 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSajal K. Das
Using Geographic Location-based Public Health Features in Survival Analysis
Apr 16, 2023
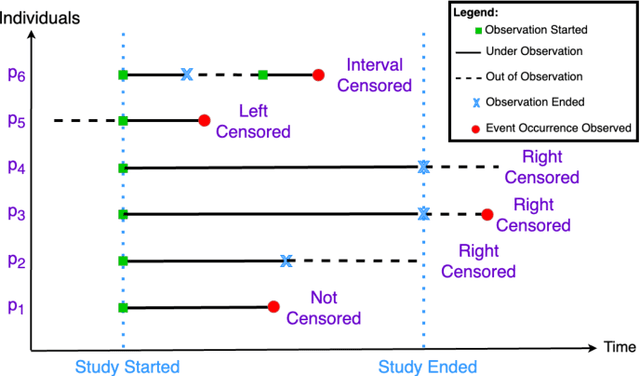

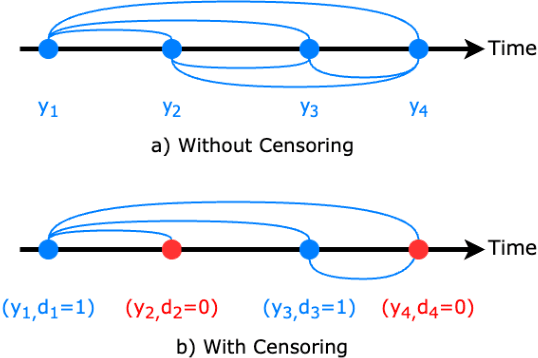
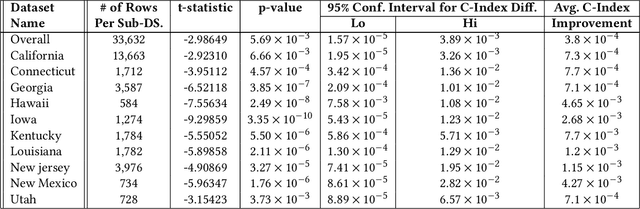
Time elapsed till an event of interest is often modeled using the survival analysis methodology, which estimates a survival score based on the input features. There is a resurgence of interest in developing more accurate prediction models for time-to-event prediction in personalized healthcare using modern tools such as neural networks. Higher quality features and more frequent observations improve the predictions for a patient, however, the impact of including a patient's geographic location-based public health statistics on individual predictions has not been studied. This paper proposes a complementary improvement to survival analysis models by incorporating public health statistics in the input features. We show that including geographic location-based public health information results in a statistically significant improvement in the concordance index evaluated on the Surveillance, Epidemiology, and End Results (SEER) dataset containing nationwide cancer incidence data. The improvement holds for both the standard Cox proportional hazards model and the state-of-the-art Deep Survival Machines model. Our results indicate the utility of geographic location-based public health features in survival analysis.
