 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoi Faltings
Making Reasoning Matter: Measuring and Improving Faithfulness of Chain-of-Thought Reasoning
Feb 23, 2024
Large language models (LLMs) have been shown to perform better when asked to reason step-by-step before answering a question. However, it is unclear to what degree the model's final answer is faithful to the stated reasoning steps. In this paper, we perform a causal mediation analysis on twelve LLMs to examine how intermediate reasoning steps generated by the LLM influence the final outcome and find that LLMs do not reliably use their intermediate reasoning steps when generating an answer. To address this issue, we introduce FRODO, a framework to tailor small-sized LMs to generate correct reasoning steps and robustly reason over these steps. FRODO consists of an inference module that learns to generate correct reasoning steps using an implicit causal reward function and a reasoning module that learns to faithfully reason over these intermediate inferences using a counterfactual and causal preference objective. Our experiments show that FRODO significantly outperforms four competitive baselines. Furthermore, FRODO improves the robustness and generalization ability of the reasoning LM, yielding higher performance on out-of-distribution test sets. Finally, we find that FRODO's rationales are more faithful to its final answer predictions than standard supervised fine-tuning.
δ-CAUSAL: Exploring Defeasibility in Causal Reasoning
Jan 06, 2024Defeasibility in causal reasoning implies that the causal relationship between cause and effect can be strengthened or weakened. Namely, the causal strength between cause and effect should increase or decrease with the incorporation of strengthening arguments (supporters) or weakening arguments (defeaters), respectively. However, existing works ignore defeasibility in causal reasoning and fail to evaluate existing causal strength metrics in defeasible settings. In this work, we present {\delta}-CAUSAL, the first benchmark dataset for studying defeasibility in causal reasoning. {\delta}-CAUSAL includes around 11K events spanning ten domains, featuring defeasible causality pairs, i.e., cause-effect pairs accompanied by supporters and defeaters. We further show current causal strength metrics fail to reflect the change of causal strength with the incorporation of supporters