 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRunkai Zhao
Boosting 3D Neuron Segmentation with 2D Vision Transformer Pre-trained on Natural Images
May 04, 2024
Neuron reconstruction, one of the fundamental tasks in neuroscience, rebuilds neuronal morphology from 3D light microscope imaging data. It plays a critical role in analyzing the structure-function relationship of neurons in the nervous system. However, due to the scarcity of neuron datasets and high-quality SWC annotations, it is still challenging to develop robust segmentation methods for single neuron reconstruction. To address this limitation, we aim to distill the consensus knowledge from massive natural image data to aid the segmentation model in learning the complex neuron structures. Specifically, in this work, we propose a novel training paradigm that leverages a 2D Vision Transformer model pre-trained on large-scale natural images to initialize our Transformer-based 3D neuron segmentation model with a tailored 2D-to-3D weight transferring strategy. Our method builds a knowledge sharing connection between the abundant natural and the scarce neuron image domains to improve the 3D neuron segmentation ability in a data-efficiency manner. Evaluated on a popular benchmark, BigNeuron, our method enhances neuron segmentation performance by 8.71% over the model trained from scratch with the same amount of training samples.
Advancements in 3D Lane Detection Using LiDAR Point Clouds: From Data Collection to Model Development
Sep 24, 2023
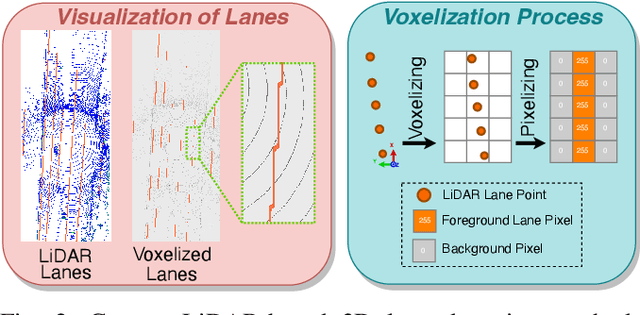
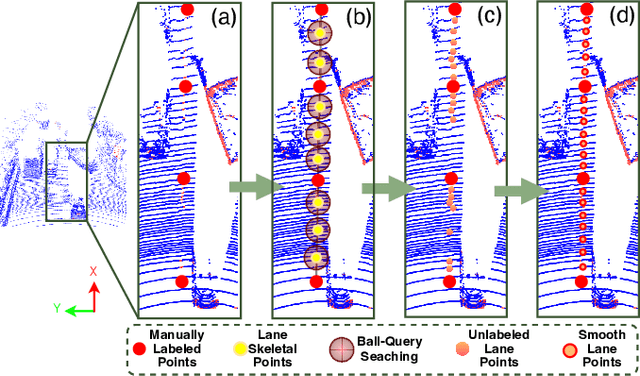
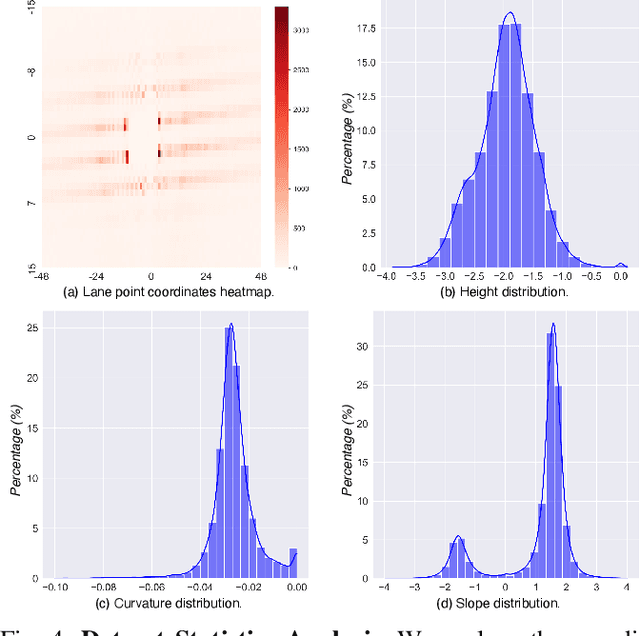
Advanced Driver-Assistance Systems (ADAS) have successfully integrated learning-based techniques into vehicle perception and decision-making. However, their application in 3D lane detection for effective driving environment perception is hindered by the lack of comprehensive LiDAR datasets. The sparse nature of LiDAR point cloud data prevents an efficient manual annotation process. To solve this problem, we present LiSV-3DLane, a large-scale 3D lane dataset that comprises 20k frames of surround-view LiDAR point clouds with enriched semantic annotation. Unlike existing datasets confined to a frontal perspective, LiSV-3DLane provides a full 360-degree spatial panorama around the ego vehicle, capturing complex lane patterns in both urban and highway environments. We leverage the geometric traits of lane lines and the intrinsic spatial attributes of LiDAR data to design a simple yet effective automatic annotation pipeline for generating finer lane labels. To propel future research, we propose a novel LiDAR-based 3D lane detection model, LiLaDet, incorporating the spatial geometry learning of the LiDAR point cloud into Bird's Eye View (BEV) based lane identification. Experimental results indicate that LiLaDet outperforms existing camera- and LiDAR-based approaches in the 3D lane detection task on the K-Lane dataset and our LiSV-3DLane.
PointNeuron: 3D Neuron Reconstruction via Geometry and Topology Learning of Point Clouds
Oct 18, 2022
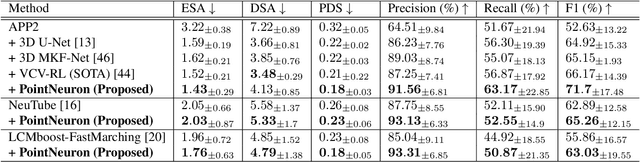
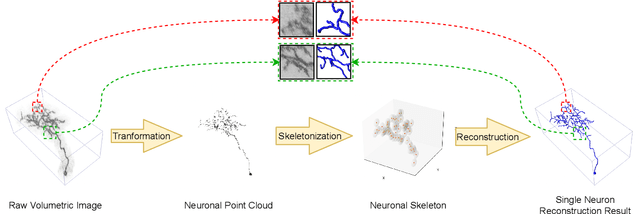

Digital neuron reconstruction from 3D microscopy images is an essential technique for investigating brain connectomics and neuron morphology. Existing reconstruction frameworks use convolution-based segmentation networks to partition the neuron from noisy backgrounds before applying the tracing algorithm. The tracing results are sensitive to the raw image quality and segmentation accuracy. In this paper, we propose a novel framework for 3D neuron reconstruction. Our key idea is to use the geometric representation power of the point cloud to better explore the intrinsic structural information of neurons. Our proposed framework adopts one graph convolutional network to predict the neural skeleton points and another one to produce the connectivity of these points. We finally generate the target SWC file through the interpretation of the predicted point coordinates, radius, and connections. Evaluated on the Janelia-Fly dataset from the BigNeuron project, we show that our framework achieves competitive neuron reconstruction performance. Our geometry and topology learning of point clouds could further benefit 3D medical image analysis, such as cardiac surface reconstruction. Our code is available at https://github.com/RunkaiZhao/PointNeuron.