Securing Federated Learning against Overwhelming Collusive Attackers
Sep 28, 2022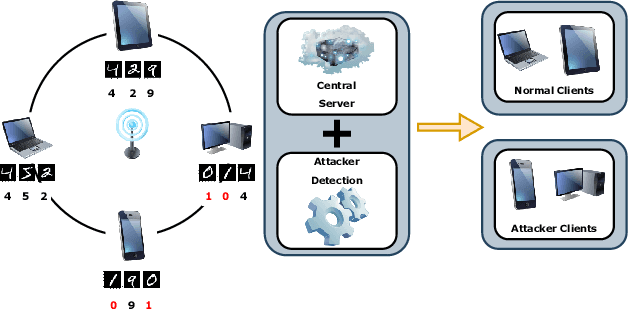
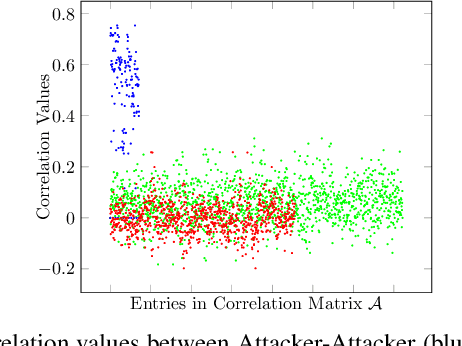

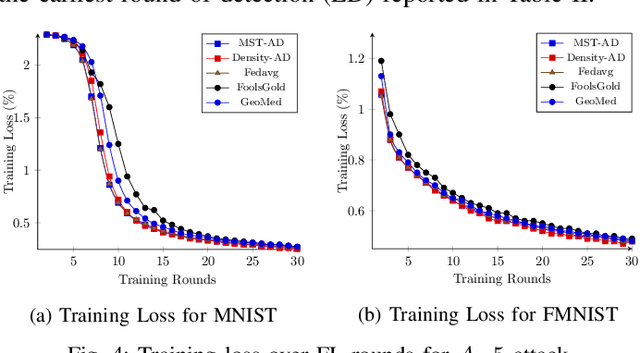
In the era of a data-driven society with the ubiquity of Internet of Things (IoT) devices storing large amounts of data localized at different places, distributed learning has gained a lot of traction, however, assuming independent and identically distributed data (iid) across the devices. While relaxing this assumption that anyway does not hold in reality due to the heterogeneous nature of devices, federated learning (FL) has emerged as a privacy-preserving solution to train a collaborative model over non-iid data distributed across a massive number of devices. However, the appearance of malicious devices (attackers), who intend to corrupt the FL model, is inevitable due to unrestricted participation. In this work, we aim to identify such attackers and mitigate their impact on the model, essentially under a setting of bidirectional label flipping attacks with collusion. We propose two graph theoretic algorithms, based on Minimum Spanning Tree and k-Densest graph, by leveraging correlations between local models. Our FL model can nullify the influence of attackers even when they are up to 70% of all the clients whereas prior works could not afford more than 50% of clients as attackers. The effectiveness of our algorithms is ascertained through experiments on two benchmark datasets, namely MNIST and Fashion-MNIST, with overwhelming attackers. We establish the superiority of our algorithms over the existing ones using accuracy, attack success rate, and early detection round.
Suppressing Noise from Built Environment Datasets to Reduce Communication Rounds for Convergence of Federated Learning
Sep 03, 2022

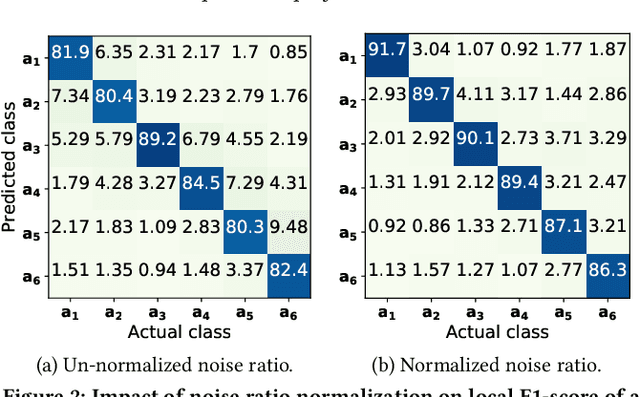
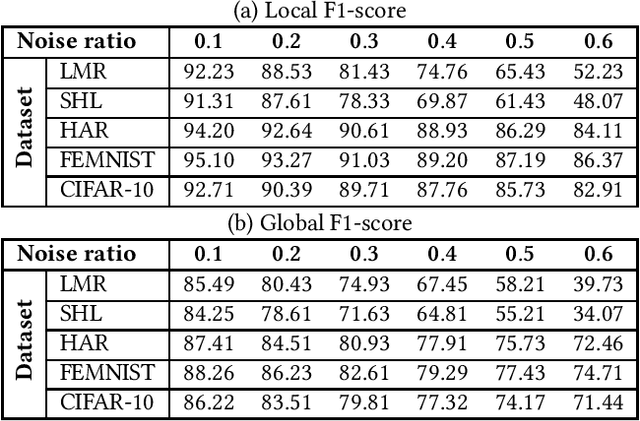
Smart sensing provides an easier and convenient data-driven mechanism for monitoring and control in the built environment. Data generated in the built environment are privacy sensitive and limited. Federated learning is an emerging paradigm that provides privacy-preserving collaboration among multiple participants for model training without sharing private and limited data. The noisy labels in the datasets of the participants degrade the performance and increase the number of communication