or defeaters in {\delta}-CAUSAL. To this end, we propose CESAR (Causal Embedding aSsociation with Attention Rating), a metric that measures causal strength based on token-level causal relationships. CESAR achieves a significant 69.7% relative improvement over existing metrics, increasing from 47.2% to 80.1% in capturing the causal strength change brought by supporters and defeaters. We further demonstrate even Large Language Models (LLMs) like GPT-3.5 still lag 4.5 and 10.7 points behind humans in generating supporters and defeaters, emphasizing the challenge posed by {\delta}-CAUSAL.
REFINER: Reasoning Feedback on Intermediate Representations
Apr 04, 2023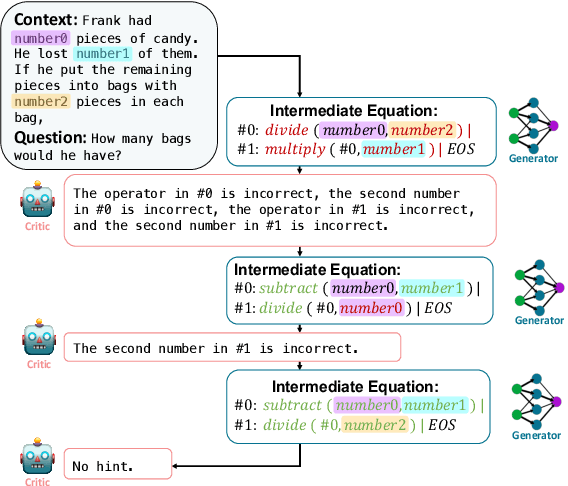
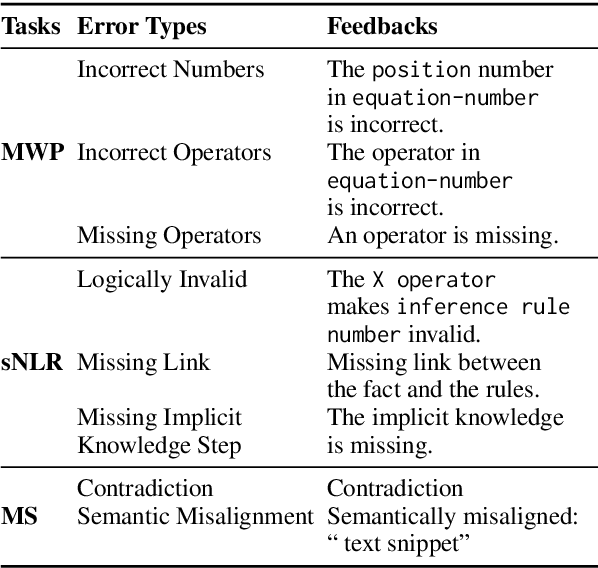
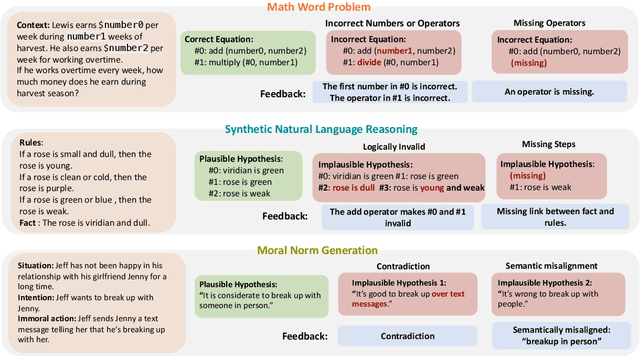
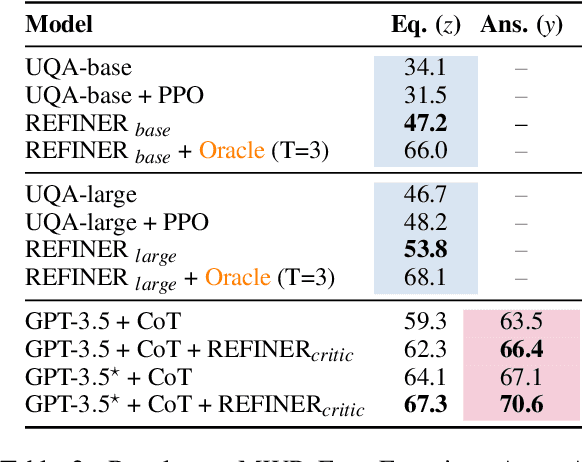
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT3.5 as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
Language Model Decoding as Likelihood-Utility Alignment
Oct 13, 2022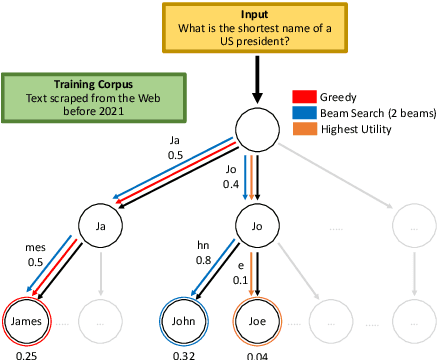

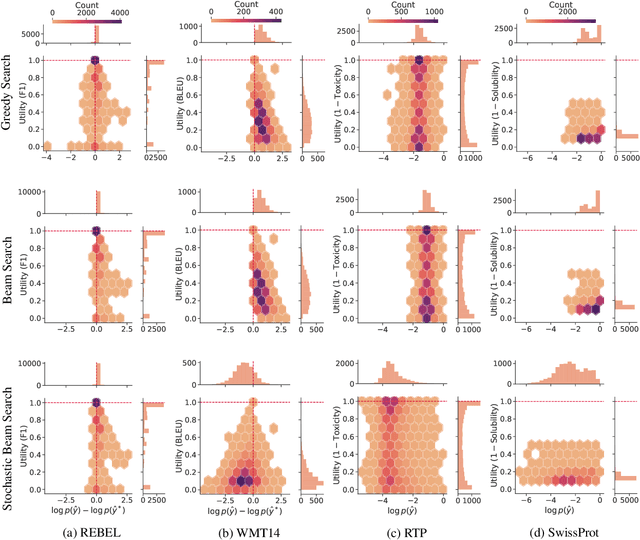
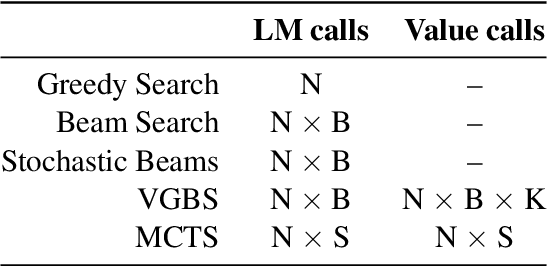
A critical component of a successful language generation pipeline is the decoding algorithm. However, the general principles that should guide the choice of decoding algorithm remain unclear. Previous works only compare decoding algorithms in narrow scenarios and their findings do not generalize across tasks. To better structure the discussion, we introduce a taxonomy that groups decoding strategies based on their implicit assumptions about how well the model's likelihood is aligned with the task-specific notion of utility. We argue that this taxonomy allows a broader view of the decoding problem and can lead to generalizable statements because it is grounded on the interplay between the decoding algorithms and the likelihood-utility misalignment. Specifically, by analyzing the correlation between the likelihood and the utility of predictions across a diverse set of tasks, we provide the first empirical evidence supporting the proposed taxonomy, and a set of principles to structure reasoning when choosing a decoding algorithm. Crucially, our analysis is the first one to relate likelihood-based decoding strategies with strategies that rely on external information such as value-guided methods and prompting, and covers the most diverse set of tasks up-to-date.
