 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamira Samadi
Collective Counterfactual Explanations via Optimal Transport
Feb 07, 2024
Counterfactual explanations provide individuals with cost-optimal actions that can alter their labels to desired classes. However, if substantial instances seek state modification, such individual-centric methods can lead to new competitions and unanticipated costs. Furthermore, these recommendations, disregarding the underlying data distribution, may suggest actions that users perceive as outliers. To address these issues, our work proposes a collective approach for formulating counterfactual explanations, with an emphasis on utilizing the current density of the individuals to inform the recommended actions. Our problem naturally casts as an optimal transport problem. Leveraging the extensive literature on optimal transport, we illustrate how this collective method improves upon the desiderata of classical counterfactual explanations. We support our proposal with numerical simulations, illustrating the effectiveness of the proposed approach and its relation to classic methods.
Do personality tests generalize to Large Language Models?
Nov 09, 2023With large language models (LLMs) appearing to behave increasingly human-like in text-based interactions, it has become popular to attempt to evaluate various properties of these models using tests originally designed for humans. While re-using existing tests is a resource-efficient way to evaluate LLMs, careful adjustments are usually required to ensure that test results are even valid across human sub-populations. Thus, it is not clear to what extent different tests' validity generalizes to LLMs. In this work, we provide evidence that LLMs' responses to personality tests systematically deviate from typical human responses, implying that these results cannot be interpreted in the same way as human test results. Concretely, reverse-coded items (e.g. "I am introverted" vs "I am extraverted") are often both answered affirmatively by LLMs. In addition, variation across different prompts designed to "steer" LLMs to simulate particular personality types does not follow the clear separation into five independent personality factors from human samples. In light of these results, we believe it is important to pay more attention to tests' validity for LLMs before drawing strong conclusions about potentially ill-defined concepts like LLMs' "personality".
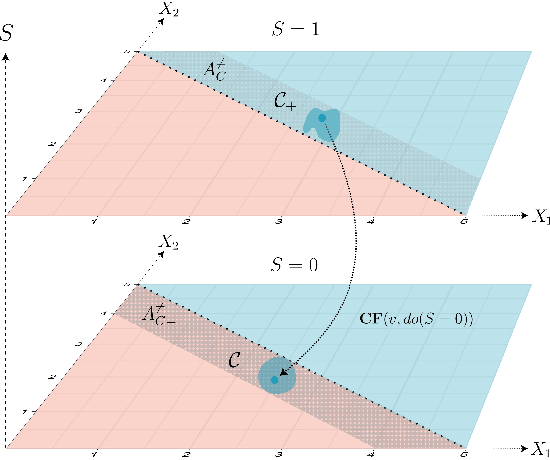
Causal Fair Metric: Bridging Causality, Individual Fairness, and Adversarial Robustness
Oct 30, 2023Adversarial perturbation is used to expose vulnerabilities in machine learning models, while the concept of individual fairness aims to ensure equitable treatment regardless of sensitive attributes. Despite their initial differences, both concepts rely on metrics to generate similar input data instances. These metrics should be designed to align with the data's characteristics, especially when it is derived from causal structure and should reflect counterfactuals proximity. Previous attempts to define such metrics often lack general assumptions about data or structural causal models. In this research, we introduce a causal fair metric formulated based on causal structures that encompass sensitive attributes. For robustness analysis, the concept of protected causal perturbation is presented. Additionally, we delve into metric learning, proposing a method for metric estimation and deployment in real-world problems. The introduced metric has applications in the fields adversarial training, fair learning, algorithmic recourse, and causal reinforcement learning.
