 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStefano Carpin
Informative path planning for scalar dynamic reconstruction using coregionalized Gaussian processes and a spatiotemporal kernel
Sep 13, 2023
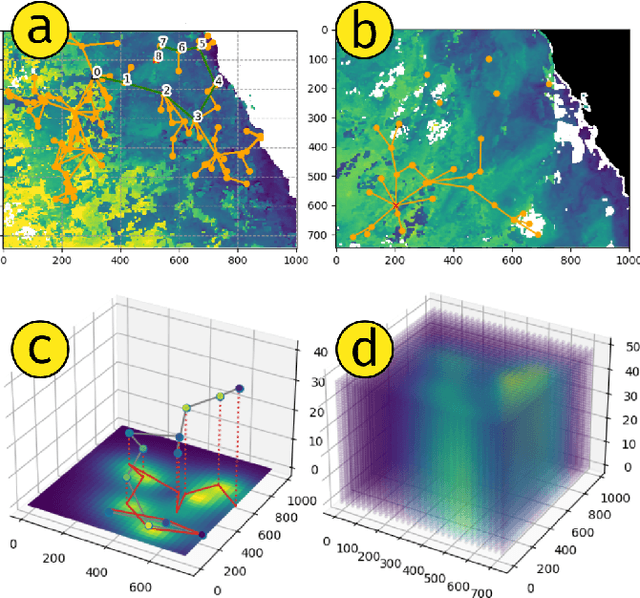
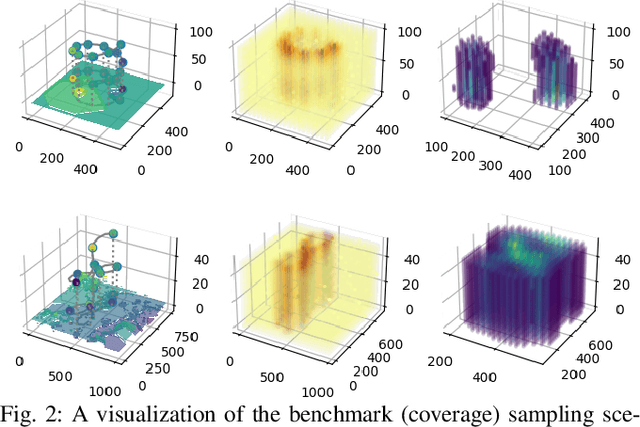
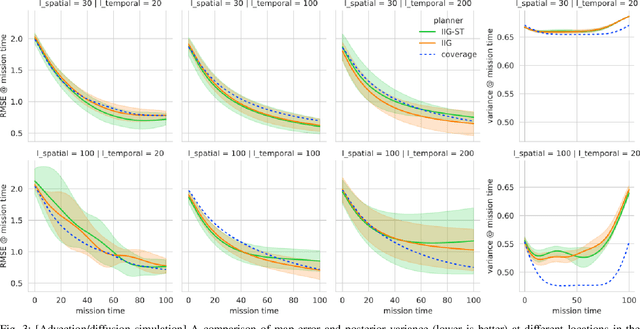
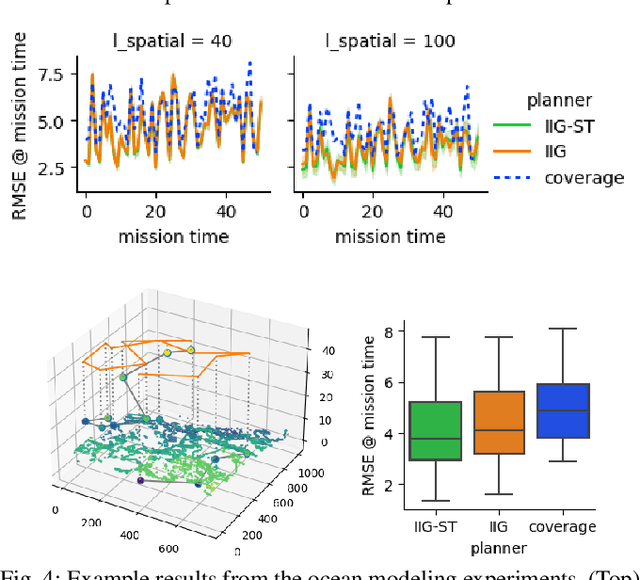
The proliferation of unmanned vehicles offers many opportunities for solving environmental sampling tasks with applications in resource monitoring and precision agriculture. Informative path planning (IPP) includes a family of methods which offer improvements over traditional surveying techniques for suggesting locations for observation collection. In this work, we present a novel solution to the IPP problem by using a coregionalized Gaussian processes to estimate a dynamic scalar field that varies in space and time. Our method improves previous approaches by using a composite kernel accounting for spatiotemporal correlations and at the same time, can be readily incorporated in existing IPP algorithms. Through extensive simulations, we show that our novel modeling approach leads to more accurate estimations when compared with formerly proposed methods that do not account for the temporal dimension.