rounds for convergence of federated learning. Such large communication rounds require more time and energy to train the model. In this paper, we propose a federated learning approach to suppress the unequal distribution of the noisy labels in the dataset of each participant. The approach first estimates the noise ratio of the dataset for each participant and normalizes the noise ratio using the server dataset. The proposed approach can handle bias in the server dataset and minimizes its impact on the participants' dataset. Next, we calculate the optimal weighted contributions of the participants using the normalized noise ratio and influence of each participant. We further derive the expression to estimate the number of communication rounds required for the convergence of the proposed approach. Finally, experimental results demonstrate the effectiveness of the proposed approach over existing techniques in terms of the communication rounds and achieved performance in the built environment.
FedAR+: A Federated Learning Approach to Appliance Recognition with Mislabeled Data in Residential Buildings
Sep 03, 2022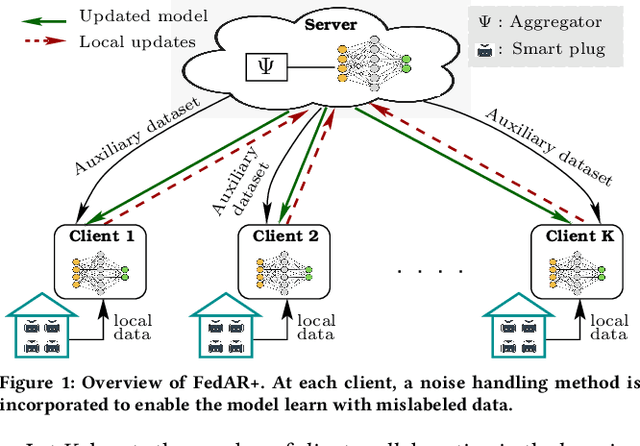
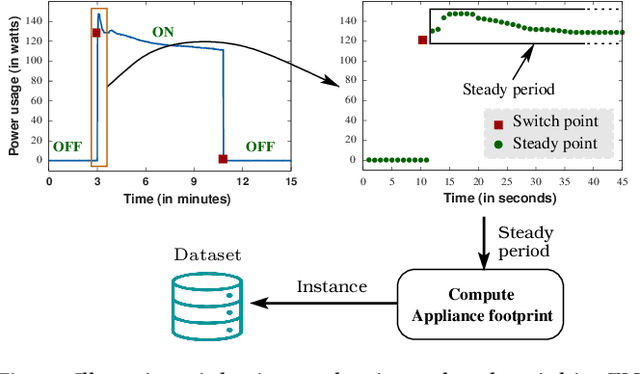

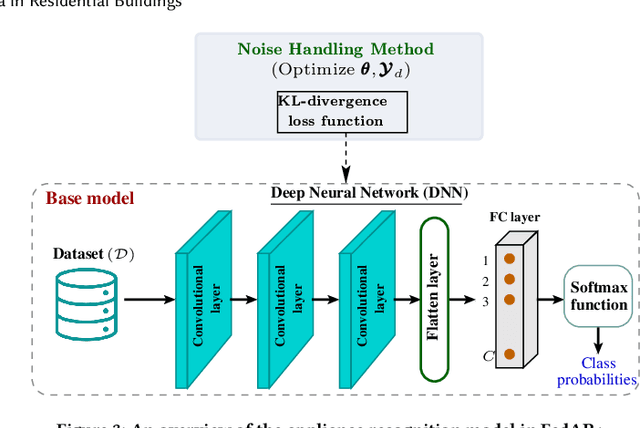
With the enhancement of people's living standards and rapid growth of communication technologies, residential environments are becoming smart and well-connected, increasing overall energy consumption substantially. As household appliances are the primary energy consumers, their recognition becomes crucial to avoid unattended usage, thereby conserving energy and making smart environments more sustainable. An appliance recognition model is traditionally trained at a central server (service provider) by collecting electricity consumption data, recorded via smart plugs, from the clients (consumers), causing a privacy breach. Besides that, the data are susceptible to noisy labels that may appear when an appliance gets connected to a non-designated smart plug. While addressing these issues jointly, we propose a novel federated learning approach to appliance recognition, called FedAR+, enabling decentralized model training across clients in a privacy preserving way even with mislabeled training data. FedAR+ introduces an adaptive noise handling method, essentially a joint loss function incorporating weights and label distribution, to empower