 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSaman Halgamuge
Discriminative Sample-Guided and Parameter-Efficient Feature Space Adaptation for Cross-Domain Few-Shot Learning
Mar 08, 2024




In this paper, we look at cross-domain few-shot classification which presents the challenging task of learning new classes in unseen domains with few labelled examples. Existing methods, though somewhat effective, encounter several limitations, which we address in this work through two significant improvements. First, to address overfitting associated with fine-tuning a large number of parameters on small datasets, we introduce a lightweight parameter-efficient adaptation strategy. This strategy employs a linear transformation of pre-trained features, significantly reducing the trainable parameter count. Second, we replace the traditional nearest centroid classifier with a variance-aware loss function, enhancing the model's sensitivity to the inter- and intra-class variances within the training set for improved clustering in feature space. Empirical evaluations on the Meta-Dataset benchmark showcase that our approach not only improves accuracy up to 7.7% and 5.3% on seen and unseen datasets respectively but also achieves this performance while being at least ~3x more parameter-efficient than existing methods, establishing a new state-of-the-art in cross-domain few-shot learning. Our code can be found at https://github.com/rashindrie/DIPA.
Day-ahead regional solar power forecasting with hierarchical temporal convolutional neural networks using historical power generation and weather data
Mar 04, 2024



Regional solar power forecasting, which involves predicting the total power generation from all rooftop photovoltaic systems in a region holds significant importance for various stakeholders in the energy sector. However, the vast amount of solar power generation and weather time series from geographically dispersed locations that need to be considered in the forecasting process makes accurate regional forecasting challenging. Therefore, previous work has limited the focus to either forecasting a single time series (i.e., aggregated time series) which is the addition of all solar generation time series in a region, disregarding the location-specific weather effects or forecasting solar generation time series of each PV site (i.e., individual time series) independently using location-specific weather data, resulting in a large number of forecasting models. In this work, we propose two deep-learning-based regional forecasting methods that can effectively leverage both types of time series (aggregated and individual) with weather data in a region. We propose two hierarchical temporal convolutional neural network architectures (HTCNN) and two strategies to adapt HTCNNs for regional solar power forecasting. At first, we explore generating a regional forecast using a single HTCNN. Next, we divide the region into multiple sub-regions based on weather information and train separate HTCNNs for each sub-region; the forecasts of each sub-region are then added to generate a regional forecast. The proposed work is evaluated using a large dataset collected over a year from 101 locations across Western Australia to provide a day ahead forecast. We compare our approaches with well-known alternative methods and show that the sub-region HTCNN requires fewer individual networks and achieves a forecast skill score of 40.2% reducing a statistically significant error by 6.5% compared to the best counterpart.
When To Grow? A Fitting Risk-Aware Policy for Layer Growing in Deep Neural Networks
Jan 06, 2024Neural growth is the process of growing a small neural network to a large network and has been utilized to accelerate the training of deep neural networks. One crucial aspect of neural growth is determining the optimal growth timing. However, few studies investigate this systematically. Our study reveals that neural growth inherently exhibits a regularization effect, whose intensity is influenced by the chosen policy for growth timing. While this regularization effect may mitigate the overfitting risk of the model, it may lead to a notable accuracy drop when the model underfits. Yet, current approaches have not addressed this issue due to their lack of consideration of the regularization effect from neural growth. Motivated by these findings, we propose an under/over fitting risk-aware growth timing policy, which automatically adjusts the growth timing informed by the level of potential under/overfitting risks to address both risks. Comprehensive experiments conducted using CIFAR-10/100 and ImageNet datasets show that the proposed policy achieves accuracy improvements of up to 1.3% in models prone to underfitting while achieving similar accuracies in models suffering from overfitting compared to the existing methods.
GINN-LP: A Growing Interpretable Neural Network for Discovering Multivariate Laurent Polynomial Equations
Dec 18, 2023