Causal Adversarial Perturbations for Individual Fairness and Robustness in Heterogeneous Data Spaces
Aug 17, 2023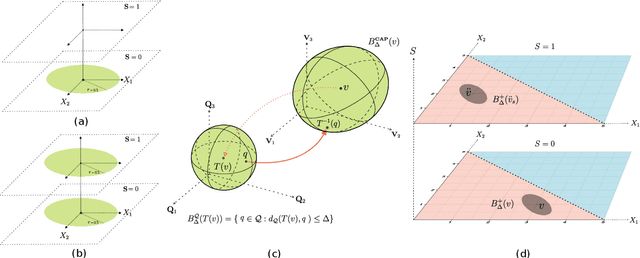

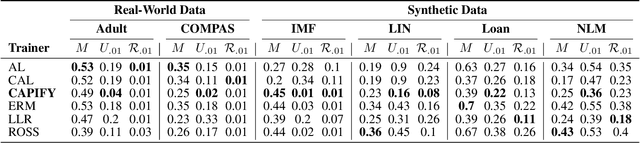
As responsible AI gains importance in machine learning algorithms, properties such as fairness, adversarial robustness, and causality have received considerable attention in recent years. However, despite their individual significance, there remains a critical gap in simultaneously exploring and integrating these properties. In this paper, we propose a novel approach that examines the relationship between individual fairness, adversarial robustness, and structural causal models in heterogeneous data spaces, particularly when dealing with discrete sensitive attributes. We use causal structural models and sensitive attributes to create a fair metric and apply it to measure semantic similarity among individuals. By introducing a novel causal adversarial perturbation and applying adversarial training, we create a new regularizer that combines individual fairness, causality, and robustness in the classifier. Our method is evaluated on both real-world and synthetic datasets, demonstrating its effectiveness in achieving an accurate classifier that simultaneously exhibits fairness, adversarial robustness, and causal awareness.
Sample Efficient Learning of Predictors that Complement Humans
Jul 19, 2022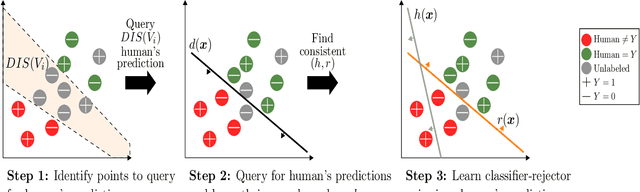
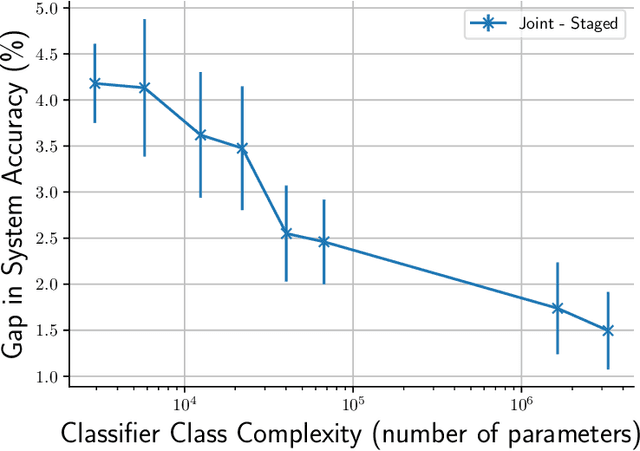
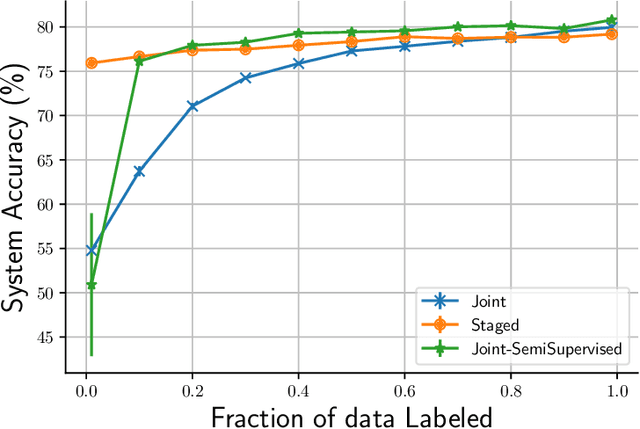
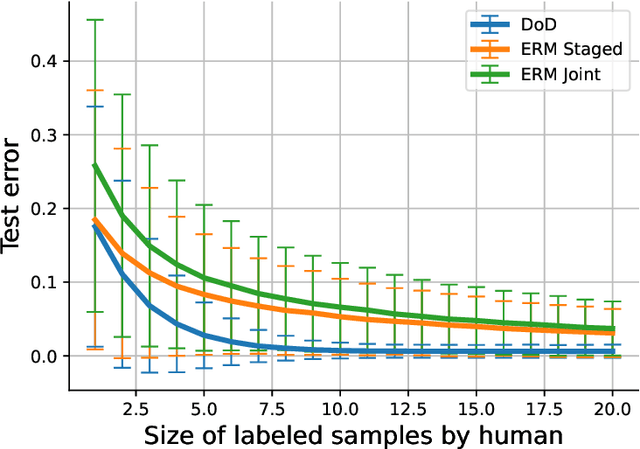
One of the goals of learning algorithms is to complement and reduce the burden on human decision makers. The expert deferral setting wherein an algorithm can either predict on its own or defer the decision to a downstream expert helps accomplish this goal. A fundamental aspect of this setting is the need to learn complementary predictors that improve on the human's weaknesses rather than learning predictors optimized for average error. In this work, we provide the first theoretical analysis of the benefit of learning complementary predictors in expert deferral. To enable efficiently learning such predictors, we consider a family of consistent surrogate loss functions for expert deferral and analyze their theoretical properties. Finally, we design active learning schemes that require minimal amount of data of human expert predictions in order to learn accurate deferral systems.