the appliance recognition model against noisy labels. By deploying smart plugs in an apartment complex, we collect a labeled dataset that, along with two existing datasets, are utilized to evaluate the performance of FedAR+. Experimental results show that our approach can effectively handle up to $30\%$ concentration of noisy labels while outperforming the prior solutions by a large margin on accuracy.
Long-Short History of Gradients is All You Need: Detecting Malicious and Unreliable Clients in Federated Learning
Aug 14, 2022

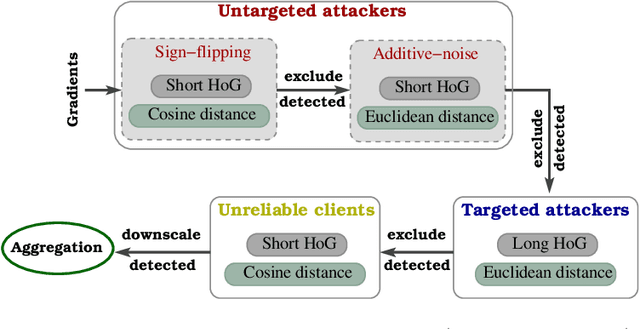
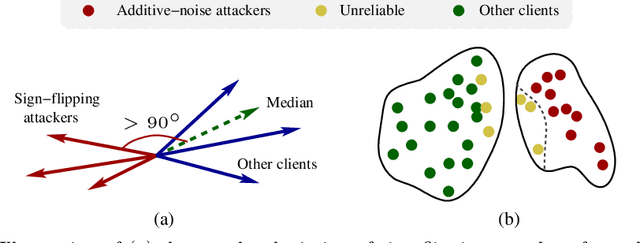
Federated learning offers a framework of training a machine learning model in a distributed fashion while preserving privacy of the participants. As the server cannot govern the clients' actions, nefarious clients may attack the global model by sending malicious local gradients. In the meantime, there could also be unreliable clients who are benign but each has a portion of low-quality training data (e.g., blur or low-resolution images), thus may appearing similar as malicious clients. Therefore, a defense mechanism will need to perform a three-fold differentiation which is much more challenging than the conventional (two-fold) case. This paper introduces MUD-HoG, a novel defense algorithm that addresses this challenge in federated learning using long-short history of gradients, and treats the detected malicious and unreliable clients differently. Not only this, but we can also distinguish between targeted and untargeted attacks among malicious clients, unlike most prior works which only consider one type of the attacks. Specifically, we take into account sign-flipping, additive-noise, label-flipping, and multi-label-flipping attacks, under a non-IID setting. We evaluate MUD-HoG with six state-of-the-art methods on two datasets. The results show that MUD-HoG outperforms all of them in terms of accuracy as well as precision and recall, in the presence of a mixture of multiple (four) types of attackers as well as unreliable clients. Moreover, unlike most prior works which can only tolerate a low population of harmful users, MUD-HoG can work with and successfully detect a wide range of malicious and unreliable clients - up to 47.5% and 10%, respectively, of the total population. Our code is open-sourced at https://github.com/LabSAINT/MUD-HoG_Federated_Learning.