Traditional machine learning is generally treated as a black-box optimization problem and does not typically produce interpretable functions that connect inputs and outputs. However, the ability to discover such interpretable functions is desirable. In this work, we propose GINN-LP, an interpretable neural network to discover the form and coefficients of the underlying equation of a dataset, when the equation is assumed to take the form of a multivariate Laurent Polynomial. This is facilitated by a new type of interpretable neural network block, named the "power-term approximator block", consisting of logarithmic and exponential activation functions. GINN-LP is end-to-end differentiable, making it possible to use backpropagation for training. We propose a neural network growth strategy that will enable finding the suitable number of terms in the Laurent polynomial that represents the data, along with sparsity regularization to promote the discovery of concise equations. To the best of our knowledge, this is the first model that can discover arbitrary multivariate Laurent polynomial terms without any prior information on the order. Our approach is first evaluated on a subset of data used in SRBench, a benchmark for symbolic regression. We first show that GINN-LP outperforms the state-of-the-art symbolic regression methods on datasets generated using 48 real-world equations in the form of multivariate Laurent polynomials. Next, we propose an ensemble method that combines our method with a high-performing symbolic regression method, enabling us to discover non-Laurent polynomial equations. We achieve state-of-the-art results in equation discovery, showing an absolute improvement of 7.1% over the best contender, by applying this ensemble method to 113 datasets within SRBench with known ground-truth equations.
NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization for Continual Learning
Aug 18, 2023