Pairwise Fairness for Ordinal Regression
May 07, 2021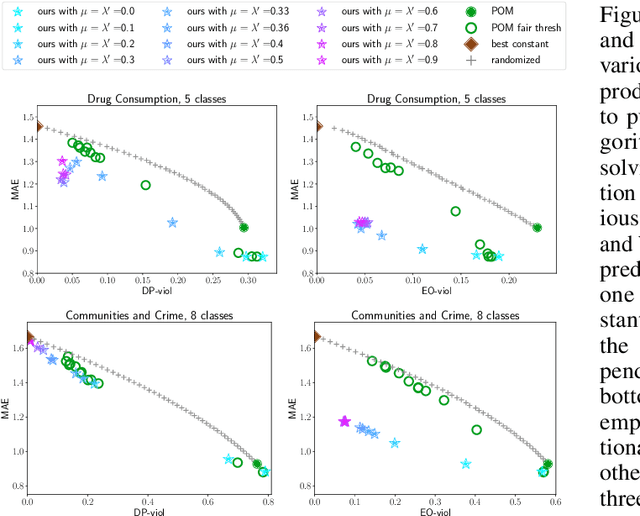
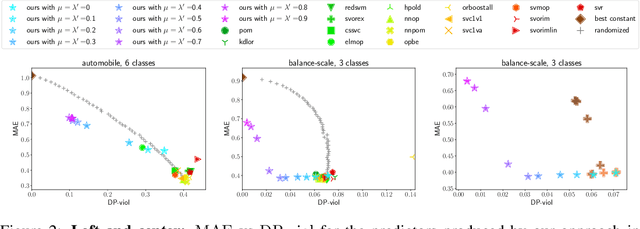
We initiate the study of fairness for ordinal regression, or ordinal classification. We adapt two fairness notions previously considered in fair ranking and propose a strategy for training a predictor that is approximately fair according to either notion. Our predictor consists of a threshold model, composed of a scoring function and a set of thresholds, and our strategy is based on a reduction to fair binary classification for learning the scoring function and local search for choosing the thresholds. We can control the extent to which we care about the accuracy vs the fairness of the predictor via a parameter. In extensive experiments we show that our strategy allows us to effectively explore the accuracy-vs-fairness trade-off and that it often compares favorably to "unfair" state-of-the-art methods for ordinal regression in that it yields predictors that are only slightly less accurate, but significantly more fair.