Privacy-preserving Data Filtering in Federated Learning Using Influence Approximation
May 23, 2022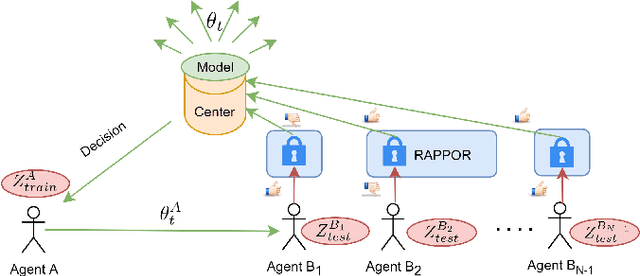
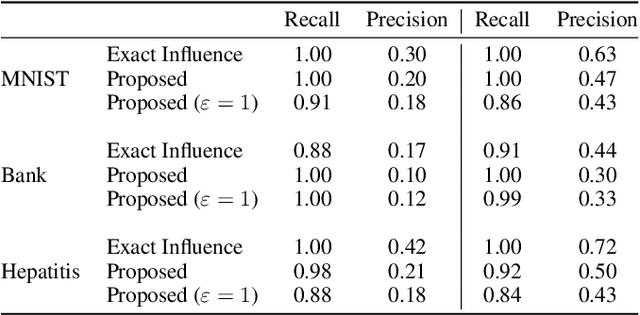
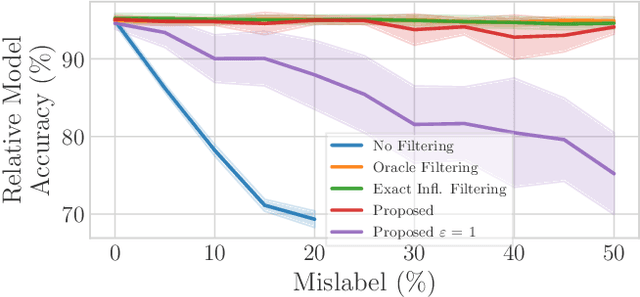
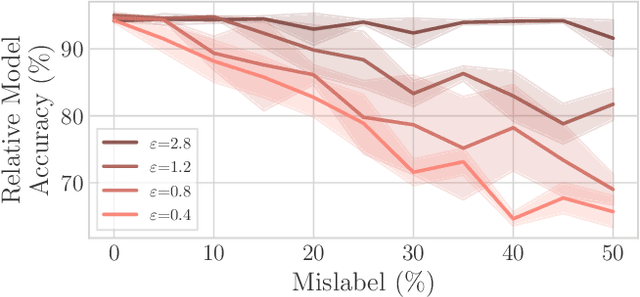
Federated Learning by nature is susceptible to low-quality, corrupted, or even malicious data that can severely degrade the quality of the learned model. Traditional techniques for data valuation cannot be applied as the data is never revealed. We present a novel technique for filtering, and scoring data based on a practical influence approximation that can be implemented in a privacy-preserving manner. Each agent uses his own data to evaluate the influence of another agent's batch, and reports to the center an obfuscated score using differential privacy. Our technique allows for almost perfect ($>92\%$ recall) filtering of corrupted data in a variety of applications using real-data. Importantly, the accuracy does not degrade significantly, even under really strong privacy guarantees ($\varepsilon \leq 1$), especially under realistic percentages of mislabeled data (for $15\%$ mislabeled data we only lose $10\%$ in accuracy).
