 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRuinan Jin
Universal Debiased Editing on Foundation Models for Fair Medical Image Classification
Mar 16, 2024
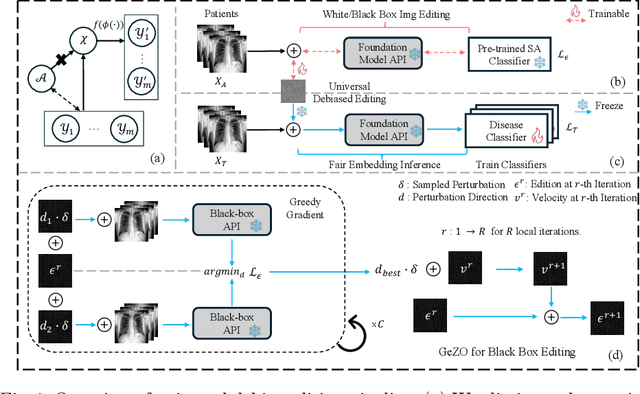
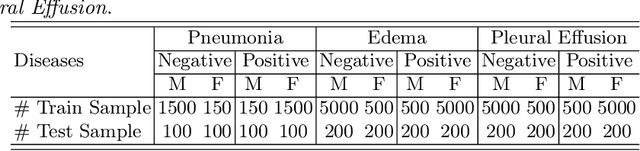
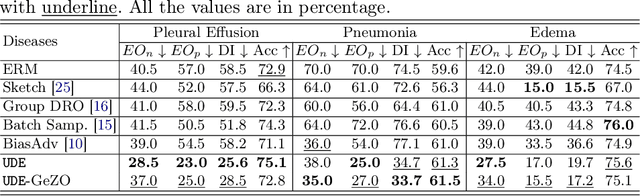
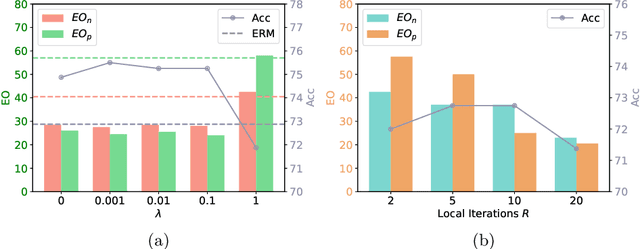
In the era of Foundation Models' (FMs) rising prominence in AI, our study addresses the challenge of biases in medical images while using FM API, particularly spurious correlations between pixels and sensitive attributes. Traditional methods for bias mitigation face limitations due to the restricted access to web-hosted FMs and difficulties in addressing the underlying bias encoded within the FM API. We propose an U(niversal) D(ebiased) E(diting) strategy, termed UDE, which generates UDE noise to mask such spurious correlation. UDE is capable of mitigating bias both within the FM API embedding and the images themselves. Furthermore, UDE is suitable for both white-box and black-box FM APIs, where we introduced G(reedy) (Z)eroth-O(rder) (GeZO) optimization for it when the gradient is inaccessible in black-box APIs. Our whole pipeline enables fairness-aware image editing that can be applied across various medical contexts without requiring direct model manipulation or significant computational resources. Our empirical results demonstrate the method's effectiveness in maintaining fairness and utility across different patient groups and diseases. In the era of AI-driven medicine, this work contributes to making healthcare diagnostics more equitable, showcasing a practical solution for bias mitigation in pre-trained image FMs.
