 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobert West
Edisum: Summarizing and Explaining Wikipedia Edits at Scale
Apr 04, 2024
An edit summary is a succinct comment written by a Wikipedia editor explaining the nature of, and reasons for, an edit to a Wikipedia page. Edit summaries are crucial for maintaining the encyclopedia: they are the first thing seen by content moderators and help them decide whether to accept or reject an edit. Additionally, edit summaries constitute a valuable data source for researchers. Unfortunately, as we show, for many edits, summaries are either missing or incomplete. To overcome this problem and help editors write useful edit summaries, we propose a model for recommending edit summaries generated by a language model trained to produce good edit summaries given the representation of an edit diff. This is a challenging task for multiple reasons, including mixed-quality training data, the need to understand not only what was changed in the article but also why it was changed, and efficiency requirements imposed by the scale of Wikipedia. We address these challenges by curating a mix of human and synthetically generated training data and fine-tuning a generative language model sufficiently small to be used on Wikipedia at scale. Our model performs on par with human editors. Commercial large language models are able to solve this task better than human editors, but would be too expensive to run on Wikipedia at scale. More broadly, this paper showcases how language modeling technology can be used to support humans in maintaining one of the largest and most visible projects on the Web.
Can Language Models Recognize Convincing Arguments?
Mar 31, 2024The remarkable and ever-increasing capabilities of Large Language Models (LLMs) have raised concerns about their potential misuse for creating personalized, convincing misinformation and propaganda. To gain insights into LLMs' persuasive capabilities without directly engaging in experimentation with humans, we propose studying their performance on the related task of detecting convincing arguments. We extend a dataset by Durmus & Cardie (2018) with debates, votes, and user traits and propose tasks measuring LLMs' ability to (1) distinguish between strong and weak arguments, (2) predict stances based on beliefs and demographic characteristics, and (3) determine the appeal of an argument to an individual based on their traits. We show that LLMs perform on par with humans in these tasks and that combining predictions from different LLMs yields significant performance gains, even surpassing human performance. The data and code released with this paper contribute to the crucial ongoing effort of continuously evaluating and monitoring the rapidly evolving capabilities and potential impact of LLMs.
The Era of Semantic Decoding
Mar 21, 2024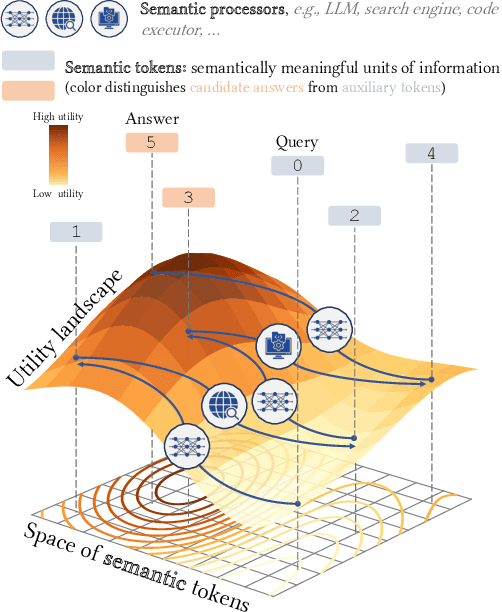
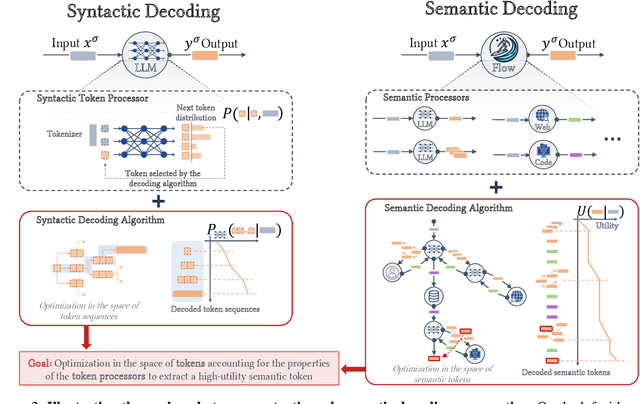
