 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRufin VanRullen
Modality-Agnostic fMRI Decoding of Vision and Language
Mar 18, 2024




Previous studies have shown that it is possible to map brain activation data of subjects viewing images onto the feature representation space of not only vision models (modality-specific decoding) but also language models (cross-modal decoding). In this work, we introduce and use a new large-scale fMRI dataset (~8,500 trials per subject) of people watching both images and text descriptions of such images. This novel dataset enables the development of modality-agnostic decoders: a single decoder that can predict which stimulus a subject is seeing, irrespective of the modality (image or text) in which the stimulus is presented. We train and evaluate such decoders to map brain signals onto stimulus representations from a large range of publicly available vision, language and multimodal (vision+language) models. Our findings reveal that (1) modality-agnostic decoders perform as well as (and sometimes even better than) modality-specific decoders (2) modality-agnostic decoders mapping brain data onto representations from unimodal models perform as well as decoders relying on multimodal representations (3) while language and low-level visual (occipital) brain regions are best at decoding text and image stimuli, respectively, high-level visual (temporal) regions perform well on both stimulus types.
Zero-shot cross-modal transfer of Reinforcement Learning policies through a Global Workspace
Mar 07, 2024



Humans perceive the world through multiple senses, enabling them to create a comprehensive representation of their surroundings and to generalize information across domains. For instance, when a textual description of a scene is given, humans can mentally visualize it. In fields like robotics and Reinforcement Learning (RL), agents can also access information about the environment through multiple sensors; yet redundancy and complementarity between sensors is difficult to exploit as a source of robustness (e.g. against sensor failure) or generalization (e.g. transfer across domains). Prior research demonstrated that a robust and flexible multimodal representation can be efficiently constructed based on the cognitive science notion of a 'Global Workspace': a unique representation trained to combine information across modalities, and to broadcast its signal back to each modality. Here, we explore whether such a brain-inspired multimodal representation could be advantageous for RL agents. First, we train a 'Global Workspace' to exploit information collected about the environment via two input modalities (a visual input, or an attribute vector representing the state of the agent and/or its environment). Then, we train a RL agent policy using this frozen Global Workspace. In two distinct environments and tasks, our results reveal the model's ability to perform zero-shot cross-modal transfer between input modalities, i.e. to apply to image inputs a policy previously trained on attribute vectors (and vice-versa), without additional training or fine-tuning. Variants and ablations of the full Global Workspace (including a CLIP-like multimodal representation trained via contrastive learning) did not display the same generalization abilities.
Leveraging Self-Supervised Instance Contrastive Learning for Radar Object Detection
Feb 13, 2024In recent years, driven by the need for safer and more autonomous transport systems, the automotive industry has shifted toward integrating a growing number of Advanced Driver Assistance Systems (ADAS). Among the array of sensors employed for object recognition tasks, radar sensors have emerged as a formidable contender due to their abilities in adverse weather conditions or low-light scenarios and their robustness in maintaining consistent performance across diverse environments. However, the small size of radar datasets and the complexity of the labelling of those data limit the performance of radar object detectors. Driven by the promising results of self-supervised learning in computer vision, this paper presents RiCL, an instance contrastive learning framework to pre-train radar object detectors. We propose to exploit the detection from the radar and the temporal information to pre-train the radar object detection model in a self-supervised way using contrastive learning. We aim to pre-train an object detector's backbone, head and neck to learn with fewer data. Experiments on the CARRADA and the RADDet datasets show the effectiveness of our approach in learning generic representations of objects in range-Doppler maps. Notably, our pre-training strategy allows us to use only 20% of the labelled data to reach a similar mAP@0.5 than a supervised approach using the whole training set.
Consciousness in Artificial Intelligence: Insights from the Science of Consciousness
Aug 22, 2023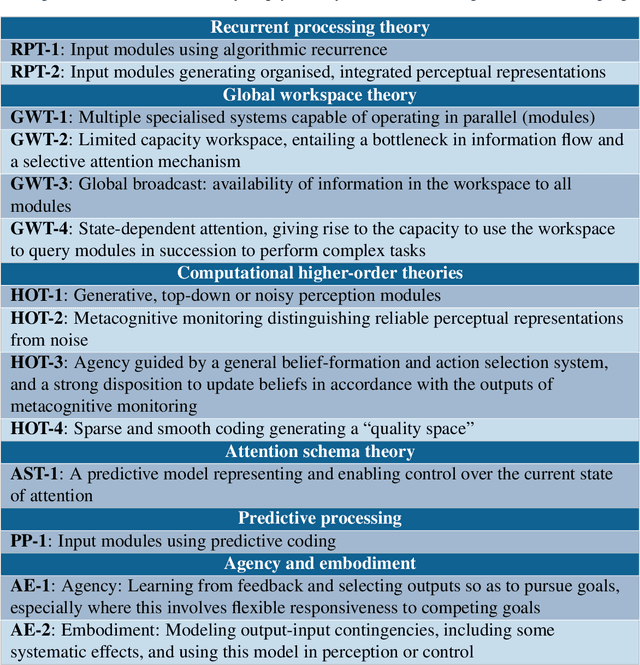