Speeding up Routing Schedules on Aisle-Graphs with Single Access
Feb 10, 2021
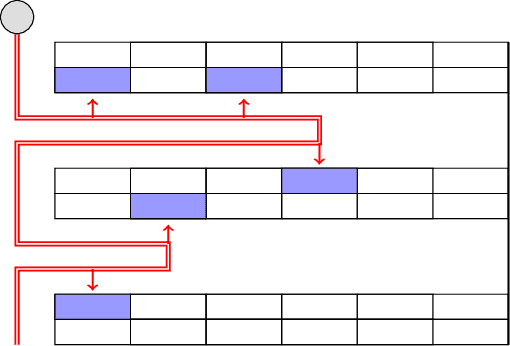
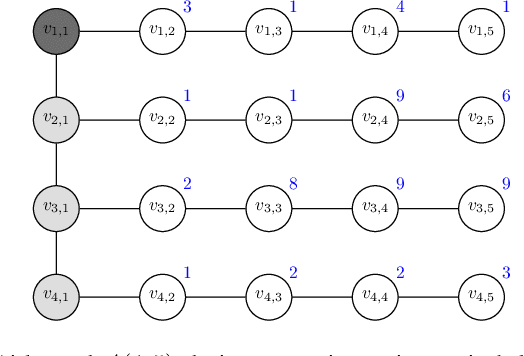
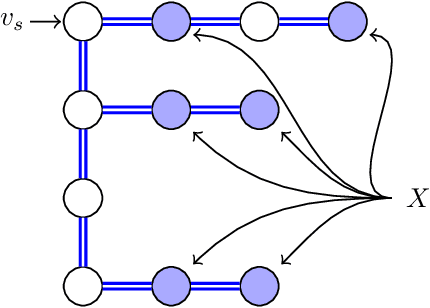
In this paper, we study the Orienteering Aisle-graphs Single-access Problem (OASP), a variant of the orienteering problem for a robot moving in a so-called single-access aisle-graph, i.e., a graph consisting of a set of rows that can be accessed from one side only. Aisle-graphs model, among others, vineyards or warehouses. Each aisle-graph vertex is associated with a reward that a robot obtains when visits the vertex itself. As the robot's energy is limited, only a subset of vertices can be visited with a fully charged battery. The objective is to maximize the total reward collected by the robot with a battery charge. We first propose an optimal algorithm that solves OASP in O(m^2 n^2) time for aisle-graphs with a single access consisting of m rows, each with n vertices. With the goal of designing faster solutions, we propose four greedy sub-optimal algorithms that run in at most O(mn (m+n)) time. For two of them, we guarantee an approximation ratio of 1/2(1-1/e), where e is the base of the natural logarithm, on the total reward by exploiting the well-known submodularity property. Experimentally, we show that these algorithms collect more than 80% of the optimal reward.