Catastrophic forgetting; the loss of old knowledge upon acquiring new knowledge, is a pitfall faced by deep neural networks in real-world applications. Many prevailing solutions to this problem rely on storing exemplars (previously encountered data), which may not be feasible in applications with memory limitations or privacy constraints. Therefore, the recent focus has been on Non-Exemplar based Class Incremental Learning (NECIL) where a model incrementally learns about new classes without using any past exemplars. However, due to the lack of old data, NECIL methods struggle to discriminate between old and new classes causing their feature representations to overlap. We propose NAPA-VQ: Neighborhood Aware Prototype Augmentation with Vector Quantization, a framework that reduces this class overlap in NECIL. We draw inspiration from Neural Gas to learn the topological relationships in the feature space, identifying the neighboring classes that are most likely to get confused with each other. This neighborhood information is utilized to enforce strong separation between the neighboring classes as well as to generate old class representative prototypes that can better aid in obtaining a discriminative decision boundary between old and new classes. Our comprehensive experiments on CIFAR-100, TinyImageNet, and ImageNet-Subset demonstrate that NAPA-VQ outperforms the State-of-the-art NECIL methods by an average improvement of 5%, 2%, and 4% in accuracy and 10%, 3%, and 9% in forgetting respectively. Our code can be found in https://github.com/TamashaM/NAPA-VQ.git.
Undercover Deepfakes: Detecting Fake Segments in Videos
May 16, 2023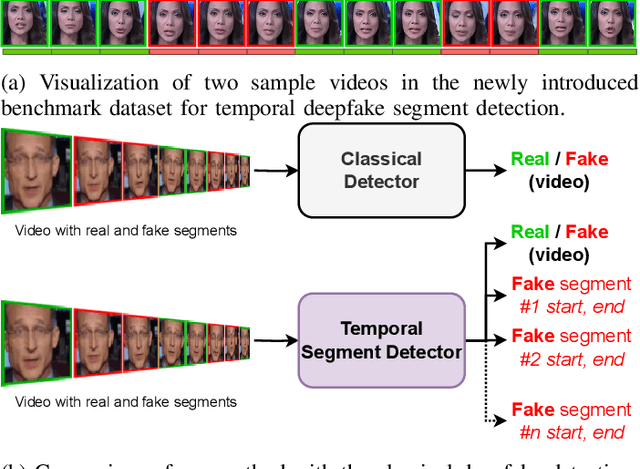
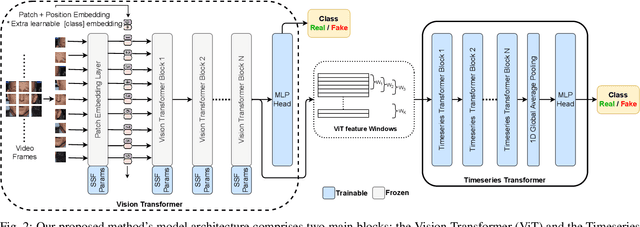
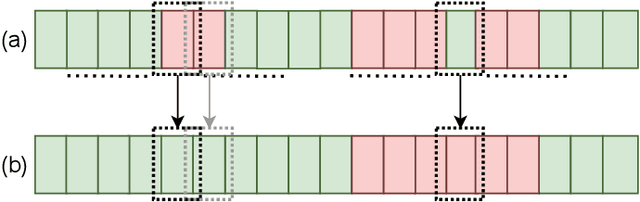
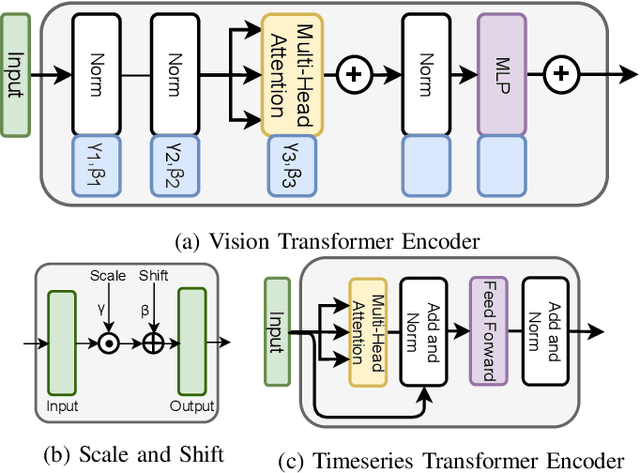
The recent renaissance in generative models, driven primarily by the advent of diffusion models and iterative improvement in GAN methods, has enabled many creative applications. However, each advancement is also accompanied by a rise in the potential for misuse. In the arena of deepfake generation this is a key societal issue. In particular, the ability to modify segments of videos using such generative techniques creates a new paradigm of deepfakes which are mostly real videos altered slightly to distort the truth. Current deepfake detection methods in the academic literature are not evaluated on this paradigm. In this paper, we present a deepfake detection method able to address this issue by performing both frame and video level deepfake prediction. To facilitate testing our method we create a new benchmark dataset where videos have both real and fake frame sequences. Our method utilizes the Vision Transformer, Scaling and Shifting pretraining and Timeseries Transformer to temporally segment videos to help facilitate the interpretation of possible deepfakes. Extensive experiments on a variety of deepfake generation methods show excellent results on temporal segmentation and classical video level predictions as well. In particular, the paradigm we introduce will form a powerful tool for the moderation of deepfakes, where human oversight can be better targeted to the parts of videos suspected of being deepfakes. All experiments can be reproduced at: https://github.com/sanjaysaha1311/temporal-deepfake-segmentation.
Multi-Resolution, Multi-Horizon Distributed Solar PV Power Forecasting with Forecast Combinations
Jun 22, 2022



Distributed, small-scale solar photovoltaic (PV) systems are being installed at a rapidly increasing rate. This can cause major impacts on distribution networks and energy markets. As a result, there is a significant need for improved forecasting of the power generation of these systems at different time resolutions and horizons. However, the performance of forecasting models depends on the resolution and horizon. Forecast combinations (ensembles), that combine the forecasts of multiple models into a single forecast may be robust in such cases. Therefore, in this paper, we provide comparisons and insights into the performance of five state-of-the-art forecast models and existing forecast combinations at multiple resolutions and horizons. We propose a forecast combination approach based on particle swarm optimization (PSO) that will enable a forecaster to produce accurate forecasts for the task at hand by weighting the forecasts produced by individual models. Furthermore, we compare the performance of the proposed combination approach with existing forecast combination approaches. A comprehensive evaluation is conducted using a real-world residential PV power data set measured at 25 houses located in three locations in the United States. The results across four different resolutions and four different horizons show that the PSO-based forecast combination approach outperforms the use of any individual forecast model and other forecast combination counterparts, with an average Mean Absolute Scaled Error reduction by 3.81% compared to the best performing individual model. Our approach enables a solar forecaster to produce accurate forecasts for their application regardless of the forecast resolution or horizon.
A machine learning accelerated inverse design of underwater acoustic polyurethane coatings with cylindrical voids
Mar 02, 2022



