 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSam Coope
ConvFiT: Conversational Fine-Tuning of Pretrained Language Models
Sep 21, 2021
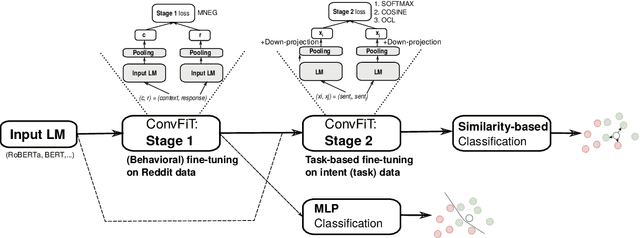

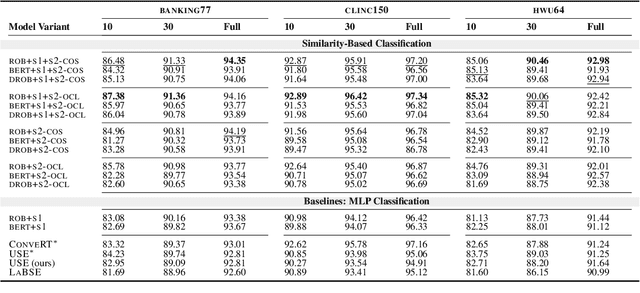
Transformer-based language models (LMs) pretrained on large text collections are proven to store a wealth of semantic knowledge. However, 1) they are not effective as sentence encoders when used off-the-shelf, and 2) thus typically lag behind conversationally pretrained (e.g., via response selection) encoders on conversational tasks such as intent detection (ID). In this work, we propose ConvFiT, a simple and efficient two-stage procedure which turns any pretrained LM into a universal conversational encoder (after Stage 1 ConvFiT-ing) and task-specialised sentence encoder (after Stage 2). We demonstrate that 1) full-blown conversational pretraining is not required, and that LMs can be quickly transformed into effective conversational encoders with much smaller amounts of unannotated data; 2) pretrained LMs can be fine-tuned into task-specialised sentence encoders, optimised for the fine-grained semantics of a particular task. Consequently, such specialised sentence encoders allow for treating ID as a simple semantic similarity task based on interpretable nearest neighbours retrieval. We validate the robustness and versatility of the ConvFiT framework with such similarity-based inference on the standard ID evaluation sets: ConvFiT-ed LMs achieve state-of-the-art ID performance across the board, with particular gains in the most challenging, few-shot setups.
Span-ConveRT: Few-shot Span Extraction for Dialog with Pretrained Conversational Representations
May 18, 2020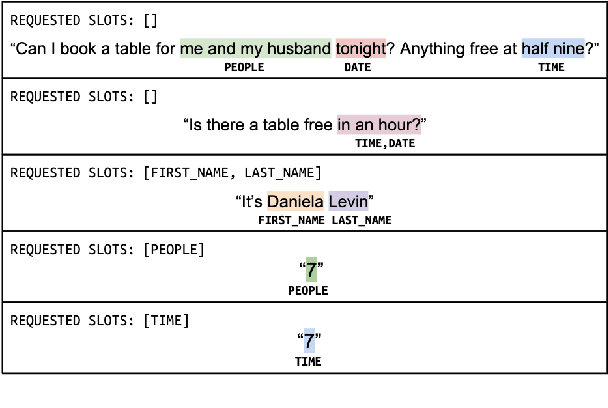