Backdoor Attack on Unpaired Medical Image-Text Foundation Models: A Pilot Study on MedCLIP
Jan 01, 2024In recent years, foundation models (FMs) have solidified their role as cornerstone advancements in the deep learning domain. By extracting intricate patterns from vast datasets, these models consistently achieve state-of-the-art results across a spectrum of downstream tasks, all without necessitating extensive computational resources. Notably, MedCLIP, a vision-language contrastive learning-based medical FM, has been designed using unpaired image-text training. While the medical domain has often adopted unpaired training to amplify data, the exploration of potential security concerns linked to this approach hasn't kept pace with its practical usage. Notably, the augmentation capabilities inherent in unpaired training also indicate that minor label discrepancies can result in significant model deviations. In this study, we frame this label discrepancy as a backdoor attack problem. We further analyze its impact on medical FMs throughout the FM supply chain. Our evaluation primarily revolves around MedCLIP, emblematic of medical FM employing the unpaired strategy. We begin with an exploration of vulnerabilities in MedCLIP stemming from unpaired image-text matching, termed BadMatch. BadMatch is achieved using a modest set of wrongly labeled data. Subsequently, we disrupt MedCLIP's contrastive learning through BadDist-assisted BadMatch by introducing a Bad-Distance between the embeddings of clean and poisoned data. Additionally, combined with BadMatch and BadDist, the attacking pipeline consistently fends off backdoor assaults across diverse model designs, datasets, and triggers. Also, our findings reveal that current defense strategies are insufficient in detecting these latent threats in medical FMs' supply chains.
Forgettable Federated Linear Learning with Certified Data Removal
Jun 03, 2023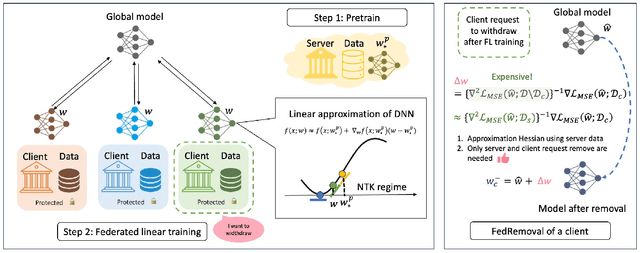
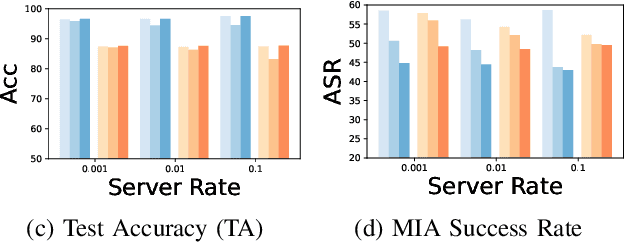
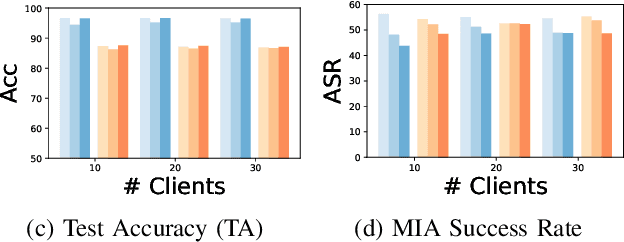
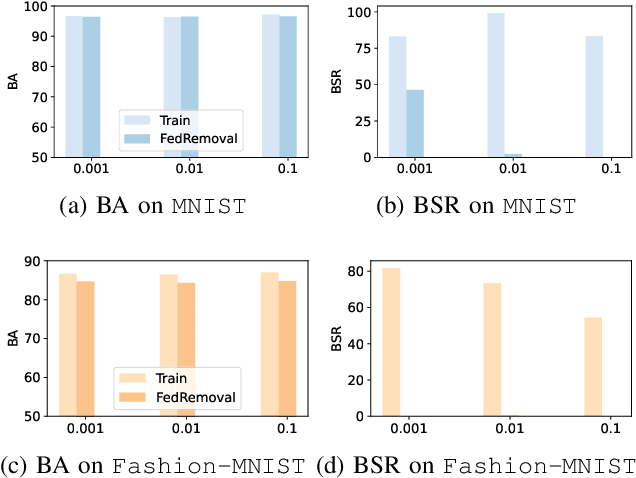
Federated learning (FL) is a trending distributed learning framework that enables collaborative model training without data sharing. Machine learning models trained on datasets can potentially expose the private information of the training data, revealing details about individual data records. In this study, we focus on the FL paradigm that grants clients the ``right to be forgotten''. The forgettable FL framework should bleach its global model weights as it has never seen that client and hence does not reveal any information about the client. To this end, we propose the Forgettable Federated Linear Learning (2F2L) framework featured with novel training and data removal strategies. The training pipeline, named Federated linear training, employs linear approximation on the model parameter space to enable our 2F2L framework work for deep neural networks while achieving comparable results with canonical neural network training. We also introduce FedRemoval, an efficient and effective removal strategy that tackles the computational challenges in FL by approximating the Hessian matrix using public server data from the pretrained model. Unlike the previous uncertified and heuristic machine unlearning methods in FL, we provide theoretical guarantees by bounding the differences of model weights by our FedRemoval and that from retraining from scratch. Experimental results on MNIST and Fashion-MNIST datasets demonstrate the effectiveness of our method in achieving a balance between model accuracy and information removal, outperforming baseline strategies and approaching retraining from scratch.