Here, we report the development of a detailed "Materials Informatics" framework for the design of acoustic coatings for underwater sound attenuation through integrating Machine Learning (ML) and statistical optimization algorithms with a Finite Element Model (FEM). The finite element models were developed to simulate the realistic performance of the acoustic coatings based on polyurethane (PU) elastomers with embedded cylindrical voids. The FEM results revealed that the frequency-dependent viscoelastic behavior of the polyurethane matrix has a significant impact on the magnitude and frequency of the absorption peak associated with the cylinders at low frequencies, which has been commonly ignored in previous studies on similar systems. The data generated from the FEM was used to train a Deep Neural Network (DNN) to accelerate the design process, and subsequently, was integrated with a Genetic Algorithm (GA) to determine the optimal geometric parameters of the cylinders to achieve maximized, broadband, low-frequency waterborne sound attenuation. A significant, broadband, low-frequency attenuation is achieved by optimally configuring the layers of cylindrical voids and using attenuation mechanisms, including Fabry-P\'erot resonance and Bragg scattering of the layers of voids. Integration of the machine learning technique into the optimization algorithm further accelerated the exploration of the high dimensional design space for the targeted performance. The developed DNN exhibited significantly increased speed (by a factor of $4.5\times 10^3$ ) in predicting the absorption coefficient compared to the conventional FEM(s). Therefore, the acceleration brought by the materials informatics framework brings a paradigm shift to the design and development of acoustic coatings compared to the conventional trial-and-error practices.
Self Organizing Nebulous Growths for Robust and Incremental Data Visualization
Dec 09, 2019



Non-parametric dimensionality reduction techniques, such as t-SNE and UMAP, are proficient in providing visualizations for fixed or static datasets, but they cannot incrementally map and insert new data points into existing data visualizations. We present Self-Organizing Nebulous Growths (SONG), a parametric nonlinear dimensionality reduction technique that supports incremental data visualization, i.e., incremental addition of new data while preserving the structure of the existing visualization. In addition, SONG is capable of handling new data increments no matter whether they are similar or heterogeneous to the existing observations in distribution. We test SONG on a variety of real and simulated datasets. The results show that SONG is superior to Parametric t-SNE, t-SNE and UMAP in incremental data visualization. Specifically, for heterogeneous increments, SONG improves over Parametric t-SNE by 14.98 % on the Fashion MNIST dataset and 49.73% on the MNIST dataset regarding the cluster quality measured by the Adjusted Mutual Information scores. On similar or homogeneous increments, the improvements are 8.36% and 42.26% respectively. Furthermore, even in static cases, SONG performs better or comparable to UMAP, and superior to t-SNE. We also demonstrate that the algorithmic foundations of SONG render it more tolerant to noise compared to UMAP and t-SNE, thus providing greater utility for data with high variance or high mixing of clusters or noise.
Improving MMD-GAN Training with Repulsive Loss Function
Jan 16, 2019



Generative adversarial nets (GANs) are widely used to learn the data sampling process and their performance may heavily depend on the loss functions, given a limited computational budget. This study revisits MMD-GAN that uses the maximum mean discrepancy (MMD) as the loss function for GAN and makes two contributions. First, we argue that the existing MMD loss function may discourage the learning of fine details in data as it attempts to contract the discriminator outputs of real data. To address this issue, we propose a repulsive loss function to actively learn the difference among the real data by simply rearranging the terms in MMD. Second, inspired by the hinge loss, we propose a bounded Gaussian kernel to stabilize the training of MMD-GAN with the repulsive loss function. The proposed methods are applied to the unsupervised image generation tasks on CIFAR-10, STL-10, CelebA, and LSUN bedroom datasets. Results show that the repulsive loss function significantly improves over the MMD loss at no additional computational cost and outperforms other representative loss functions. The proposed methods achieve an FID score of 16.21 on the CIFAR-10 dataset using a single DCGAN network and spectral normalization.