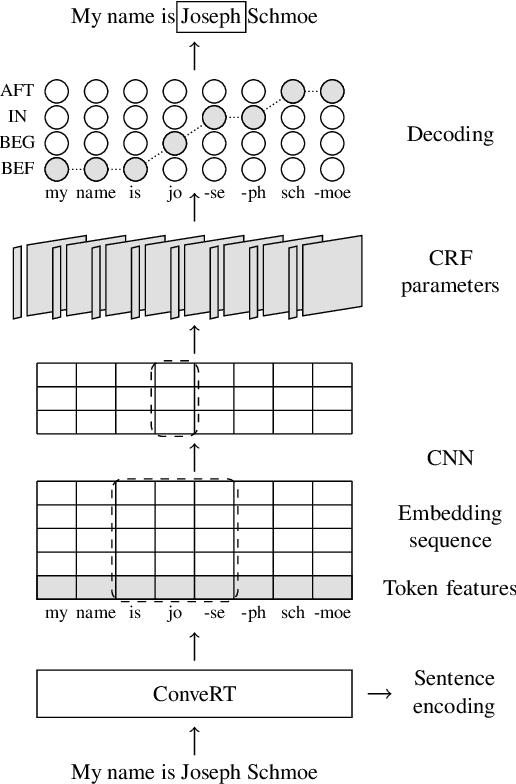

We introduce Span-ConveRT, a light-weight model for dialog slot-filling which frames the task as a turn-based span extraction task. This formulation allows for a simple integration of conversational knowledge coded in large pretrained conversational models such as ConveRT (Henderson et al., 2019). We show that leveraging such knowledge in Span-ConveRT is especially useful for few-shot learning scenarios: we report consistent gains over 1) a span extractor that trains representations from scratch in the target domain, and 2) a BERT-based span extractor. In order to inspire more work on span extraction for the slot-filling task, we also release RESTAURANTS-8K, a new challenging data set of 8,198 utterances, compiled from actual conversations in the restaurant booking domain.
PolyResponse: A Rank-based Approach to Task-Oriented Dialogue with Application in Restaurant Search and Booking
Sep 03, 2019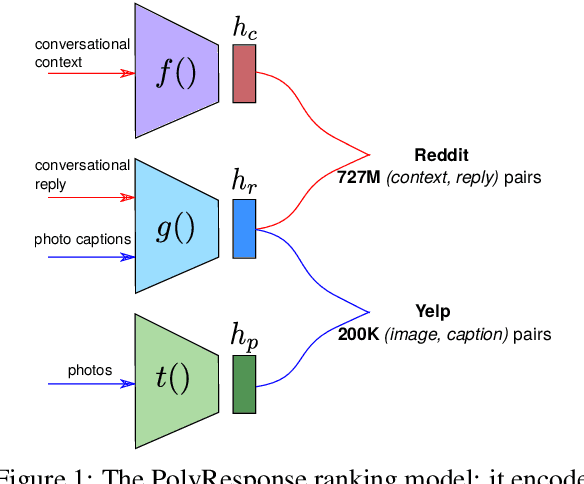
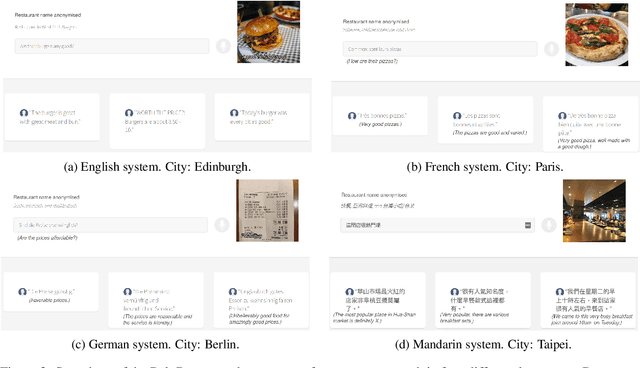
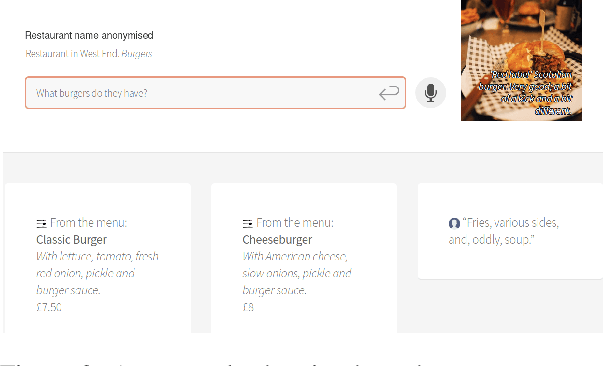
We present PolyResponse, a conversational search engine that supports task-oriented dialogue. It is a retrieval-based approach that bypasses the complex multi-component design of traditional task-oriented dialogue systems and the use of explicit semantics in the form of task-specific ontologies. The PolyResponse engine is trained on hundreds of millions of examples extracted from real conversations: it learns what responses are appropriate in different conversational contexts. It then ranks a large index of text and visual responses according to their similarity to the given context, and narrows down the list of relevant entities during the multi-turn conversation. We introduce a restaurant search and booking system powered by the PolyResponse engine, currently available in 8 different languages.
Training Neural Response Selection for Task-Oriented Dialogue Systems
Jun 07, 2019