Federated Virtual Learning on Heterogeneous Data with Local-global Distillation
Mar 04, 2023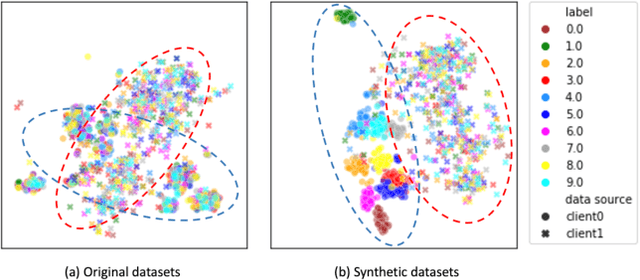
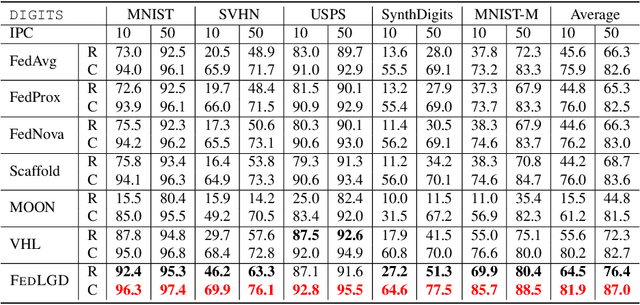
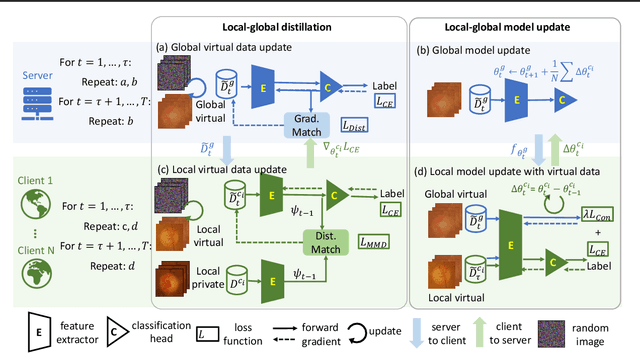

Despite Federated Learning (FL)'s trend for learning machine learning models in a distributed manner, it is susceptible to performance drops when training on heterogeneous data. Recently, dataset distillation has been explored in order to improve the efficiency and scalability of FL by creating a smaller, synthetic dataset that retains the performance of a model trained on the local private datasets. We discover that using distilled local datasets can amplify the heterogeneity issue in FL. To address this, we propose a new method, called Federated Virtual Learning on Heterogeneous Data with Local-Global Distillation (FEDLGD), which trains FL using a smaller synthetic dataset (referred as virtual data) created through a combination of local and global distillation. Specifically, to handle synchronization and class imbalance, we propose iterative distribution matching to allow clients to have the same amount of balanced local virtual data; to harmonize the domain shifts, we use federated gradient matching to distill global virtual data that are shared with clients without hindering data privacy to rectify heterogeneous local training via enforcing local-global feature similarity. We experiment on both benchmark and real-world datasets that contain heterogeneous data from different sources. Our method outperforms state-of-the-art heterogeneous FL algorithms under the setting with a very limited amount of distilled virtual data.