Task Planning on Stochastic Aisle Graphs for Precision Agriculture
Feb 03, 2021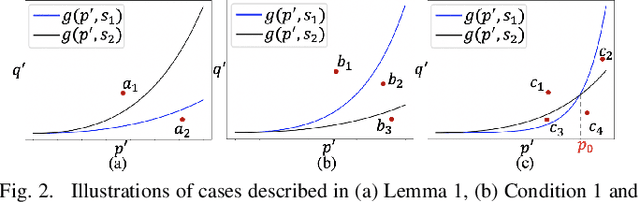
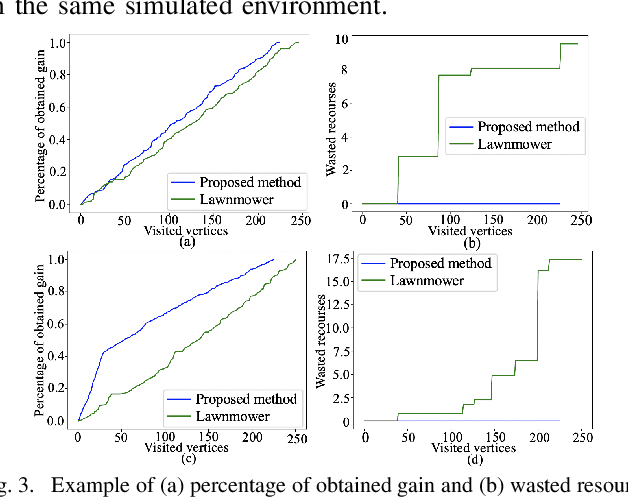
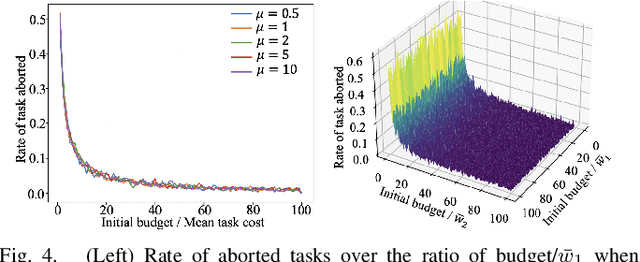
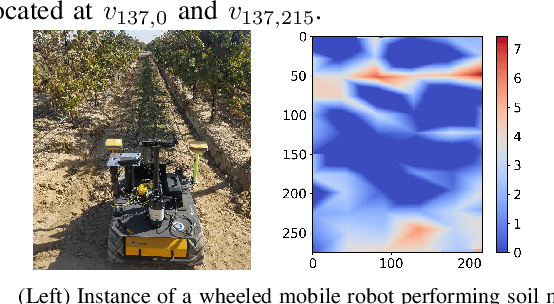
This work addresses task planning under uncertainty for precision agriculture applications whereby task costs are uncertain and the gain of completing a task is proportional to resource consumption (such as water consumption in precision irrigation). The goal is to complete all tasks while prioritizing those that are more urgent, and subject to diverse budget thresholds and stochastic costs for tasks. To describe agriculture-related environments that incorporate stochastic costs to complete tasks, a new Stochastic-Vertex-Cost Aisle Graph (SAG) is introduced. Then, a task allocation algorithm, termed Next-Best-Action Planning (NBA-P), is proposed. NBA-P utilizes the underlying structure enabled by SAG, and tackles the task planning problem by simultaneously determining the optimal tasks to perform and an optimal time to exit (i.e. return to a base station), at run-time. The proposed approach is tested with both simulated data and real-world experimental datasets collected in a commercial vineyard, in both single- and multi-robot scenarios. In all cases, NBA-P outperforms other evaluated methods in terms of return per visited vertex, wasted resources resulting from aborted tasks (i.e. when a budget threshold is exceeded), and total visited vertices.
Optimal Routing Schedules for Robots Operating in Aisle-Structures
Sep 15, 2019
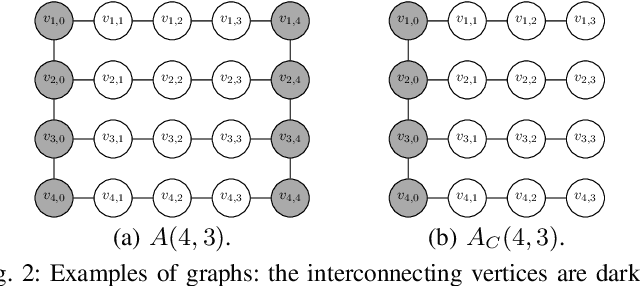
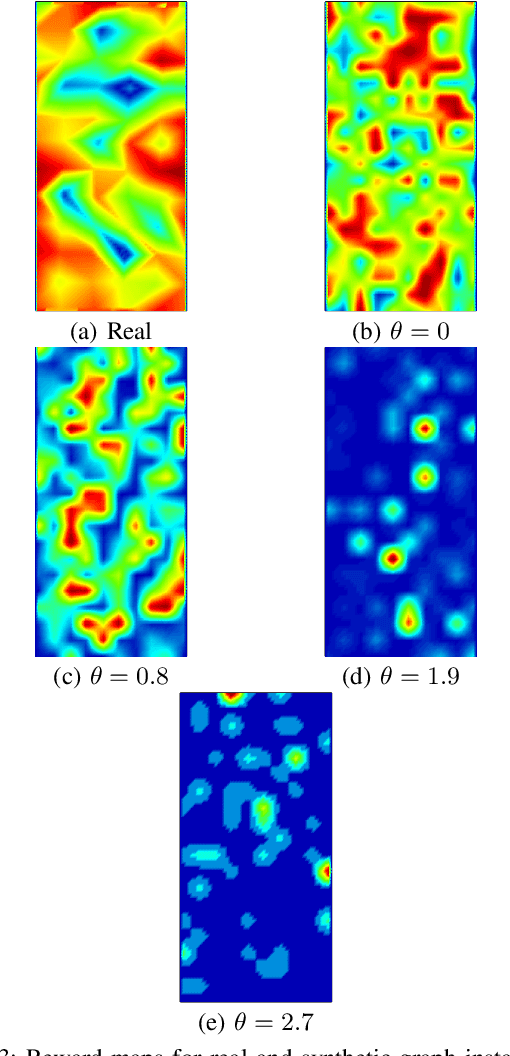
