 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobert Legenstein
Adversarially Robust Spiking Neural Networks Through Conversion
Nov 15, 2023




Spiking neural networks (SNNs) provide an energy-efficient alternative to a variety of artificial neural network (ANN) based AI applications. As the progress in neuromorphic computing with SNNs expands their use in applications, the problem of adversarial robustness of SNNs becomes more pronounced. To the contrary of the widely explored end-to-end adversarial training based solutions, we address the limited progress in scalable robust SNN training methods by proposing an adversarially robust ANN-to-SNN conversion algorithm. Our method provides an efficient approach to embrace various computationally demanding robust learning objectives that have been proposed for ANNs. During a post-conversion robust finetuning phase, our method adversarially optimizes both layer-wise firing thresholds and synaptic connectivity weights of the SNN to maintain transferred robustness gains from the pre-trained ANN. We perform experimental evaluations in numerous adaptive adversarial settings that account for the spike-based operation dynamics of SNNs, and show that our approach yields a scalable state-of-the-art solution for adversarially robust deep SNNs with low-latency.
Restoring Vision in Adverse Weather Conditions with Patch-Based Denoising Diffusion Models
Jul 29, 2022



Image restoration under adverse weather conditions has been of significant interest for various computer vision applications. Recent successful methods rely on the current progress in deep neural network architectural designs (e.g., with vision transformers). Motivated by the recent progress achieved with state-of-the-art conditional generative models, we present a novel patch-based image restoration algorithm based on denoising diffusion probabilistic models. Our patch-based diffusion modeling approach enables size-agnostic image restoration by using a guided denoising process with smoothed noise estimates across overlapping patches during inference. We empirically evaluate our model on benchmark datasets for image desnowing, combined deraining and dehazing, and raindrop removal. We demonstrate our approach to achieve state-of-the-art performances on both weather-specific and multi-weather image restoration, and qualitatively show strong generalization to real-world test images.
Memory-enriched computation and learning in spiking neural networks through Hebbian plasticity
May 23, 2022



Memory is a key component of biological neural systems that enables the retention of information over a huge range of temporal scales, ranging from hundreds of milliseconds up to years. While Hebbian plasticity is believed to play a pivotal role in biological memory, it has so far been analyzed mostly in the context of pattern completion and unsupervised learning. Here, we propose that Hebbian plasticity is fundamental for computations in biological neural systems. We introduce a novel spiking neural network architecture that is enriched by Hebbian synaptic plasticity. We show that Hebbian enrichment renders spiking neural networks surprisingly versatile in terms of their computational as well as learning capabilities. It improves their abilities for out-of-distribution generalization, one-shot learning, cross-modal generative association, language processing, and reward-based learning. As spiking neural networks are the basis for energy-efficient neuromorphic hardware, this also suggests that powerful cognitive neuromorphic systems can be build based on this principle.
Many-Joint Robot Arm Control with Recurrent Spiking Neural Networks
Apr 08, 2021



In the paper, we show how scalable, low-cost trunk-like robotic arms can be constructed using only basic 3D-printing equipment and simple electronics. The design is based on uniform, stackable joint modules with three degrees of freedom each. Moreover, we present an approach for controlling these robots with recurrent spiking neural networks. At first, a spiking forward model learns motor-pose correlations from movement observations. After training, intentions can be projected back through unrolled spike trains of the forward model essentially routing the intention-driven motor gradients towards the respective joints, which unfolds goal-direction navigation. We demonstrate that spiking neural networks can thus effectively control trunk-like robotic arms with up to 75 articulated degrees of freedom with near millimeter accuracy.
Oscillatory background activity implements a backbone for sampling-based computations in spiking neural networks
Jun 19, 2020



Various data suggest that the brain carries out probabilistic inference. Models that perform inference through sampling are particularly appealing since instead of requiring networks to perform sophisticated mathematical operations, they can simply exploit stochasticity in neuron behavior. However, sampling from complex distributions is a hard problem. In particular, mixing behavior is often very sensitive to the temperature parameter which controls the stochasticity of the sampler. We propose that background oscillations, an ubiquitous phenomenon throughout the brain, can mitigate this issue and thus implement the backbone for sampling-based computations in spiking neural networks. We first show that both in current-based and conductance-based neuron models, the level of background activity effectively defines the sampling temperature of the network. This mechanism allows brain networks to flexibly control the sampling behavior, either favoring convergence to local optima or promoting mixing. We then demonstrate that background oscillations can in this way structure stochastic computations into discrete sampling episodes. In each such episode, solutions are first explored at high temperatures before annealing to low temperatures favors convergence to a good solution.
Embodied Synaptic Plasticity with Online Reinforcement learning
Mar 03, 2020