Single Image Internal Distribution Measurement Using Non-Local Variational Autoencoder
Apr 02, 2022
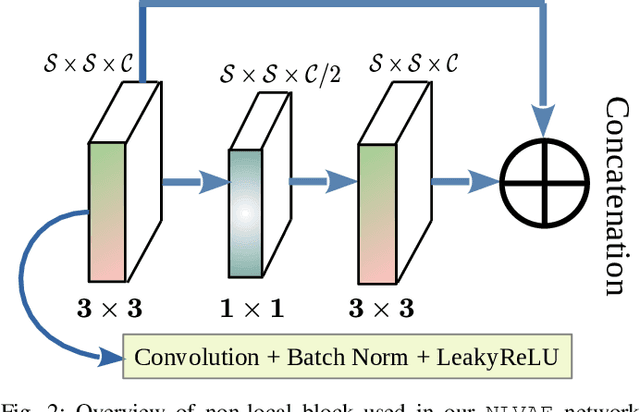
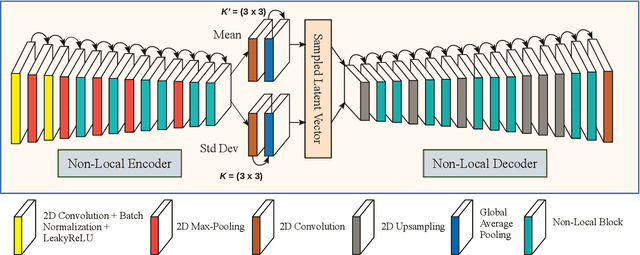

Deep learning-based super-resolution methods have shown great promise, especially for single image super-resolution (SISR) tasks. Despite the performance gain, these methods are limited due to their reliance on copious data for model training. In addition, supervised SISR solutions rely on local neighbourhood information focusing only on the feature learning processes for the reconstruction of low-dimensional images. Moreover, they fail to capitalize on global context due to their constrained receptive field. To combat these challenges, this paper proposes a novel image-specific solution, namely non-local variational autoencoder (\texttt{NLVAE}), to reconstruct a high-resolution (HR) image from a single low-resolution (LR) image without the need for any prior training. To harvest maximum details for various receptive regions and high-quality synthetic images, \texttt{NLVAE} is introduced as a self-supervised strategy that reconstructs high-resolution images using disentangled information from the non-local neighbourhood. Experimental results from seven benchmark datasets demonstrate the effectiveness of the \texttt{NLVAE} model. Moreover, our proposed model outperforms a number of baseline and state-of-the-art methods as confirmed through extensive qualitative and quantitative evaluations.
On the Robot Assisted Movement in Wireless Mobile Sensor Networks
Jul 07, 2021
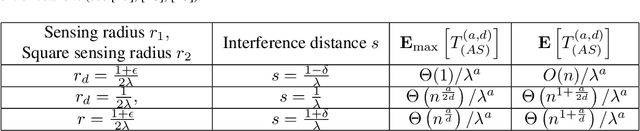
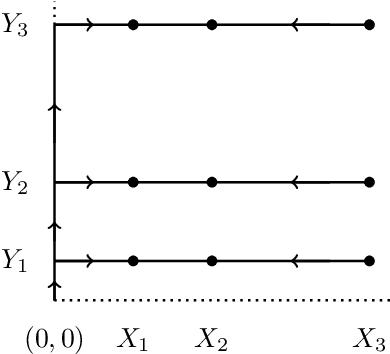

This paper deals with random sensors initially randomly deployed on the line according to general random process and on the plane according to two independent general random processes. The mobile robot with carrying capacity $k$ placed at the origin point is to move the sensors to achieve the general scheduling requirement such as coverage, connectivity and thus to satisfy the desired communication property in the network. We study tradeoffs between the energy consumption in robot's movement, the numbers of sensors $n$, the sensor range $r$, the interference distance $s$, and the robot capacity $k$ until completion of the coverage simultaneously with interference scheduling task. In this work, we obtain upper bounds for the energy consumption in robot's movement and obtain the sharp decrease in the total movement cost of the robot so as to provide the coverage simultaneously with interference requirement.