Interlock-Free Multi-Aspect Rationalization for Text Classification
May 13, 2022
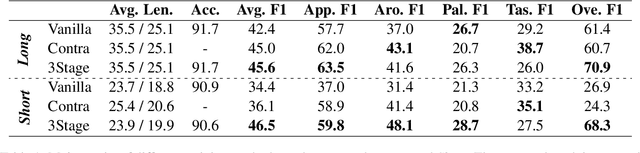
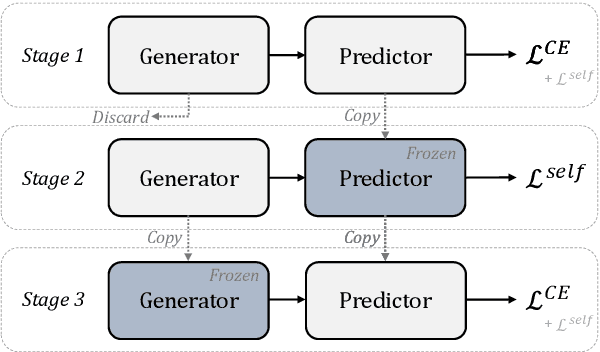
Explanation is important for text classification tasks. One prevalent type of explanation is rationales, which are text snippets of input text that suffice to yield the prediction and are meaningful to humans. A lot of research on rationalization has been based on the selective rationalization framework, which has recently been shown to be problematic due to the interlocking dynamics. In this paper, we show that we address the interlocking problem in the multi-aspect setting, where we aim to generate multiple rationales for multiple outputs. More specifically, we propose a multi-stage training method incorporating an additional self-supervised contrastive loss that helps to generate more semantically diverse rationales. Empirical results on the beer review dataset show that our method improves significantly the rationalization performance.
Assistive Recipe Editing through Critiquing
May 05, 2022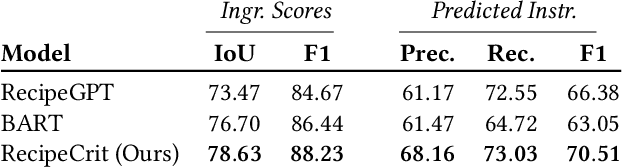
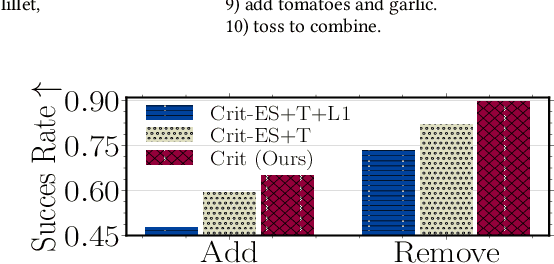


There has recently been growing interest in the automatic generation of cooking recipes that satisfy some form of dietary restrictions, thanks in part to the availability of online recipe data. Prior studies have used pre-trained language models, or relied on small paired recipe data (e.g., a recipe paired with a similar one that satisfies a dietary constraint). However, pre-trained language models generate inconsistent or incoherent recipes, and paired datasets are not available at scale. We address these deficiencies with RecipeCrit, a hierarchical denoising auto-encoder that edits recipes given ingredient-level critiques. The model is trained for recipe completion to learn semantic relationships within recipes. Our work's main innovation is our unsupervised critiquing module that allows users to edit recipes by interacting with the predicted ingredients; the system iteratively rewrites recipes to satisfy users' feedback. Experiments on the Recipe1M recipe dataset show that our model can more effectively edit recipes compared to strong language-modeling baselines, creating recipes that satisfy user constraints and are more correct, serendipitous, coherent, and relevant as measured by human judges.