Fair k-Means Clustering
Jun 17, 2020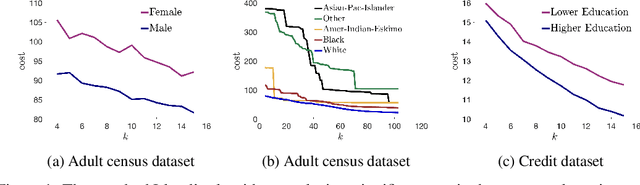
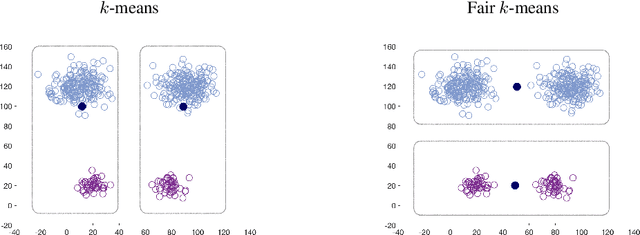
We show that the popular $k$-means clustering algorithm (Lloyd's heuristic), used for a variety of scientific data, can result in outcomes that are unfavorable to subgroups of data (e.g., demographic groups). Such biased clusterings can have deleterious implications for human-centric applications such as resource allocation. We present a fair $k$-means objective and algorithm to choose cluster centers that provide equitable costs for different groups. The algorithm, Fair-Lloyd, is a modification of Lloyd's heuristic for $k$-means, inheriting its simplicity, efficiency, and stability. In comparison with standard Lloyd's, we find that on benchmark data sets, Fair-Lloyd exhibits unbiased performance by ensuring that all groups have balanced costs in the output $k$-clustering, while incurring a negligible increase in running time, thus making it a viable fair option wherever $k$-means is currently used.
Fair Dimensionality Reduction and Iterative Rounding for SDPs
Feb 28, 2019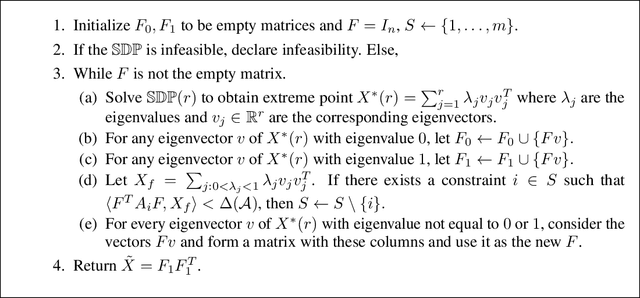
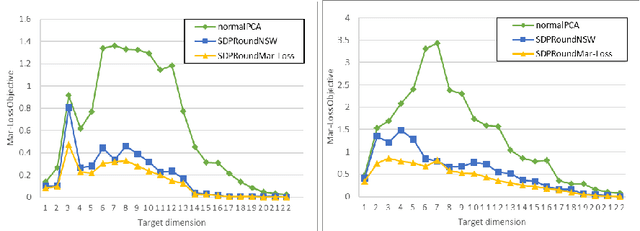
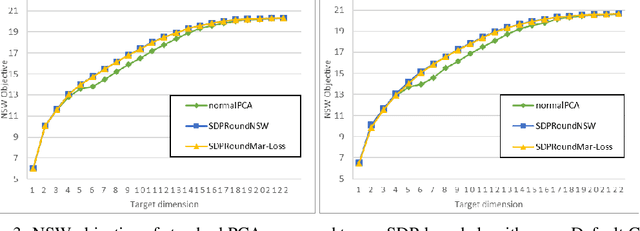
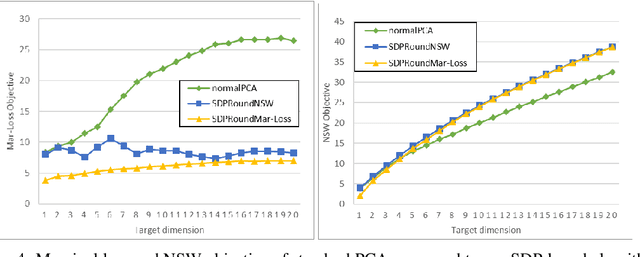
We model "fair" dimensionality reduction as an optimization problem. A central example is the fair PCA problem: the input data is divided into $k$ groups, and the goal is to find a single $d$-dimensional representation for all groups for which the maximum variance (or minimum reconstruction error) is optimized for all groups in a fair (or balanced) manner, e.g., by maximizing the minimum variance over the $k$ groups of the projection to a $d$-dimensional subspace. This problem was introduced by Samadi et al. (2018) who gave a polynomial-time algorithm which, for $k=2$ groups, returns a $(d+1)$-dimensional solution of value at least the best $d$-dimensional solution. We give an exact polynomial-time algorithm for $k=2$ groups. The result relies on extending results of Pataki (1998) regarding rank of extreme point solutions to semi-definite programs. This approach applies more generally to any monotone concave function of the individual group objectives. For $k>2$ groups, our results generalize to give a $(d+\sqrt{2k+0.25}-1.5)$-dimensional solution with objective value as good as the optimal $d$-dimensional solution for arbitrary $k,d$ in polynomial time. Using our extreme point characterization result for SDPs, we give an iterative rounding framework for general SDPs which generalizes the well-known iterative rounding approach for LPs. It returns low-rank solutions with bounded violation of constraints. We obtain a $d$-dimensional projection where the violation in the objective can be bounded additively in terms of the top $O(\sqrt{k})$-singular values of the data matrices. We also give an exact polynomial-time algorithm for any fixed number of groups and target dimension via the algorithm of Grigoriev and Pasechnik (2005). In contrast, when the number of groups is part of the input, even for target dimension $d=1$, we show this problem is NP-hard.
