 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRyosuke Yamada
Primitive Geometry Segment Pre-training for 3D Medical Image Segmentation
Jan 08, 2024
The construction of 3D medical image datasets presents several issues, including requiring significant financial costs in data collection and specialized expertise for annotation, as well as strict privacy concerns for patient confidentiality compared to natural image datasets. Therefore, it has become a pressing issue in 3D medical image segmentation to enable data-efficient learning with limited 3D medical data and supervision. A promising approach is pre-training, but improving its performance in 3D medical image segmentation is difficult due to the small size of existing 3D medical image datasets. We thus present the Primitive Geometry Segment Pre-training (PrimGeoSeg) method to enable the learning of 3D semantic features by pre-training segmentation tasks using only primitive geometric objects for 3D medical image segmentation. PrimGeoSeg performs more accurate and efficient 3D medical image segmentation without manual data collection and annotation. Further, experimental results show that PrimGeoSeg on SwinUNETR improves performance over learning from scratch on BTCV, MSD (Task06), and BraTS datasets by 3.7%, 4.4%, and 0.3%, respectively. Remarkably, the performance was equal to or better than state-of-the-art self-supervised learning despite the equal number of pre-training data. From experimental results, we conclude that effective pre-training can be achieved by looking at primitive geometric objects only. Code and dataset are available at https://github.com/SUPER-TADORY/PrimGeoSeg.
Replacing Labeled Real-image Datasets with Auto-generated Contours
Jun 18, 2022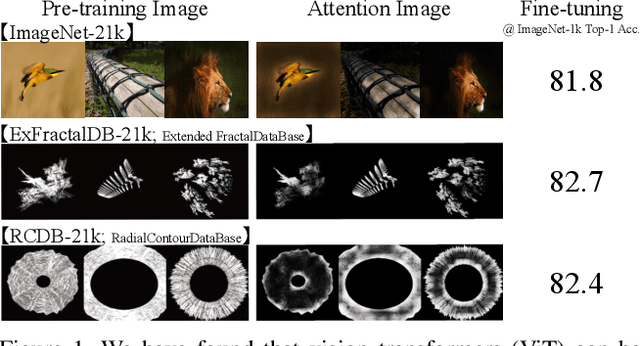
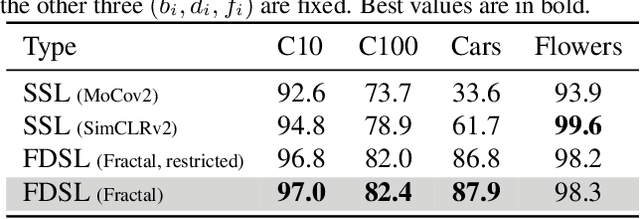

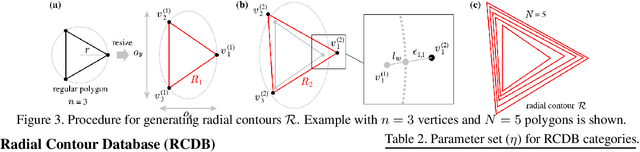
In the present work, we show that the performance of formula-driven supervised learning (FDSL) can match or even exceed that of ImageNet-21k without the use of real images, human-, and self-supervision during the pre-training of Vision Transformers (ViTs). For example, ViT-Base pre-trained on ImageNet-21k shows 81.8% top-1 accuracy when fine-tuned on ImageNet-1k and FDSL shows 82.7% top-1 accuracy when pre-trained under the same conditions (number of images, hyperparameters, and number of epochs). Images generated by formulas avoid the privacy/copyright issues, labeling cost and errors, and biases that real images suffer from, and thus have tremendous potential for pre-training general models. To understand the performance of the synthetic images, we tested two hypotheses, namely (i) object contours are what matter in FDSL datasets and (ii) increased number of parameters to create labels affects performance improvement in FDSL pre-training. To test the former hypothesis, we constructed a dataset that consisted of simple object contour combinations. We found that this dataset can match the performance of fractals. For the latter hypothesis, we found that increasing the difficulty of the pre-training task generally leads to better fine-tuning accuracy.
Pre-training without Natural Images
Jan 21, 2021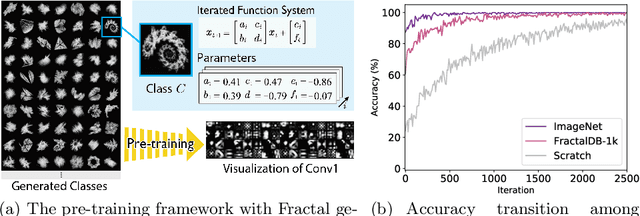
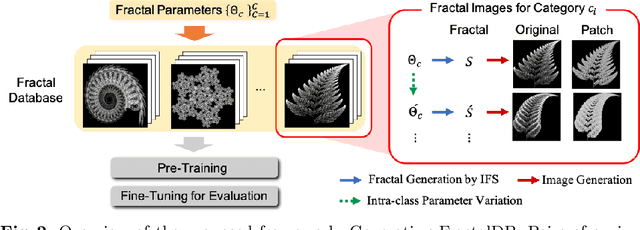

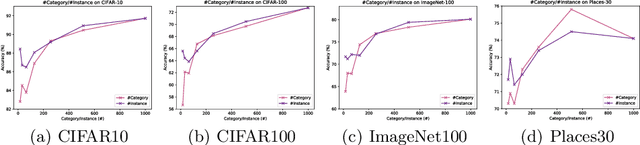
Is it possible to use convolutional neural networks pre-trained without any natural images to assist natural image understanding? The paper proposes a novel concept, Formula-driven Supervised Learning. We automatically generate image patterns and their category labels by assigning fractals, which are based on a natural law existing in the background knowledge of the real world. Theoretically, the use of automatically generated images instead of natural images in the pre-training phase allows us to generate an infinite scale dataset of labeled images. Although the models pre-trained with the proposed Fractal DataBase (FractalDB), a database without natural images, does not necessarily outperform models pre-trained with human annotated datasets at all settings, we are able to partially surpass the accuracy of ImageNet/Places pre-trained models. The image representation with the proposed FractalDB captures a unique feature in the visualization of convolutional layers and attentions.