Positive and Negative Critiquing for VAE-based Recommenders
Apr 05, 2022

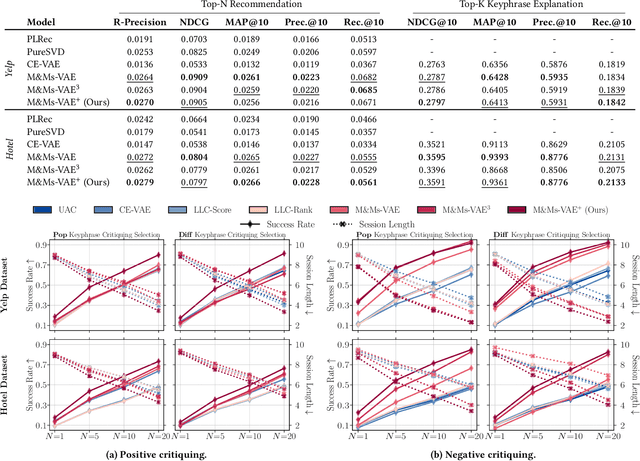
Providing explanations for recommended items allows users to refine the recommendations by critiquing parts of the explanations. As a result of revisiting critiquing from the perspective of multimodal generative models, recent work has proposed M&Ms-VAE, which achieves state-of-the-art performance in terms of recommendation, explanation, and critiquing. M&Ms-VAE and similar models allow users to negatively critique (i.e., explicitly disagree). However, they share a significant drawback: users cannot positively critique (i.e., highlight a desired feature). We address this deficiency with M&Ms-VAE+, an extension of M&Ms-VAE that enables positive and negative critiquing. In addition to modeling users' interactions and keyphrase-usage preferences, we model their keyphrase-usage dislikes. Moreover, we design a novel critiquing module that is trained in a self-supervised fashion. Our experiments on two datasets show that M&Ms-VAE+ matches or exceeds M&Ms-VAE in recommendation and explanation performance. Furthermore, our results demonstrate that representing positive and negative critiques differently enables M&Ms-VAE+ to significantly outperform M&Ms-VAE and other models in positive and negative multi-step critiquing.
Representation Memorization for Fast Learning New Knowledge without Forgetting
Sep 10, 2021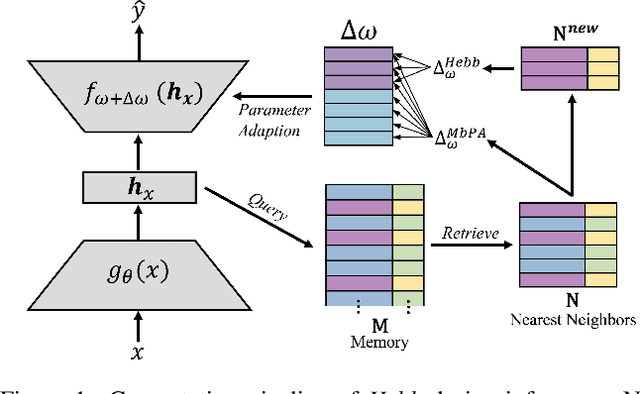
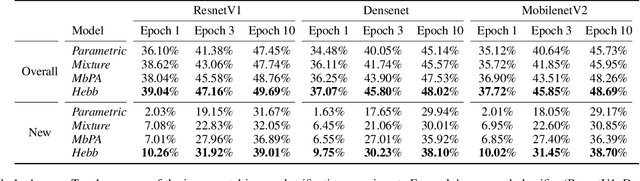
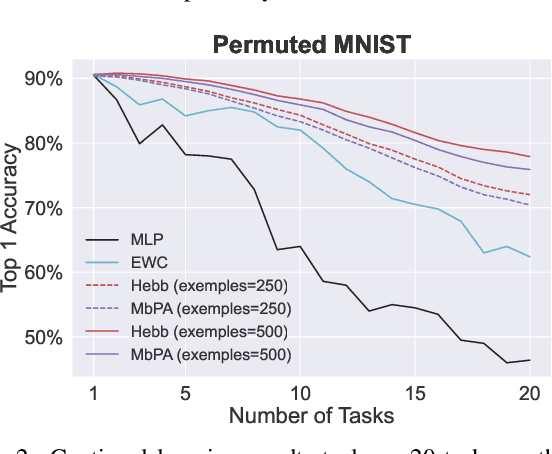
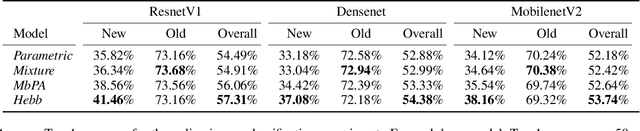
The ability to quickly learn new knowledge (e.g. new classes or data distributions) is a big step towards human-level intelligence. In this paper, we consider scenarios that require learning new classes or data distributions quickly and incrementally over time, as it often occurs in real-world dynamic environments. We propose "Memory-based Hebbian Parameter Adaptation" (Hebb) to tackle the two major challenges (i.e., catastrophic forgetting and sample efficiency) towards this goal in a unified framework. To mitigate catastrophic forgetting, Hebb augments a regular neural classifier with a continuously updated memory module to store representations of previous data. To improve sample efficiency, we propose a parameter adaptation method based on the well-known Hebbian theory, which directly "wires" the output network's parameters with similar representations retrieved from the memory. We empirically verify the superior performance of Hebb through extensive experiments on a wide range of learning tasks (image classification, language model) and learning scenarios (continual, incremental, online). We demonstrate that Hebb effectively mitigates catastrophic forgetting, and it indeed learns new knowledge better and faster than the current state-of-the-art.