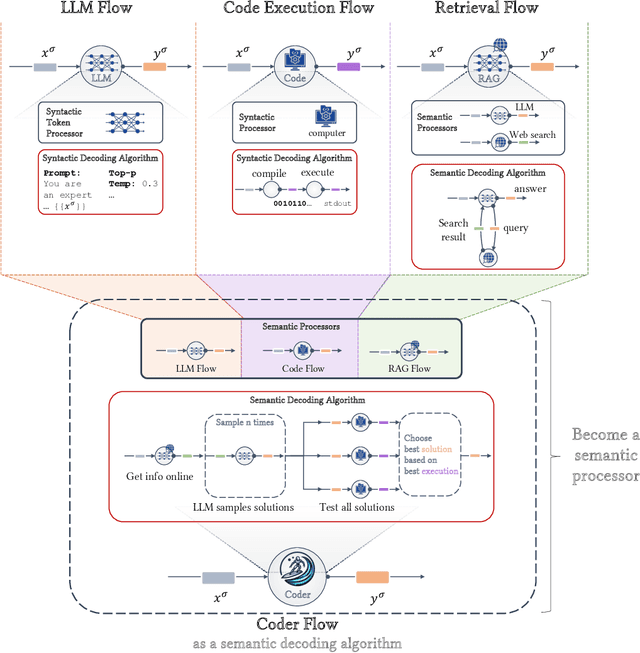
Recent work demonstrated great promise in the idea of orchestrating collaborations between LLMs, human input, and various tools to address the inherent limitations of LLMs. We propose a novel perspective called semantic decoding, which frames these collaborative processes as optimization procedures in semantic space. Specifically, we conceptualize LLMs as semantic processors that manipulate meaningful pieces of information that we call semantic tokens (known thoughts). LLMs are among a large pool of other semantic processors, including humans and tools, such as search engines or code executors. Collectively, semantic processors engage in dynamic exchanges of semantic tokens to progressively construct high-utility outputs. We refer to these orchestrated interactions among semantic processors, optimizing and searching in semantic space, as semantic decoding algorithms. This concept draws a direct parallel to the well-studied problem of syntactic decoding, which involves crafting algorithms to best exploit auto-regressive language models for extracting high-utility sequences of syntactic tokens. By focusing on the semantic level and disregarding syntactic details, we gain a fresh perspective on the engineering of AI systems, enabling us to imagine systems with much greater complexity and capabilities. In this position paper, we formalize the transition from syntactic to semantic tokens as well as the analogy between syntactic and semantic decoding. Subsequently, we explore the possibilities of optimizing within the space of semantic tokens via semantic decoding algorithms. We conclude with a list of research opportunities and questions arising from this fresh perspective. The semantic decoding perspective offers a powerful abstraction for search and optimization directly in the space of meaningful concepts, with semantic tokens as the fundamental units of a new type of computation.
Emojinize: Enriching Any Text with Emoji Translations
Mar 07, 2024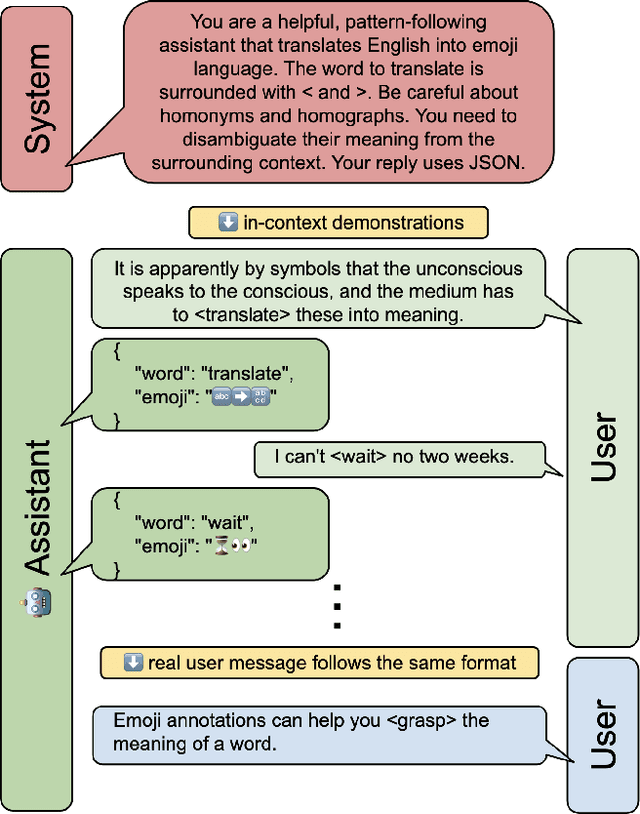
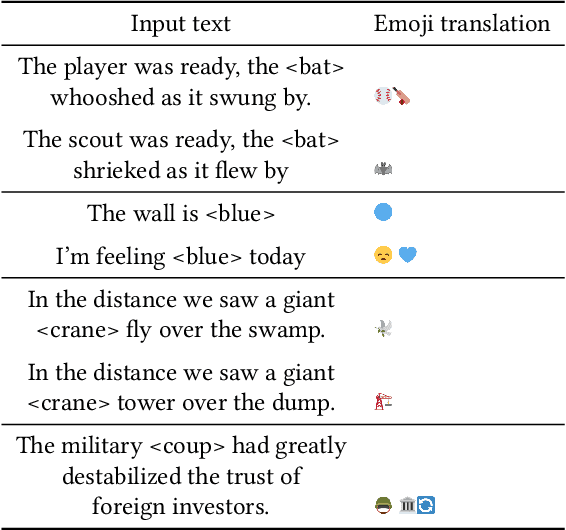
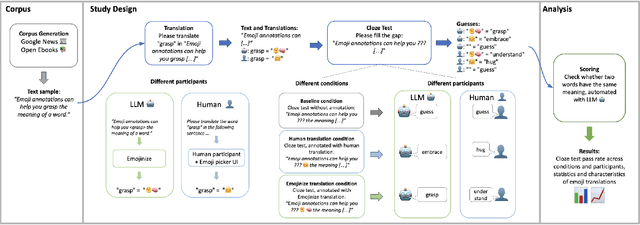
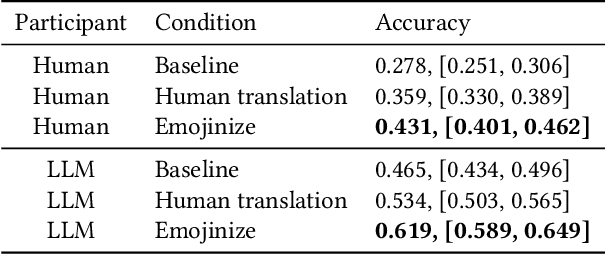
Emoji have become ubiquitous in written communication, on the Web and beyond. They can emphasize or clarify emotions, add details to conversations, or simply serve decorative purposes. This casual use, however, barely scratches the surface of the expressive power of emoji. To further unleash this power, we present Emojinize, a method for translating arbitrary text phrases into sequences of one or more emoji without requiring human input. By leveraging the power of large language models, Emojinize can choose appropriate emoji by disambiguating based on context (eg, cricket-bat vs bat) and can express complex concepts compositionally by combining multiple emoji (eq, "Emojinize" is translated to input-latin-letters right-arrow grinning-face). In a cloze test--based user study, we