Whether current or near-term AI systems could be conscious is a topic of scientific interest and increasing public concern. This report argues for, and exemplifies, a rigorous and empirically grounded approach to AI consciousness: assessing existing AI systems in detail, in light of our best-supported neuroscientific theories of consciousness. We survey several prominent scientific theories of consciousness, including recurrent processing theory, global workspace theory, higher-order theories, predictive processing, and attention schema theory. From these theories we derive "indicator properties" of consciousness, elucidated in computational terms that allow us to assess AI systems for these properties. We use these indicator properties to assess several recent AI systems, and we discuss how future systems might implement them. Our analysis suggests that no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.
Gradient strikes back: How filtering out high frequencies improves explanations
Jul 18, 2023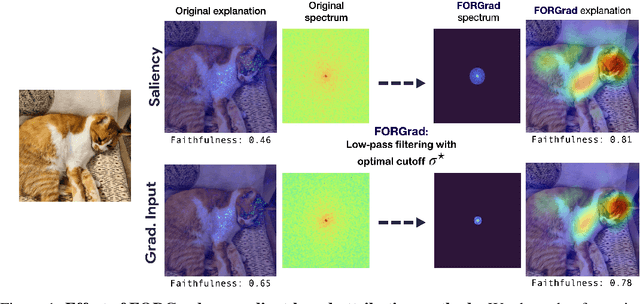

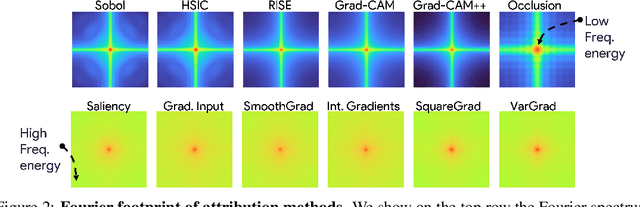

Recent years have witnessed an explosion in the development of novel prediction-based attribution methods, which have slowly been supplanting older gradient-based methods to explain the decisions of deep neural networks. However, it is still not clear why prediction-based methods outperform gradient-based ones. Here, we start with an empirical observation: these two approaches yield attribution maps with very different power spectra, with gradient-based methods revealing more high-frequency content than prediction-based methods. This observation raises multiple questions: What is the source of this high-frequency information, and does it truly reflect decisions made by the system? Lastly, why would the absence of high-frequency information in prediction-based methods yield better explainability scores along multiple metrics? We analyze the gradient of three representative visual classification models and observe that it contains noisy information emanating from high-frequencies. Furthermore, our analysis reveals that the operations used in Convolutional Neural Networks (CNNs) for downsampling appear to be a significant source of this high-frequency content -- suggesting aliasing as a possible underlying basis. We then apply an optimal low-pass filter for attribution maps and demonstrate that it improves gradient-based attribution methods. We show that (i) removing high-frequency noise yields significant improvements in the explainability scores obtained with gradient-based methods across multiple models -- leading to (ii) a novel ranking of state-of-the-art methods with gradient-based methods at the top. We believe that our results will spur renewed interest in simpler and computationally more efficient gradient-based methods for explainability.
Semi-supervised Multimodal Representation Learning through a Global Workspace
Jun 27, 2023



Recent deep learning models can efficiently combine inputs from different modalities (e.g., images and text) and learn to align their latent representations, or to translate signals from one domain to another (as in image captioning, or text-to-image generation). However, current approaches mainly rely on brute-force supervised training over large multimodal datasets. In contrast, humans (and other animals) can learn useful multimodal representations from only sparse experience with matched cross-modal data. Here we evaluate the capabilities of a neural network architecture inspired by the cognitive notion of a "Global Workspace": a shared representation for two (or more) input modalities. Each modality is processed by a specialized system (pretrained on unimodal data, and subsequently frozen). The corresponding latent representations are then encoded to and decoded from a single shared workspace. Importantly, this architecture is amenable to self-supervised training via cycle-consistency: encoding-decoding sequences should approximate the identity function. For various pairings of vision-language modalities and across two datasets of varying complexity, we show that such an architecture can be trained to align and translate between two modalities with very little need for matched data (from 4 to 7 times less than a fully supervised approach). The global workspace representation can be used advantageously for downstream classification tasks and for robust transfer learning. Ablation studies reveal that both the shared workspace and the self-supervised cycle-consistency training are critical to the system's performance.
Brain Captioning: Decoding human brain activity into images and text
May 19, 2023