A Comprehensive Investigation on Range-free Localization Algorithms with Mobile Anchors at Different Altitudes
Mar 05, 2021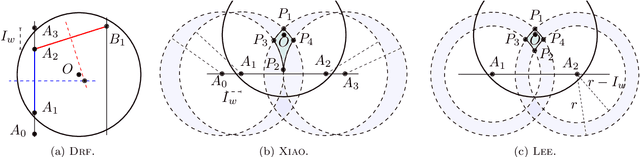

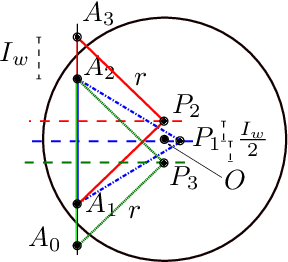

In this work, the problem of localizing ground devices (GDs) is studied comparing the performance of four range-free (RF) localization algorithms that use a mobile anchor (MA). All the investigated algorithms are based on the so-called heard/not-heard (HnH) method, which allows the GDs to detect the MA at the border of their antenna communication radius. Despite the simplicity of this method, its efficacy in terms of accuracy is poor because it relies on the antenna radius that continuously varies under different conditions. Usually, the antenna radius declared by the manufacturer does not fully characterize the actual antenna radiation pattern. In this paper, the radiation pattern of the commercial DecaWave DWM1001 Ultra-Wide-Band (UWB) antennas is observed in a real test-bed at different altitudes for collecting more information and insights on the antenna radius. The compared algorithms are then tested using both the observed and the manufacturer radii. The experimental accuracy is close to the expected theoretical one only when the antenna pattern is actually omnidirectional. However, typical antennas have strong pattern irregularities that decrease the accuracy. For improving the performance, we propose range-based (RB) variants of the compared algorithms in which, instead of using the observed or