show that Emojinize's emoji translations increase the human guessability of masked words by 55%, whereas human-picked emoji translations do so by only 29%. These results suggest that emoji provide a sufficiently rich vocabulary to accurately translate a wide variety of words. Moreover, annotating words and phrases with Emojinize's emoji translations opens the door to numerous downstream applications, including children learning how to read, adults learning foreign languages, and text understanding for people with learning disabilities.
Do Llamas Work in English? On the Latent Language of Multilingual Transformers
Feb 24, 2024We ask whether multilingual language models trained on unbalanced, English-dominated corpora use English as an internal pivot language -- a question of key importance for understanding how language models function and the origins of linguistic bias. Focusing on the Llama-2 family of transformer models, our study uses carefully constructed non-English prompts with a unique correct single-token continuation. From layer to layer, transformers gradually map an input embedding of the final prompt token to an output embedding from which next-token probabilities are computed. Tracking intermediate embeddings through their high-dimensional space reveals three distinct phases, whereby intermediate embeddings (1) start far away from output token embeddings; (2) already allow for decoding a semantically correct next token in the middle layers, but give higher probability to its version in English than in the input language; (3) finally move into an input-language-specific region of the embedding space. We cast these results into a conceptual model where the three phases operate in "input space", "concept space", and "output space", respectively. Crucially, our evidence suggests that the abstract "concept space" lies closer to English than to other languages, which may have important consequences regarding the biases held by multilingual language models.
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Feb 23, 2024Large language models (LLMs) have been shown to perform better when asked to reason step-by-step before answering a question. However, it is unclear to what degree the model's final answer is faithful to the stated reasoning steps. In this paper, we perform a causal mediation analysis on twelve LLMs to examine how intermediate reasoning steps generated by the LLM influence the final outcome and find that LLMs do not reliably use their intermediate reasoning steps when generating an answer. To address this issue, we introduce FRODO, a framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective. Our experiments show that FRODO significantly outperforms four competitive baselines. Furthermore, FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets. Finally, we find that FRODO's rationales are more faithful to its final answer predictions than standard supervised fine-tuning.