Backdoor Attack and Defense in Federated Generative Adversarial Network-based Medical Image Synthesis
Oct 19, 2022

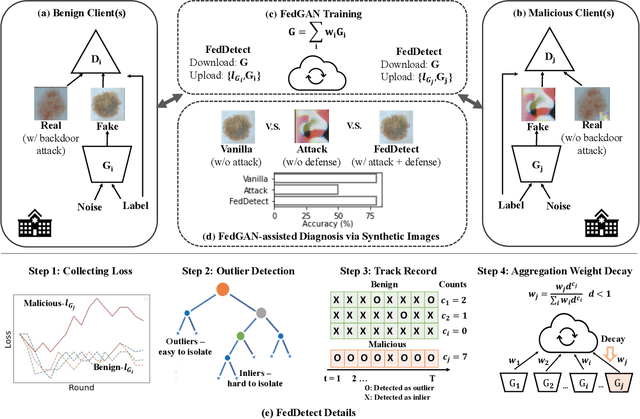
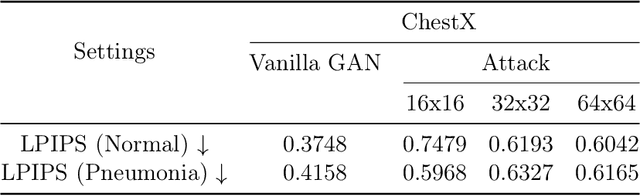
Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research and augment medical datasets. Training generative adversarial neural networks (GANs) usually require large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data while keeping raw data locally. However, given that the FL server cannot access the raw data, it is vulnerable to backdoor attacks, an adversarial by poisoning training data. Most backdoor attack strategies focus on classification models and centralized domains. It is still an open question if the existing backdoor attacks can affect GAN training and, if so, how to defend against the attack in the FL setting. In this work, we investigate the overlooked issue of backdoor attacks in federated GANs (FedGANs). The success of this attack is subsequently determined to be the result of some local discriminators overfitting the poisoned data and corrupting the local GAN equilibrium, which then further contaminates other clients when averaging the generator's parameters and yields high generator loss. Therefore, we proposed FedDetect, an efficient and effective way of defending against the backdoor attack in the FL setting, which allows the server to detect the client's adversarial behavior based on their losses and block the malicious clients. Our extensive experiments on two medical datasets with different modalities demonstrate the backdoor attack on FedGANs can result in synthetic images with low fidelity. After detecting and suppressing the detected malicious clients using the proposed defense strategy, we show that FedGANs can synthesize high-quality medical datasets (with labels) for data augmentation to improve classification models' performance.
Backdoor Attack is A Devil in Federated GAN-based Medical Image Synthesis
Jul 02, 2022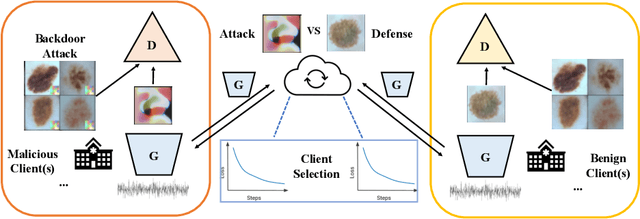
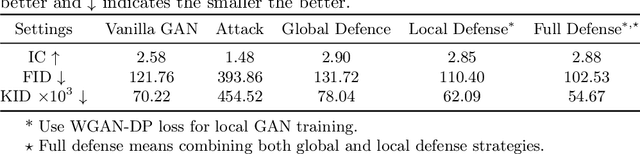
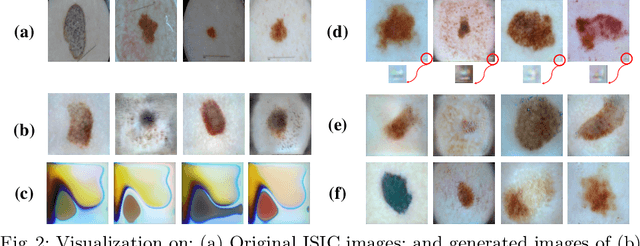
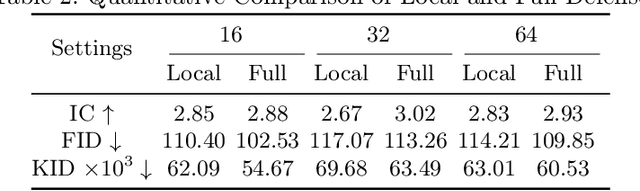
Deep Learning-based image synthesis techniques have been applied in healthcare research for generating medical images to support open research. Training generative adversarial neural networks (GAN) usually requires large amounts of training data. Federated learning (FL) provides a way of training a central model using distributed data from different medical institutions while keeping raw data locally. However, FL is vulnerable to backdoor attack, an adversarial by poisoning training data, given the central server cannot access the original data directly. Most backdoor attack strategies focus on classification models and centralized domains. In this study, we propose a way of attacking federated GAN (FedGAN) by treating the discriminator with a commonly used data poisoning strategy in backdoor attack classification models. We demonstrate that adding a small trigger with size less than 0.5 percent of the original image size can corrupt the FL-GAN model. Based on the proposed attack, we provide two effective defense strategies: global malicious detection and local training regularization. We show that combining the two defense strategies yields a robust medical image generation.
