many recent successes, but our understanding of its strengths and limitations is hampered by the lack of rich environments in which we can fully characterize optimal behavior, and correspondingly diagnose individual actions against such a characterization. Here we consider a family of combinatorial games, arising from work of Erdos, Selfridge, and Spencer, and we propose their use as environments for evaluating and comparing different approaches to reinforcement learning. These games have a number of appealing features: they are challenging for current learning approaches, but they form (i) a low-dimensional, simply parametrized environment where (ii) there is a linear closed form solution for optimal behavior from any state, and (iii) the difficulty of the game can be tuned by changing environment parameters in an interpretable way. We use these Erdos-Selfridge-Spencer games not only to compare different algorithms, but test for generalization, make comparisons to supervised learning, analyse multiagent play, and even develop a self play algorithm. Code can be found at: https://github.com/rubai5/ESS_Game
Bandits and Experts in Metric Spaces
Apr 27, 2018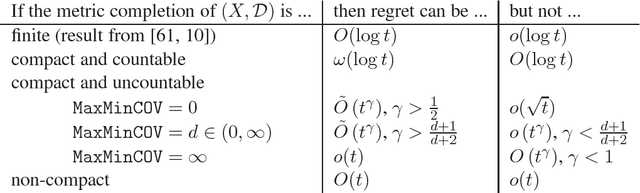
In a multi-armed bandit problem, an online algorithm chooses from a set of strategies in a sequence of trials so as to maximize the total payoff of the chosen strategies. While the performance of bandit algorithms with a small finite strategy set is quite well understood, bandit problems with large strategy sets are still a topic of very active investigation, motivated by practical applications such as online auctions and web advertisement. The goal of such research is to identify broad and natural classes of strategy sets and payoff functions which enable the design of efficient solutions. In this work we study a very general setting for the multi-armed bandit problem in which the strategies form a metric space, and the payoff function satisfies a Lipschitz condition with respect to the metric. We refer to this problem as the "Lipschitz MAB problem". We present a solution for the multi-armed bandit problem in this setting. That is, for every metric space we define an isometry invariant which bounds from below the performance of Lipschitz MAB algorithms for this metric space, and we present an algorithm which comes arbitrarily close to meeting this bound. Furthermore, our technique gives even better results for benign payoff functions. We also address the full-feedback ("best expert") version of the problem, where after every round the payoffs from all arms are revealed.
Bandits with Knapsacks
Sep 05, 2017Multi-armed bandit problems are the predominant theoretical model of exploration-exploitation tradeoffs in learning, and they have countless applications ranging from medical trials, to communication networks, to Web search and advertising. In many of these application domains the learner may be constrained by one or more supply (or budget) limits, in addition to the customary limitation on the time horizon. The literature lacks a general model encompassing these sorts of problems. We introduce such a model, called "bandits with knapsacks", that combines aspects of stochastic integer programming with online learning. A distinctive feature of our problem, in comparison to the existing regret-minimization literature, is that the optimal policy for a given latent distribution may significantly outperform the policy that plays the optimal fixed arm. Consequently, achieving sublinear regret in the bandits-with-knapsacks problem is significantly more challenging than in conventional bandit problems. We present two algorithms whose reward is close to the information-theoretic optimum: one is based on a novel "balanced exploration" paradigm, while the other is a primal-dual algorithm that uses multiplicative updates. Further, we prove that the regret achieved by both algorithms is optimal up to polylogarithmic factors. We illustrate the generality of the problem by presenting applications in a number of different domains including electronic commerce, routing, and scheduling. As one example of a concrete application, we consider the problem of dynamic posted pricing with limited supply and obtain the first algorithm whose regret, with respect to the optimal dynamic policy, is sublinear in the supply.
Dynamic Pricing with Limited Supply
Nov 26, 2013We consider the problem of dynamic pricing with limited supply. A seller has $k$ identical items for sale and is facing $n$ potential buyers ("agents") that are arriving sequentially. Each agent is interested in buying one item. Each agent's value for an item is an IID sample from some fixed distribution with support $[0,1]$. The seller offers a take-it-or-leave-it price to each arriving agent (possibly different for different agents), and aims to maximize his expected revenue. We focus on "prior-independent" mechanisms -- ones that do not use any information about the distribution. They are desirable because knowing the distribution is unrealistic in many practical scenarios. We study how the revenue of such mechanisms compares to the revenue of the optimal offline mechanism that knows the distribution ("offline benchmark"). We present a prior-independent dynamic pricing mechanism whose revenue is at most $O((k \log n)^{2/3})$ less than the offline benchmark, for every distribution that is regular. In fact, this guarantee holds without *any* assumptions if the benchmark is relaxed to fixed-price mechanisms. Further, we prove a matching lower bound. The performance guarantee for the same mechanism can be improved to $O(\sqrt{k} \log n)$, with a distribution-dependent constant, if $k/n$ is sufficiently small. We show that, in the worst case over all demand distributions, this is essentially the best rate that can be obtained with a distribution-specific constant. On a technical level, we exploit the connection to multi-armed bandits (MAB). While dynamic pricing with unlimited supply can easily be seen as an MAB problem, the intuition behind MAB approaches breaks when applied to the setting with limited supply. Our high-level conceptual contribution is that even the limited supply setting can be fruitfully treated as a bandit problem.