 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMete Ismayilzada
DiffuCOMET: Contextual Commonsense Knowledge Diffusion
Feb 26, 2024
Inferring contextually-relevant and diverse commonsense to understand narratives remains challenging for knowledge models. In this work, we develop a series of knowledge models, DiffuCOMET, that leverage diffusion to learn to reconstruct the implicit semantic connections between narrative contexts and relevant commonsense knowledge. Across multiple diffusion steps, our method progressively refines a representation of commonsense facts that is anchored to a narrative, producing contextually-relevant and diverse commonsense inferences for an input context. To evaluate DiffuCOMET, we introduce new metrics for commonsense inference that more closely measure knowledge diversity and contextual relevance. Our results on two different benchmarks, ComFact and WebNLG+, show that knowledge generated by DiffuCOMET achieves a better trade-off between commonsense diversity, contextual relevance and alignment to known gold references, compared to baseline knowledge models.
δ-CAUSAL: Exploring Defeasibility in Causal Reasoning
Jan 06, 2024Defeasibility in causal reasoning implies that the causal relationship between cause and effect can be strengthened or weakened. Namely, the causal strength between cause and effect should increase or decrease with the incorporation of strengthening arguments (supporters) or weakening arguments (defeaters), respectively. However, existing works ignore defeasibility in causal reasoning and fail to evaluate existing causal strength metrics in defeasible settings. In this work, we present {\delta}-CAUSAL, the first benchmark dataset for studying defeasibility in causal reasoning. {\delta}-CAUSAL includes around 11K events spanning ten domains, featuring defeasible causality pairs, i.e., cause-effect pairs accompanied by supporters and defeaters. We further show current causal strength metrics fail to reflect the change of causal strength with the incorporation of supporters or defeaters in {\delta}-CAUSAL. To this end, we propose CESAR (Causal Embedding aSsociation with Attention Rating), a metric that measures causal strength based on token-level causal relationships. CESAR achieves a significant 69.7% relative improvement over existing metrics, increasing from 47.2% to 80.1% in capturing the causal strength change brought by supporters and defeaters. We further demonstrate even Large Language Models (LLMs) like GPT-3.5 still lag 4.5 and 10.7 points behind humans in generating supporters and defeaters, emphasizing the challenge posed by {\delta}-CAUSAL.
CRoW: Benchmarking Commonsense Reasoning in Real-World Tasks
Oct 23, 2023Recent efforts in natural language processing (NLP) commonsense reasoning research have yielded a considerable number of new datasets and benchmarks. However, most of these datasets formulate commonsense reasoning challenges in artificial scenarios that are not reflective of the tasks which real-world NLP systems are designed to solve. In this work, we present CRoW, a manually-curated, multi-task benchmark that evaluates the ability of models to apply commonsense reasoning in the context of six real-world NLP tasks. CRoW is constructed using a multi-stage data collection pipeline that rewrites examples from existing datasets using commonsense-violating perturbations. We use CRoW to study how NLP systems perform across different dimensions of commonsense knowledge, such as physical, temporal, and social reasoning. We find a significant performance gap when NLP systems are evaluated on CRoW compared to humans, showcasing that commonsense reasoning is far from being solved in real-world task settings. We make our dataset and leaderboard available to the research community at https://github.com/mismayil/crow.