the manufacturer radii, the actual measured distances between the MA and the GD are used. The localization accuracy tremendously improves confirming that the knowledge of the exact antenna pattern is essential for any RF algorithm.
Speeding up Routing Schedules on Aisle-Graphs with Single Access
Feb 10, 2021
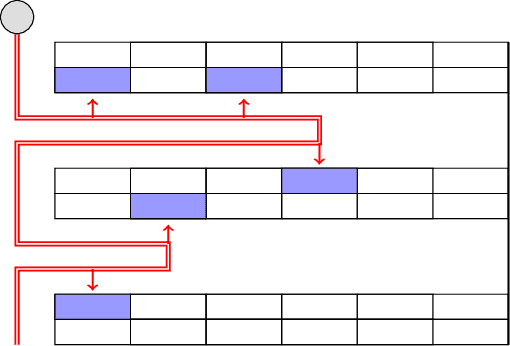
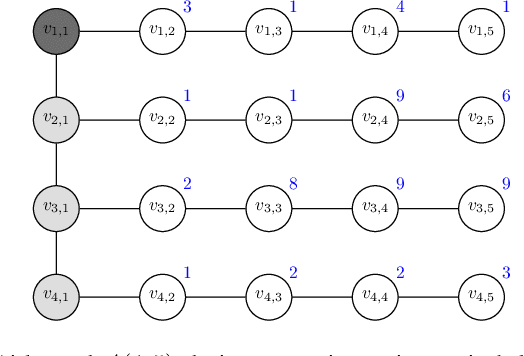
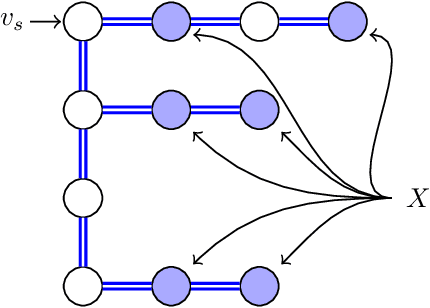
In this paper, we study the Orienteering Aisle-graphs Single-access Problem (OASP), a variant of the orienteering problem for a robot moving in a so-called single-access aisle-graph, i.e., a graph consisting of a set of rows that can be accessed from one side only. Aisle-graphs model, among others, vineyards or warehouses. Each aisle-graph vertex is associated with a reward that a robot obtains when visits the vertex itself. As the robot's energy is limited, only a subset of vertices can be visited with a fully charged battery. The objective is to maximize the total reward collected by the robot with a battery charge. We first propose an optimal algorithm that solves OASP in O(m^2 n^2) time for aisle-graphs with a single access consisting of m rows, each with n vertices. With the goal of designing faster solutions, we propose four greedy sub-optimal algorithms that run in at most O(mn (m+n)) time. For two of them, we guarantee an approximation ratio of 1/2(1-1/e), where e is the base of the natural logarithm, on the total reward by exploiting the well-known submodularity property. Experimentally, we show that these algorithms collect more than 80% of the optimal reward.
