 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRudra Murthy
Airavata: Introducing Hindi Instruction-tuned LLM
Jan 26, 2024
We announce the initial release of "Airavata," an instruction-tuned LLM for Hindi. Airavata was created by fine-tuning OpenHathi with diverse, instruction-tuning Hindi datasets to make it better suited for assistive tasks. Along with the model, we also share the IndicInstruct dataset, which is a collection of diverse instruction-tuning datasets to enable further research for Indic LLMs. Additionally, we present evaluation benchmarks and a framework for assessing LLM performance across tasks in Hindi. Currently, Airavata supports Hindi, but we plan to expand this to all 22 scheduled Indic languages. You can access all artifacts at https://ai4bharat.github.io/airavata.
PUB: A Pragmatics Understanding Benchmark for Assessing LLMs' Pragmatics Capabilities
Jan 13, 2024LLMs have demonstrated remarkable capability for understanding semantics, but they often struggle with understanding pragmatics. To demonstrate this fact, we release a Pragmatics Understanding Benchmark (PUB) dataset consisting of fourteen tasks in four pragmatics phenomena, namely, Implicature, Presupposition, Reference, and Deixis. We curated high-quality test sets for each task, consisting of Multiple Choice Question Answers (MCQA). PUB includes a total of 28k data points, 6.1k of which have been created by us, and the rest are adapted from existing datasets. We evaluated nine models varying in the number of parameters and type of training. Our study indicates that fine-tuning for instruction-following and chat significantly enhances the pragmatics capabilities of smaller language models. However, for larger models, the base versions perform comparably with their chat-adapted counterparts. Additionally, there is a noticeable performance gap between human capabilities and model capabilities. Furthermore, unlike the consistent performance of humans across various tasks, the models demonstrate variability in their proficiency, with performance levels fluctuating due to different hints and the complexities of tasks within the same dataset. Overall, the benchmark aims to provide a comprehensive evaluation of LLM's ability to handle real-world language tasks that require pragmatic reasoning.