REFINER: Reasoning Feedback on Intermediate Representations
Apr 04, 2023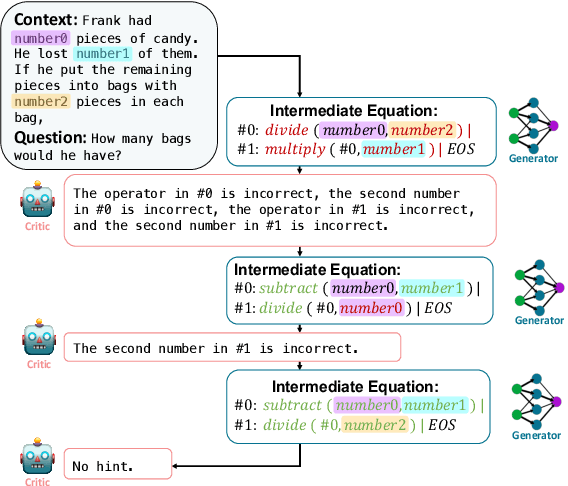
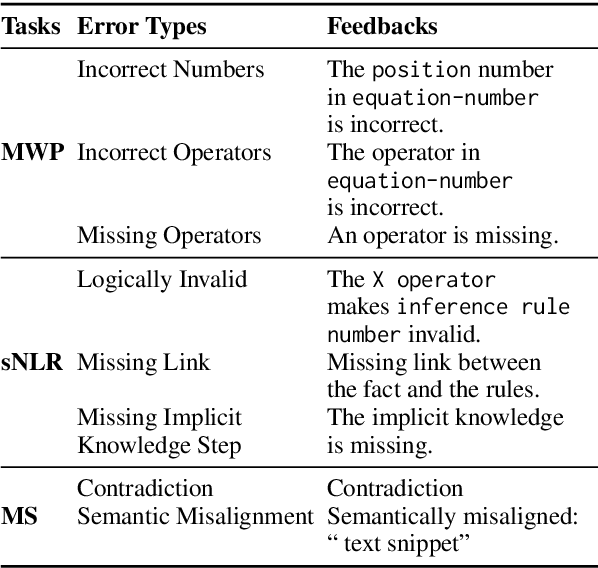
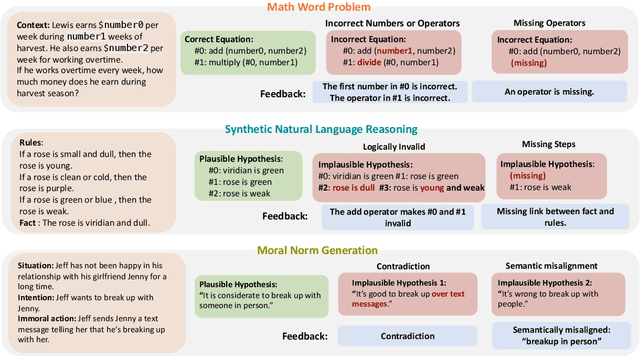
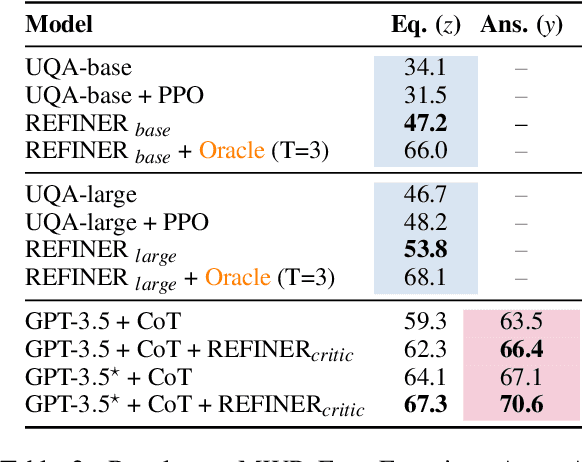
Language models (LMs) have recently shown remarkable performance on reasoning tasks by explicitly generating intermediate inferences, e.g., chain-of-thought prompting. However, these intermediate inference steps may be inappropriate deductions from the initial context and lead to incorrect final predictions. Here we introduce REFINER, a framework for finetuning LMs to explicitly generate intermediate reasoning steps while interacting with a critic model that provides automated feedback on the reasoning. Specifically, the critic provides structured feedback that the reasoning LM uses to iteratively improve its intermediate arguments. Empirical evaluations of REFINER on three diverse reasoning tasks show significant improvements over baseline LMs of comparable scale. Furthermore, when using GPT3.5 as the reasoner, the trained critic significantly improves reasoning without finetuning the reasoner. Finally, our critic model is trained without expensive human-in-the-loop data but can be substituted with humans at inference time.
kogito: A Commonsense Knowledge Inference Toolkit
Dec 06, 2022


In this paper, we present kogito, an open-source tool for generating commonsense inferences about situations described in text. kogito provides an intuitive and extensible interface to interact with natural language generation models that can be used for hypothesizing commonsense knowledge inference from a textual input. In particular, kogito offers several features for targeted, multi-granularity knowledge generation. These include a standardized API for training and evaluating knowledge models, and generating and filtering inferences from them. We also include helper functions for converting natural language texts into a format ingestible by knowledge models - intermediate pipeline stages such as knowledge head extraction from text, heuristic and model-based knowledge head-relation matching, and an ability to define and use custom knowledge relations. We make the code for kogito available at https://github.com/epfl-nlp/kogito along with thorough documentation at https://kogito.readthedocs.io.