On the Convergence of mSGD and AdaGrad for Stochastic Optimization
Jan 26, 2022As one of the most fundamental stochastic optimization algorithms, stochastic gradient descent (SGD) has been intensively developed and extensively applied in machine learning in the past decade. There have been some modified SGD-type algorithms, which outperform the SGD in many competitions and applications in terms of convergence rate and accuracy, such as momentum-based SGD (mSGD) and adaptive gradient algorithm (AdaGrad). Despite these empirical successes, the theoretical properties of these algorithms have not been well established due to technical difficulties. With this motivation, we focus on convergence analysis of mSGD and AdaGrad for any smooth (possibly non-convex) loss functions in stochastic optimization. First, we prove that the iterates of mSGD are asymptotically convergent to a connected set of stationary points with probability one, which is more general than existing works on subsequence convergence or convergence of time averages. Moreover, we prove that the loss function of mSGD decays at a certain rate faster than that of SGD. In addition, we prove the iterates of AdaGrad are asymptotically convergent to a connected set of stationary points with probability one. Also, this result extends the results from the literature on subsequence convergence and the convergence of time averages. Despite the generality of the above convergence results, we have relaxed some assumptions of gradient noises, convexity of loss functions, as well as boundedness of iterates.
PURE: Passive mUlti-peRson idEntification via Deep Footstep Separation and Recognition
Apr 15, 2021
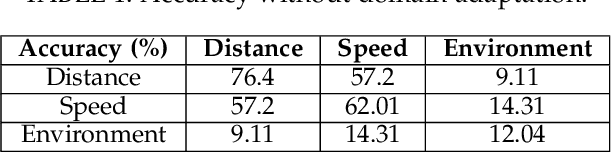


Recently, \textit{passive behavioral biometrics} (e.g., gesture or footstep) have become promising complements to conventional user identification methods (e.g., face or fingerprint) under special situations, yet existing sensing technologies require lengthy measurement traces and cannot identify multiple users at the same time. To this end, we propose \systemname\ as a passive multi-person identification system leveraging deep learning enabled footstep separation and recognition. \systemname\ passively identifies a user by deciphering the unique "footprints" in its footstep. Different from existing gait-enabled recognition systems incurring a long sensing delay to acquire many footsteps, \systemname\ can recognize a person by as few as only one step, substantially cutting the identification latency. To make \systemname\ adaptive to walking pace variations, environmental dynamics, and even unseen targets, we apply an adversarial learning technique to improve its domain generalisability and identification accuracy. Finally, \systemname\ can defend itself against replay attack, enabled by the richness of footstep and spatial awareness. We implement a \systemname\ prototype using commodity hardware and evaluate it in typical indoor settings. Evaluation results demonstrate a cross-domain identification accuracy of over 90\%.