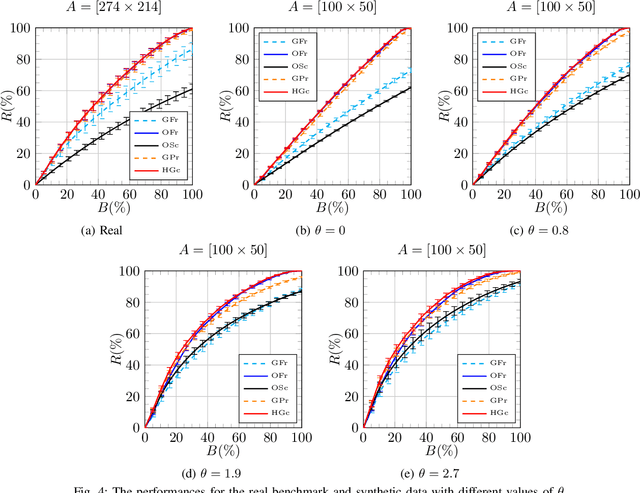
In this paper, we consider the Constant-cost Orienteering Problem (COP) where a robot, constrained by a limited travel budget, aims at selecting a path with the largest reward in an aisle-graph. The aisle-graph consists of a set of loosely connected rows where the robot can change lane only at either end, but not in the middle. Even when considering this special type of graphs, the orienteering problem is known to be NP-hard. We optimally solve in polynomial time two special cases, COP-FR where the robot can only traverse full rows, and COP-SC where the robot can access the rows only from one side. To solve the general COP, we then apply our special case algorithms as well as a new heuristic that suitably combines them. Despite its light computational complexity and being confined into a very limited class of paths, the optimal solutions for COP-FR turn out to be competitive even for COP in both real and synthetic scenarios. Furthermore, our new heuristic for the general case outperforms state-of-art algorithms, especially for input with highly unbalanced rewards.
Multi-Fingered Robotic Grasping: A Primer
Jul 22, 2016
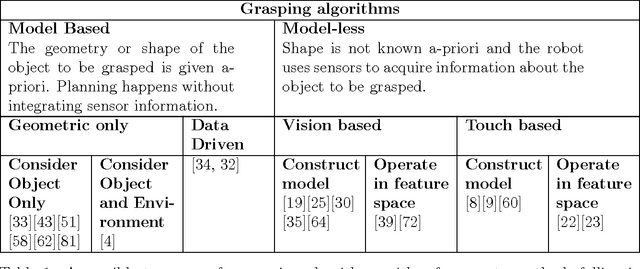
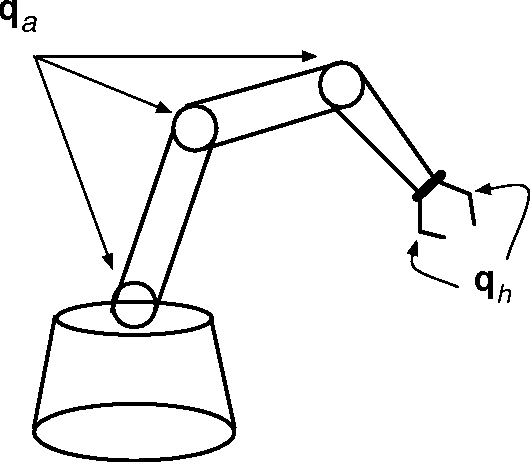
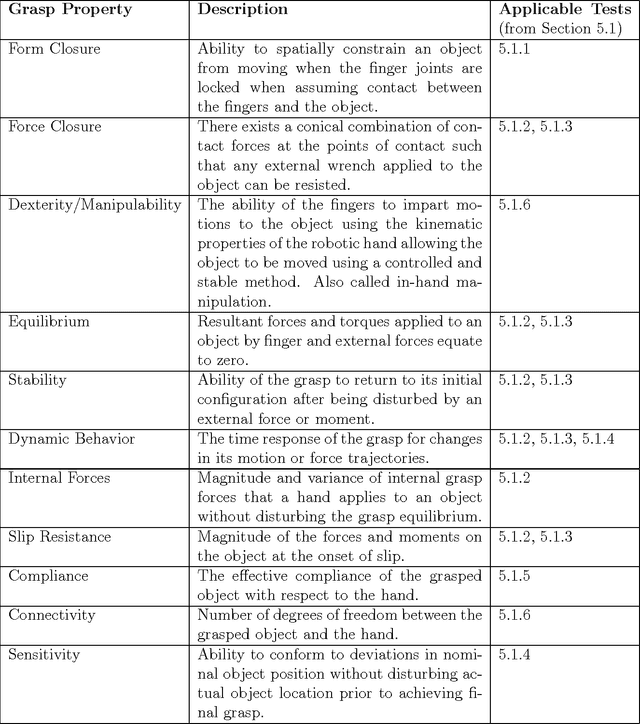
This technical report presents an introduction to different aspects of multi-fingered robot grasping. After having introduced relevant mathematical background for modeling, form and force closure are discussed. Next, we present an overview of various grasp planning algorithms with the objective of illustrating different approaches to solve this problem. Finally, we discuss grasp performance benchmarking.