The endeavor to understand the brain involves multiple collaborating research fields. Classically, synaptic plasticity rules derived by theoretical neuroscientists are evaluated in isolation on pattern classification tasks. This contrasts with the biological brain which purpose is to control a body in closed-loop. This paper contributes to bringing the fields of computational neuroscience and robotics closer together by integrating open-source software components from these two fields. The resulting framework allows to evaluate the validity of biologically-plausibe plasticity models in closed-loop robotics environments. We demonstrate this framework to evaluate Synaptic Plasticity with Online REinforcement learning (SPORE), a reward-learning rule based on synaptic sampling, on two visuomotor tasks: reaching and lane following. We show that SPORE is capable of learning to perform policies within the course of simulated hours for both tasks. Provisional parameter explorations indicate that the learning rate and the temperature driving the stochastic processes that govern synaptic learning dynamics need to be regulated for performance improvements to be retained. We conclude by discussing the recent deep reinforcement learning techniques which would be beneficial to increase the functionality of SPORE on visuomotor tasks.
* 18 pages, 5 figures, published in frontiers in neurorobotics
Efficient Reward-Based Structural Plasticity on a SpiNNaker 2 Prototype
Mar 20, 2019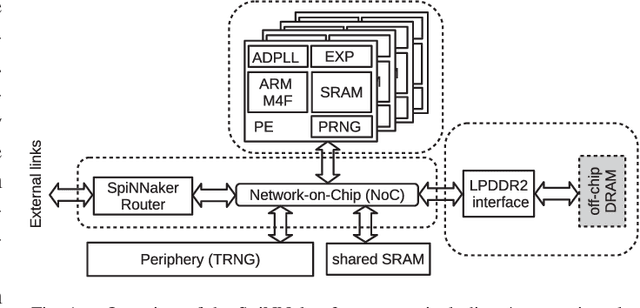
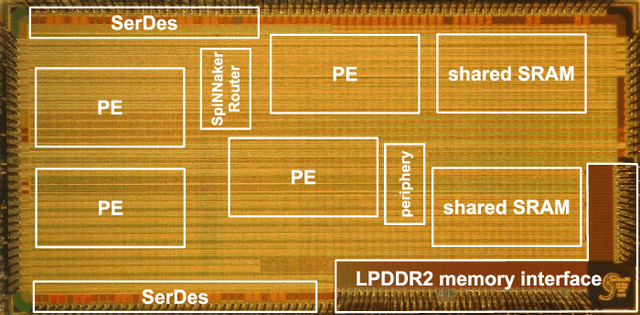
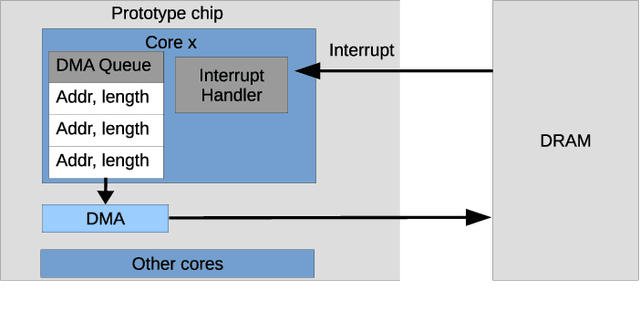
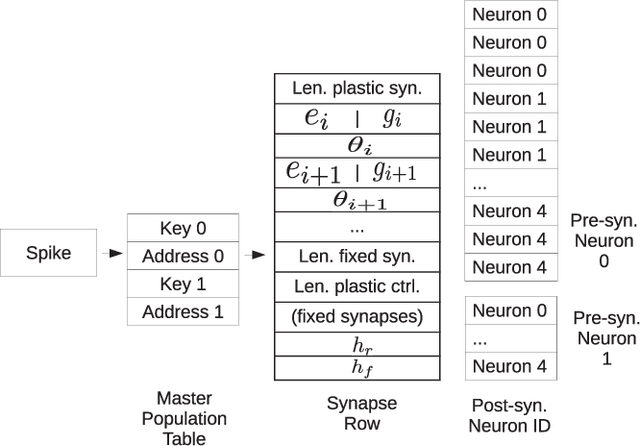
Advances in neuroscience uncover the mechanisms employed by the brain to efficiently solve complex learning tasks with very limited resources. However, the efficiency is often lost when one tries to port these findings to a silicon substrate, since brain-inspired algorithms often make extensive use of complex functions such as random number generators, that are expensive to compute on standard general purpose hardware. The prototype chip of the 2nd generation SpiNNaker system is designed to overcome this problem. Low-power ARM processors equipped with a random number generator and an exponential function accelerator enable the efficient execution of brain-inspired algorithms. We implement the recently introduced reward-based synaptic sampling model that employs structural plasticity to learn a function or task. The numerical simulation of the model requires to update the synapse variables in each time step including an explorative random term. To the best of our knowledge, this is the most complex synapse model implemented so far on the SpiNNaker system. By making efficient use of the hardware accelerators and numerical optimizations the computation time of one plasticity update is reduced by a factor of 2. This, combined with fitting the model into to the local SRAM, leads to 62% energy reduction compared to the case without accelerators and the use of external DRAM. The model implementation is integrated into the SpiNNaker software framework allowing for scalability onto larger systems. The hardware-software system presented in this work paves the way for power-efficient mobile and biomedical applications with biologically plausible brain-inspired algorithms.
Biologically inspired alternatives to backpropagation through time for learning in recurrent neural nets
Jan 25, 2019