Every day, the human brain processes an immense volume of visual information, relying on intricate neural mechanisms to perceive and interpret these stimuli. Recent breakthroughs in functional magnetic resonance imaging (fMRI) have enabled scientists to extract visual information from human brain activity patterns. In this study, we present an innovative method for decoding brain activity into meaningful images and captions, with a specific focus on brain captioning due to its enhanced flexibility as compared to brain decoding into images. Our approach takes advantage of cutting-edge image captioning models and incorporates a unique image reconstruction pipeline that utilizes latent diffusion models and depth estimation. We utilized the Natural Scenes Dataset, a comprehensive fMRI dataset from eight subjects who viewed images from the COCO dataset. We employed the Generative Image-to-text Transformer (GIT) as our backbone for captioning and propose a new image reconstruction pipeline based on latent diffusion models. The method involves training regularized linear regression models between brain activity and extracted features. Additionally, we incorporated depth maps from the ControlNet model to further guide the reconstruction process. We evaluate our methods using quantitative metrics for both generated captions and images. Our brain captioning approach outperforms existing methods, while our image reconstruction pipeline generates plausible images with improved spatial relationships. In conclusion, we demonstrate significant progress in brain decoding, showcasing the enormous potential of integrating vision and language to better understand human cognition. Our approach provides a flexible platform for future research, with potential applications in various fields, including neural art, style transfer, and portable devices.
Brain-Diffuser: Natural scene reconstruction from fMRI signals using generative latent diffusion
Mar 09, 2023



In neural decoding research, one of the most intriguing topics is the reconstruction of perceived natural images based on fMRI signals. Previous studies have succeeded in re-creating different aspects of the visuals, such as low-level properties (shape, texture, layout) or high-level features (category of objects, descriptive semantics of scenes) but have typically failed to reconstruct these properties together for complex scene images. Generative AI has recently made a leap forward with latent diffusion models capable of generating high-complexity images. Here, we investigate how to take advantage of this innovative technology for brain decoding. We present a two-stage scene reconstruction framework called ``Brain-Diffuser''. In the first stage, starting from fMRI signals, we reconstruct images that capture low-level properties and overall layout using a VDVAE (Very Deep Variational Autoencoder) model. In the second stage, we use the image-to-image framework of a latent diffusion model (Versatile Diffusion) conditioned on predicted multimodal (text and visual) features, to generate final reconstructed images. On the publicly available Natural Scenes Dataset benchmark, our method outperforms previous models both qualitatively and quantitatively. When applied to synthetic fMRI patterns generated from individual ROI (region-of-interest) masks, our trained model creates compelling ``ROI-optimal'' scenes consistent with neuroscientific knowledge. Thus, the proposed methodology can have an impact on both applied (e.g. brain-computer interface) and fundamental neuroscience.
Learning Functional Transduction
Feb 01, 2023



Research in Machine Learning has polarized into two general regression approaches: Transductive methods derive estimates directly from available data but are usually problem unspecific. Inductive methods can be much more particular, but generally require tuning and compute-intensive searches for solutions. In this work, we adopt a hybrid approach: We leverage the theory of Reproducing Kernel Banach Spaces (RKBS) and show that transductive principles can be induced through gradient descent to form efficient \textit{in-context} neural approximators. We apply this approach to RKBS of function-valued operators and show that once trained, our \textit{Transducer} model can capture on-the-fly relationships between infinite-dimensional input and output functions, given a few example pairs, and return new function estimates. We demonstrate the benefit of our transductive approach to model complex physical systems influenced by varying external factors with little data at a fraction of the usual deep learning training computation cost for partial differential equations and climate modeling applications.
A recurrent CNN for online object detection on raw radar frames
Dec 21, 2022



Automotive radar sensors provide valuable information for advanced driving assistance systems (ADAS). Radars can reliably estimate the distance to an object and the relative velocity, regardless of weather and light conditions. However, radar sensors suffer from low resolution and huge intra-class variations in the shape of objects. Exploiting the time information (e.g., multiple frames) has been shown to help to capture better the dynamics of objects and, therefore, the variation in the shape of objects. Most temporal radar object detectors use 3D convolutions to learn spatial and temporal information. However, these methods are often non-causal and unsuitable for real-time applications. This work presents RECORD, a new recurrent CNN architecture for online radar object detection. We propose an end-to-end trainable architecture mixing convolutions and ConvLSTMs to learn spatio-temporal dependencies between successive frames. Our model is causal and requires only the past information encoded in the memory of the ConvLSTMs to detect objects. Our experiments show such a method's relevance for detecting objects in different radar representations (range-Doppler, range-angle) and outperform state-of-the-art models on the ROD2021 and CARRADA datasets while being less computationally expensive. The code will be available soon.