Self-training Improves Pre-training for Few-shot Learning in Task-oriented Dialog Systems
Aug 28, 2021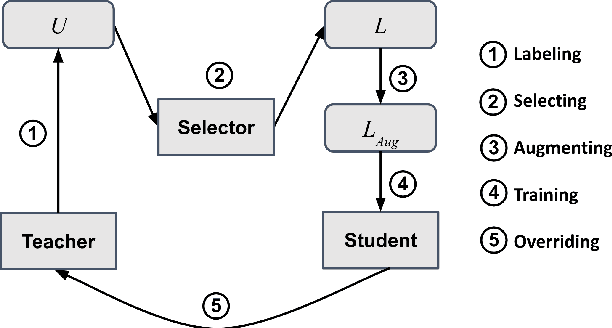
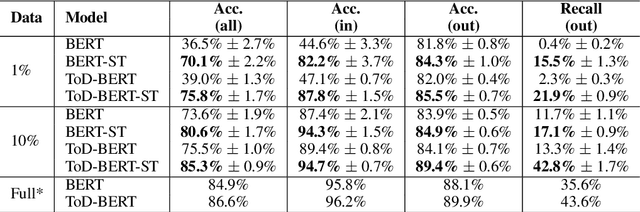
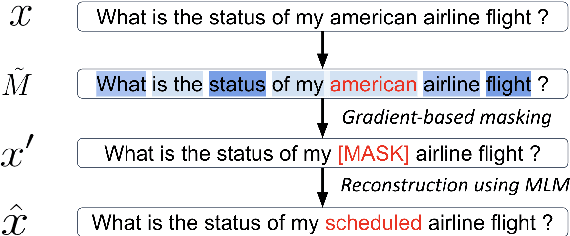
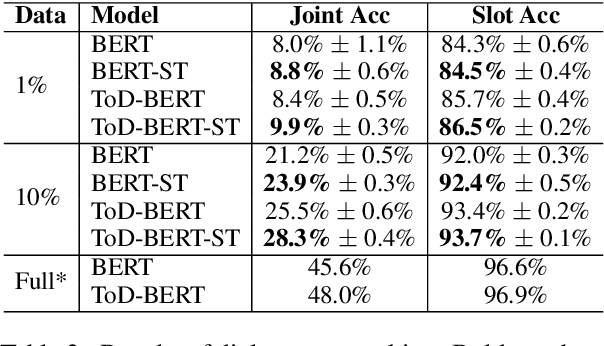
As the labeling cost for different modules in task-oriented dialog (ToD) systems is expensive, a major challenge is to train different modules with the least amount of labeled data. Recently, large-scale pre-trained language models, have shown promising results for few-shot learning in ToD. In this paper, we devise a self-training approach to utilize the abundant unlabeled dialog data to further improve state-of-the-art pre-trained models in few-shot learning scenarios for ToD systems. Specifically, we propose a self-training approach that iteratively labels the most confident unlabeled data to train a stronger Student model. Moreover, a new text augmentation technique (GradAug) is proposed to better train the Student by replacing non-crucial tokens using a masked language model. We conduct extensive experiments and present analyses on four downstream tasks in ToD, including intent classification, dialog state tracking, dialog act prediction, and response selection. Empirical results demonstrate that the proposed self-training approach consistently improves state-of-the-art pre-trained models (BERT, ToD-BERT) when only a small number of labeled data are available.