StarCoder: may the source be with you!
May 09, 2023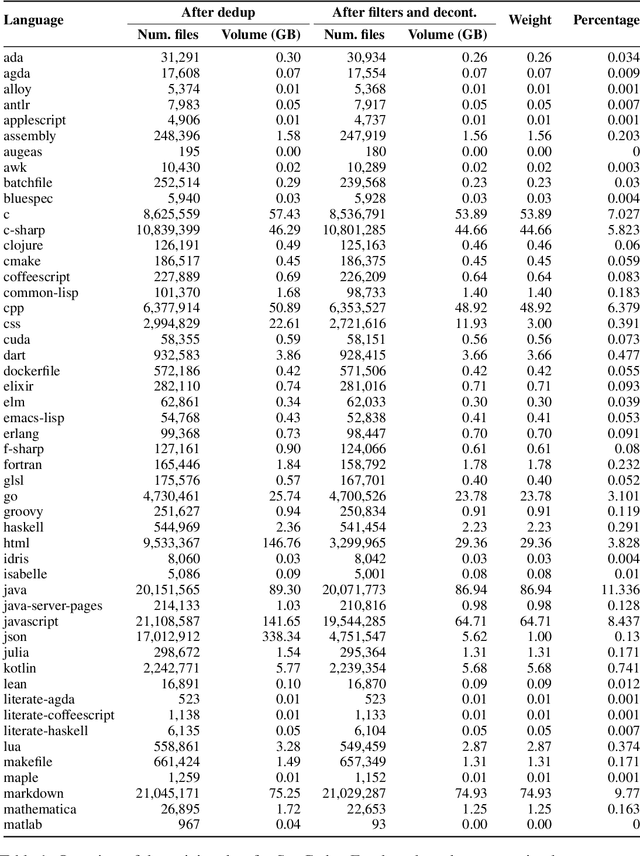
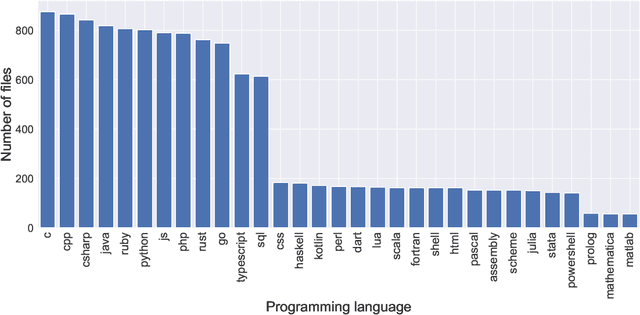

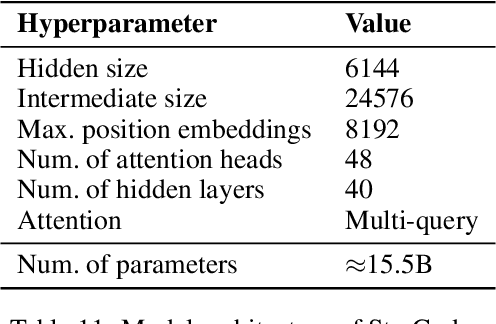
The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
HiNER: A Large Hindi Named Entity Recognition Dataset
Apr 28, 2022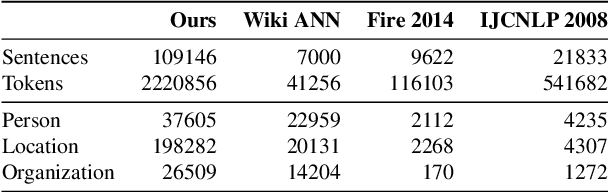
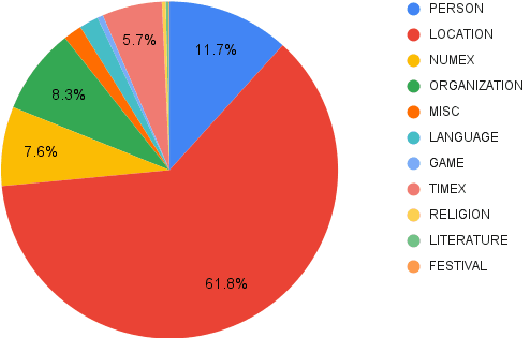
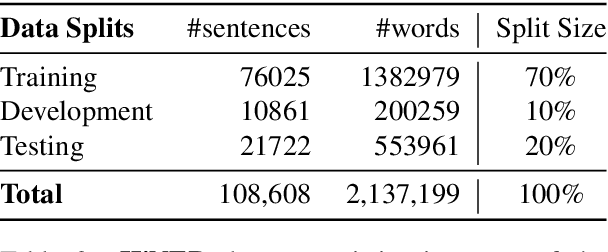
Named Entity Recognition (NER) is a foundational NLP task that aims to provide class labels like Person, Location, Organisation, Time, and Number to words in free text. Named Entities can also be multi-word expressions where the additional I-O-B annotation information helps label them during the NER annotation process. While English and European languages have considerable annotated data for the NER task, Indian languages lack on that front -- both in terms of quantity and following annotation standards. This paper releases a significantly sized standard-abiding Hindi NER dataset containing 109,146 sentences and 2,220,856 tokens, annotated with 11 tags. We discuss the dataset statistics in all their essential detail and provide an in-depth analysis of the NER tag-set used with our data. The statistics of tag-set in our dataset show a healthy per-tag distribution, especially for prominent classes like Person, Location and Organisation. Since the proof of resource-effectiveness is in building models with the resource and testing the model on benchmark data and against the leader-board entries in shared tasks, we do the same with the aforesaid data. We use different language models to perform the sequence labelling task for NER and show the efficacy of our data by performing a comparative evaluation with models trained on another dataset available for the Hindi NER task. Our dataset helps achieve a weighted F1 score of 88.78 with all the tags and 92.22 when we collapse the tag-set, as discussed in the paper. To the best of our knowledge, no available dataset meets the standards of volume (amount) and variability (diversity), as far as Hindi NER is concerned. We fill this gap through this work, which we hope will significantly help NLP for Hindi. We release this dataset with our code and models at https://github.com/cfiltnlp/HiNER