The way how recurrently connected networks of spiking neurons in the brain acquire powerful information processing capabilities through learning has remained a mystery. This lack of understanding is linked to a lack of learning algorithms for recurrent networks of spiking neurons (RSNNs) that are both functionally powerful and can be implemented by known biological mechanisms. Since RSNNs are simultaneously a primary target for implementations of brain-inspired circuits in neuromorphic hardware, this lack of algorithmic insight also hinders technological progress in that area. The gold standard for learning in recurrent neural networks in machine learning is back-propagation through time (BPTT), which implements stochastic gradient descent with regard to a given loss function. But BPTT is unrealistic from a biological perspective, since it requires a transmission of error signals backwards in time and in space, i.e., from post- to presynaptic neurons. We show that an online merging of locally available information during a computation with suitable top-down learning signals in real-time provides highly capable approximations to BPTT. For tasks where information on errors arises only late during a network computation, we enrich locally available information through feedforward eligibility traces of synapses that can easily be computed in an online manner. The resulting new generation of learning algorithms for recurrent neural networks provides a new understanding of network learning in the brain that can be tested experimentally. In addition, these algorithms provide efficient methods for on-chip training of RSNNs in neuromorphic hardware.
Long short-term memory and learning-to-learn in networks of spiking neurons
Nov 02, 2018


Recurrent networks of spiking neurons (RSNNs) underlie the astounding computing and learning capabilities of the brain. But computing and learning capabilities of RSNN models have remained poor, at least in comparison with ANNs. We address two possible reasons for that. One is that RSNNs in the brain are not randomly connected or designed according to simple rules, and they do not start learning as a tabula rasa network. Rather, RSNNs in the brain were optimized for their tasks through evolution, development, and prior experience. Details of these optimization processes are largely unknown. But their functional contribution can be approximated through powerful optimization methods, such as backpropagation through time (BPTT). A second major mismatch between RSNNs in the brain and models is that the latter only show a small fraction of the dynamics of neurons and synapses in the brain. We include neurons in our RSNN model that reproduce one prominent dynamical process of biological neurons that takes place at the behaviourally relevant time scale of seconds: neuronal adaptation. We denote these networks as LSNNs because of their Long short-term memory. The inclusion of adapting neurons drastically increases the computing and learning capability of RSNNs if they are trained and configured by deep learning (BPTT combined with a rewiring algorithm that optimizes the network architecture). In fact, the computational performance of these RSNNs approaches for the first time that of LSTM networks. In addition RSNNs with adapting neurons can acquire abstract knowledge from prior learning in a Learning-to-Learn (L2L) scheme, and transfer that knowledge in order to learn new but related tasks from very few examples. We demonstrate this for supervised learning and reinforcement learning.
Deep Rewiring: Training very sparse deep networks
Aug 07, 2018



Neuromorphic hardware tends to pose limits on the connectivity of deep networks that one can run on them. But also generic hardware and software implementations of deep learning run more efficiently for sparse networks. Several methods exist for pruning connections of a neural network after it was trained without connectivity constraints. We present an algorithm, DEEP R, that enables us to train directly a sparsely connected neural network. DEEP R automatically rewires the network during supervised training so that connections are there where they are most needed for the task, while its total number is all the time strictly bounded. We demonstrate that DEEP R can be used to train very sparse feedforward and recurrent neural networks on standard benchmark tasks with just a minor loss in performance. DEEP R is based on a rigorous theoretical foundation that views rewiring as stochastic sampling of network configurations from a posterior.