Heuristic Algorithms for Co-scheduling of Edge Analytics and Routes for UAV Fleet Missions
Feb 06, 2021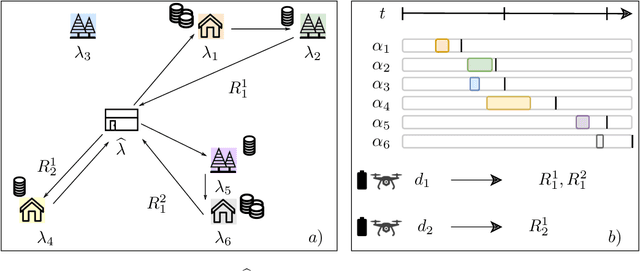

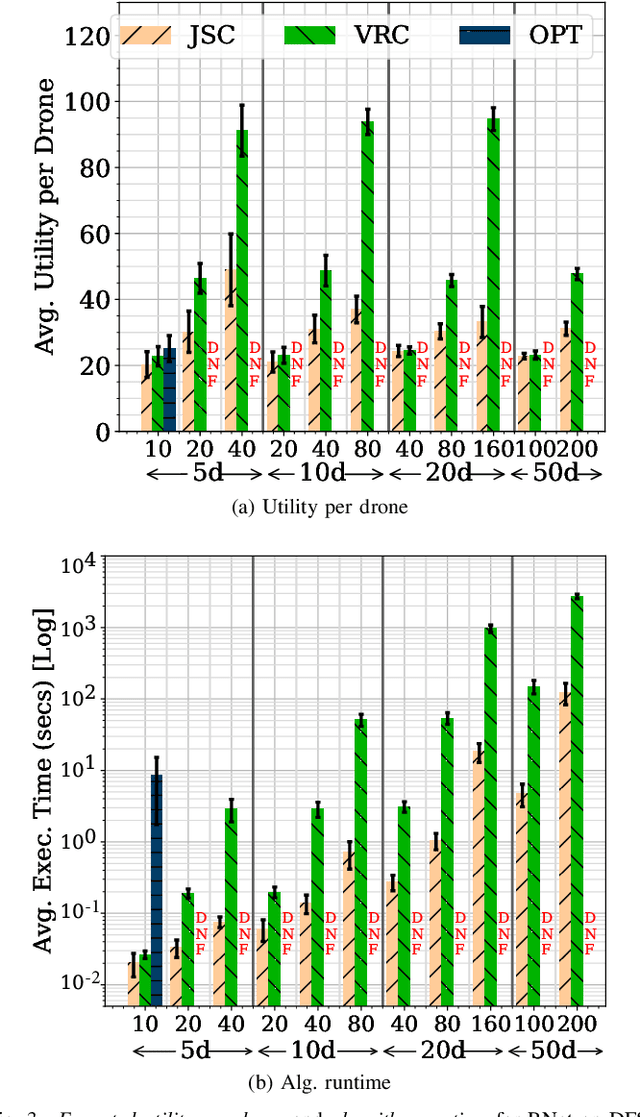
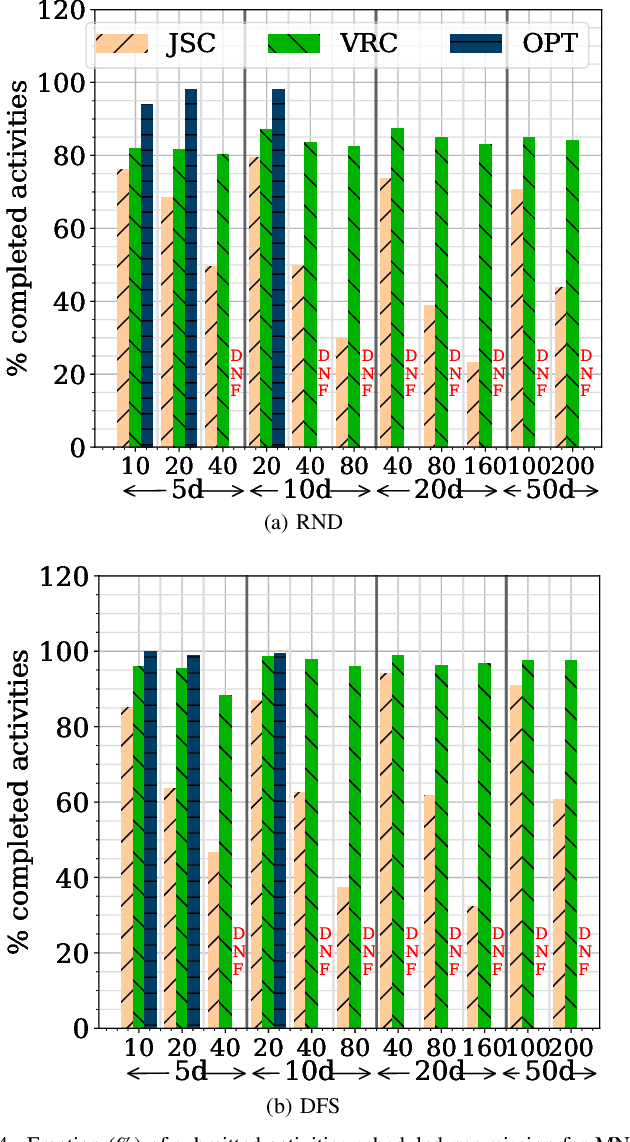
Unmanned Aerial Vehicles (UAVs) or drones are increasingly used for urban applications like traffic monitoring and construction surveys. Autonomous navigation allows drones to visit waypoints and accomplish activities as part of their mission. A common activity is to hover and observe a location using on-board cameras. Advances in Deep Neural Networks (DNNs) allow such videos to be analyzed for automated decision making. UAVs also host edge computing capability for on-board inferencing by such DNNs. To this end, for a fleet of drones, we propose a novel Mission Scheduling Problem (MSP) that co-schedules the flight routes to visit and record video at waypoints, and their subsequent on-board edge analytics. The proposed schedule maximizes the utility from the activities while meeting activity deadlines as well as energy and computing constraints. We first prove that MSP is NP-hard and then optimally solve it by formulating a mixed integer linear programming (MILP) problem. Next, we design two efficient heuristic algorithms, JSC and VRC, that provide fast sub-optimal solutions. Evaluation of these three schedulers using real drone traces demonstrate utility-runtime trade-offs under diverse workloads.