Trading Safety Versus Performance: Rapid Deployment of Robotic Swarms with Robust Performance Constraints
Nov 22, 2015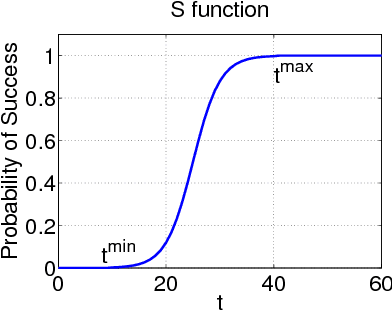
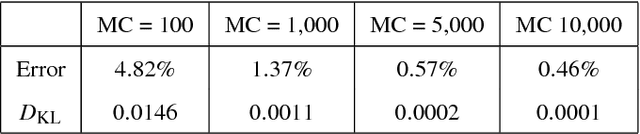
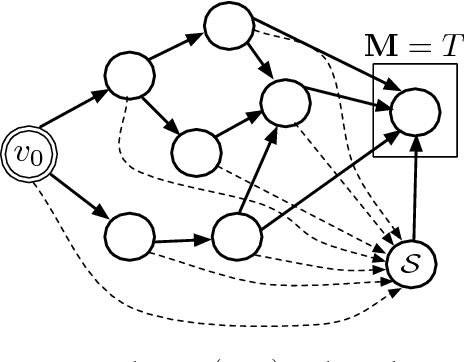
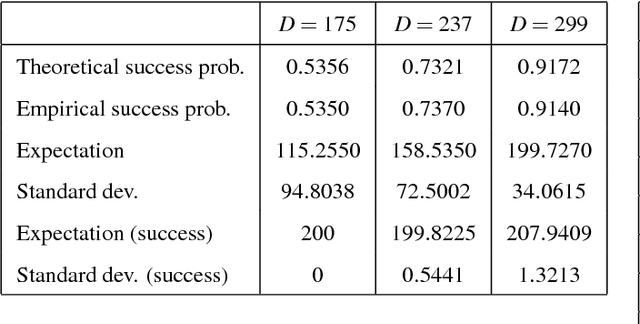
In this paper we consider a stochastic deployment problem, where a robotic swarm is tasked with the objective of positioning at least one robot at each of a set of pre-assigned targets while meeting a temporal deadline. Travel times and failure rates are stochastic but related, inasmuch as failure rates increase with speed. To maximize chances of success while meeting the deadline, a control strategy has therefore to balance safety and performance. Our approach is to cast the problem within the theory of constrained Markov Decision Processes, whereby we seek to compute policies that maximize the probability of successful deployment while ensuring that the expected duration of the task is bounded by a given deadline. To account for uncertainties in the problem parameters, we consider a robust formulation and we propose efficient solution algorithms, which are of independent interest. Numerical experiments confirming our theoretical results are presented and discussed.
Motion Planning with Safety Constraints and High-Level Task Specifications
Jun 14, 2015
We present a method to solve planning problems involving sequential decision making in unpredictable environments while accomplishing a high level task specification expressed using the formalism of linear temporal logic. Our method improves the state of the art by introducing a pruning step that preserves correctness while significantly reducing the time needed to compute an optimal policy. Our theoretical contribution is coupled with simulations substantiating the value of the proposed method.