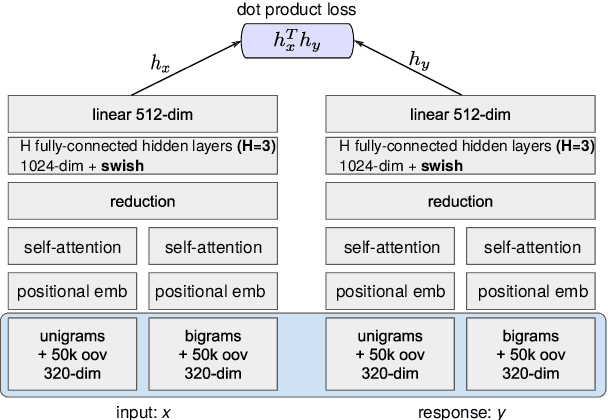

Despite their popularity in the chatbot literature, retrieval-based models have had modest impact on task-oriented dialogue systems, with the main obstacle to their application being the low-data regime of most task-oriented dialogue tasks. Inspired by the recent success of pretraining in language modelling, we propose an effective method for deploying response selection in task-oriented dialogue. To train response selection models for task-oriented dialogue tasks, we propose a novel method which: 1) pretrains the response selection model on large general-domain conversational corpora; and then 2) fine-tunes the pretrained model for the target dialogue domain, relying only on the small in-domain dataset to capture the nuances of the given dialogue domain. Our evaluation on six diverse application domains, ranging from e-commerce to banking, demonstrates the effectiveness of the proposed training method.
A Repository of Conversational Datasets
May 29, 2019

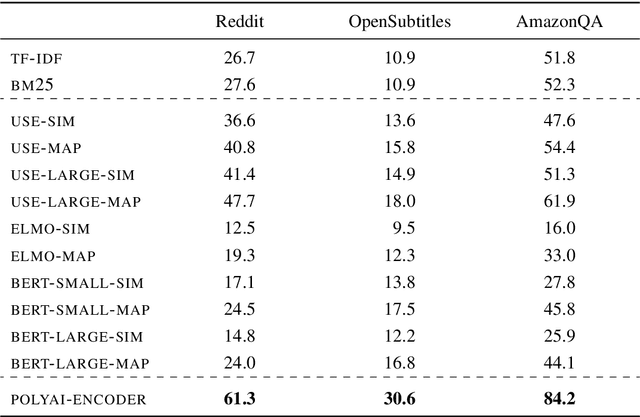

Progress in Machine Learning is often driven by the availability of large datasets, and consistent evaluation metrics for comparing modeling approaches. To this end, we present a repository of conversational datasets consisting of hundreds of millions of examples, and a standardised evaluation procedure for conversational response selection models using '1-of-100 accuracy'. The repository contains scripts that allow researchers to reproduce the standard datasets, or to adapt the pre-processing and data filtering steps to their needs. We introduce and evaluate several competitive baselines for conversational response selection, whose implementations are shared in the repository, as well as a neural encoder model that is trained on the entire training set.
An Attention Mechanism for Answer Selection Using a Combined Global and Local View
Sep 20, 2017



We propose a new attention mechanism for neural based question answering, which depends on varying granularities of the input. Previous work focused on augmenting recurrent neural networks with simple attention mechanisms which are a function of the similarity between a question embedding and an answer embeddings across time. We extend this by making the attention mechanism dependent on a global embedding of the answer attained using a separate network. We evaluate our system on InsuranceQA, a large question answering dataset. Our model outperforms current state-of-the-art results on InsuranceQA. Further, we visualize which sections of text our attention mechanism focuses on, and explore its performance across different parameter settings.