Getting Serious about Humor: Crafting Humor Datasets with Unfunny Large Language Models
Feb 23, 2024
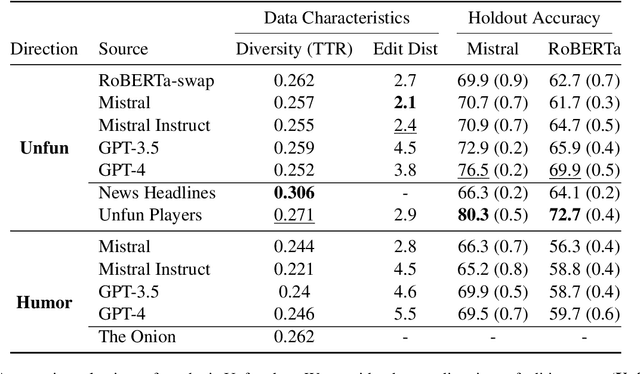
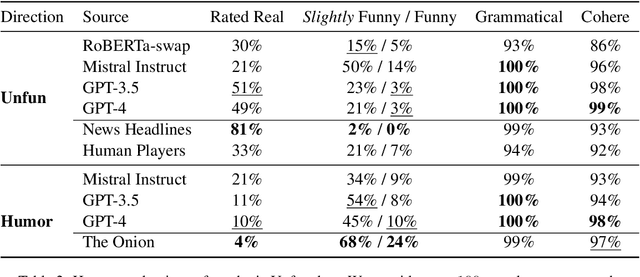
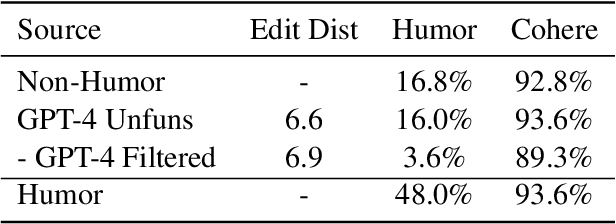
Humor is a fundamental facet of human cognition and interaction. Yet, despite recent advances in natural language processing, humor detection remains a challenging task that is complicated by the scarcity of datasets that pair humorous texts with similar non-humorous counterparts. In our work, we investigate whether large language models (LLMs), can generate synthetic data for humor detection via editing texts. We benchmark LLMs on an existing human dataset and show that current LLMs display an impressive ability to `unfun' jokes, as judged by humans and as measured on the downstream task of humor detection. We extend our approach to a code-mixed English-Hindi humor dataset, where we find that GPT-4's synthetic data is highly rated by bilingual annotators and provides challenging adversarial examples for humor classifiers.
Symbolic Autoencoding for Self-Supervised Sequence Learning
Feb 16, 2024Traditional language models, adept at next-token prediction in text sequences, often struggle with transduction tasks between distinct symbolic systems, particularly when parallel data is scarce. Addressing this issue, we introduce \textit{symbolic autoencoding} ($\Sigma$AE), a self-supervised framework that harnesses the power of abundant unparallel data alongside limited parallel data. $\Sigma$AE connects two generative models via a discrete bottleneck layer and is optimized end-to-end by minimizing reconstruction loss (simultaneously with supervised loss for the parallel data), such that the sequence generated by the discrete bottleneck can be read out as the transduced input sequence. We also develop gradient-based methods allowing for efficient self-supervised sequence learning despite the discreteness of the bottleneck. Our results demonstrate that $\Sigma$AE significantly enhances performance on transduction tasks, even with minimal parallel data, offering a promising solution for weakly supervised learning scenarios.
Sketch-Guided Constrained Decoding for Boosting Blackbox Large Language Models without Logit Access
Jan 18, 2024Constrained decoding, a technique for enforcing constraints on language model outputs, offers a way to control text generation without retraining or architectural modifications. Its application is, however, typically restricted to models that give users access to next-token distributions (usually via softmax logits), which poses a limitation with blackbox large language models (LLMs). This paper introduces sketch-guided constrained decoding (SGCD), a novel approach to constrained decoding for blackbox LLMs, which operates without access to the logits of the blackbox LLM. SGCD utilizes a locally hosted auxiliary model to refine the output of an unconstrained blackbox LLM, effectively treating this initial output as a "sketch" for further elaboration. This approach is complementary to traditional logit-based techniques and enables the application of constrained decoding in settings where full model transparency is unavailable. We demonstrate the efficacy of SGCD through experiments in closed information extraction and constituency parsing, showing how it enhances the utility and flexibility of blackbox LLMs for complex NLP tasks.