Cognitively Aided Zero-Shot Automatic Essay Grading
Feb 22, 2021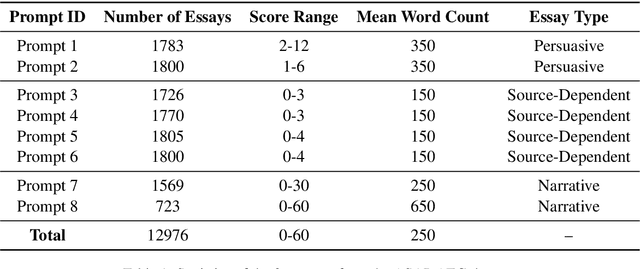
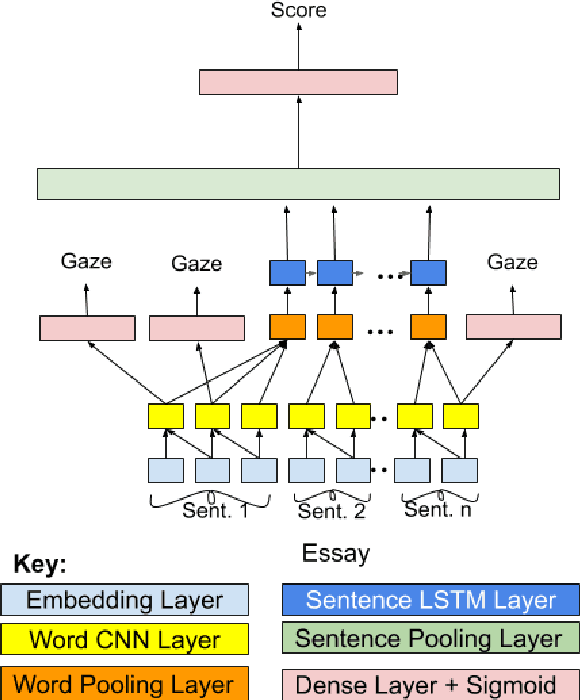
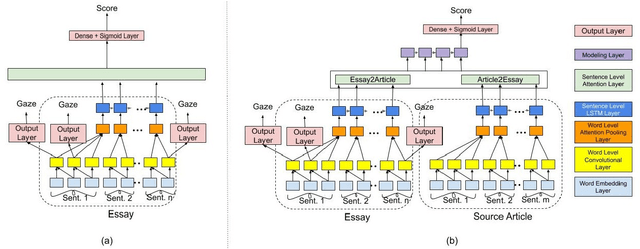
Automatic essay grading (AEG) is a process in which machines assign a grade to an essay written in response to a topic, called the prompt. Zero-shot AEG is when we train a system to grade essays written to a new prompt which was not present in our training data. In this paper, we describe a solution to the problem of zero-shot automatic essay grading, using cognitive information, in the form of gaze behaviour. Our experiments show that using gaze behaviour helps in improving the performance of AEG systems, especially when we provide a new essay written in response to a new prompt for scoring, by an average of almost 5 percentage points of QWK.
Happy Are Those Who Grade without Seeing: A Multi-Task Learning Approach to Grade Essays Using Gaze Behaviour
May 25, 2020


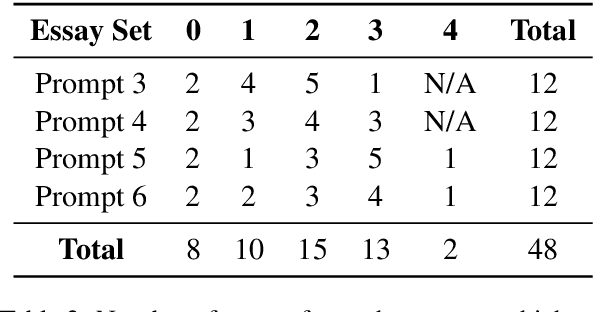
The gaze behaviour of a reader is helpful in solving several NLP tasks such as automatic essay grading, named entity recognition, sarcasm detection $\textit{etc.}$ However, collecting gaze behaviour from readers is costly in terms of time and money. In this paper, we propose a way to improve automatic essay grading using gaze behaviour, where the gaze features are learnt at run time using a multi-task learning framework. To demonstrate the efficacy of this multi-task learning based approach to automatic essay grading, we collect gaze behaviour for 48 essays across 4 essay sets, and learn gaze behaviour for the rest of the essays, numbering over 7000 essays. Using the learnt gaze behaviour, we can achieve a statistically significant improvement in performance over the state-of-the-art system for the essay sets where we have gaze data. We also achieve a statistically significant improvement for 4 other essay sets, numbering about 6000 essays, where we have no gaze behaviour data available. Our approach establishes that learning gaze behaviour improves automatic essay grading.