Guarantees for Spectral Clustering with Fairness Constraints
Jan 24, 2019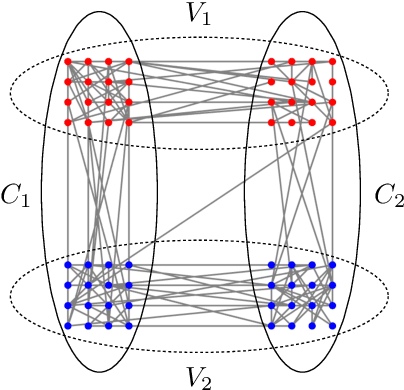
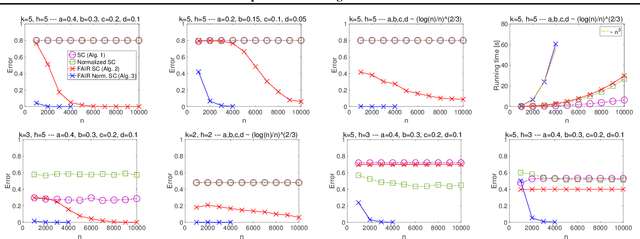
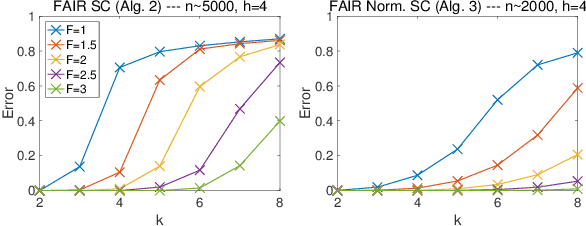
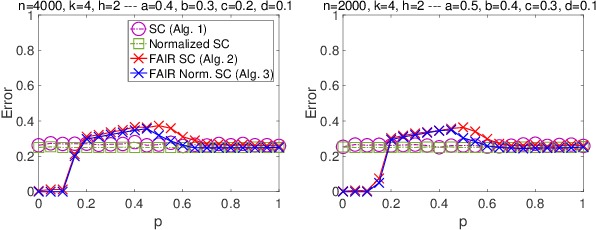
Given the widespread popularity of spectral clustering (SC) for partitioning graph data, we study a version of constrained SC in which we try to incorporate the fairness notion proposed by Chierichetti et al. (2017). According to this notion, a clustering is fair if every demographic group is approximately proportionally represented in each cluster. To this end, we develop variants of both normalized and unnormalized constrained SC and show that they help find fairer clusterings on both synthetic and real data. We also provide a rigorous theoretical analysis of our algorithms. While there have been efforts to incorporate various constraints into the SC framework, theoretically analyzing them is a challenging problem. We overcome this by proposing a natural variant of the stochastic block model where h groups have strong inter-group connectivity, but also exhibit a "natural" clustering structure which is fair. We prove that our algorithms can recover this fair clustering with high probability.
The Price of Fair PCA: One Extra Dimension
Oct 31, 2018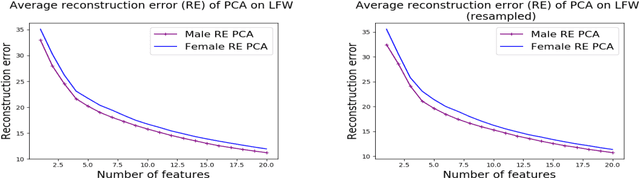
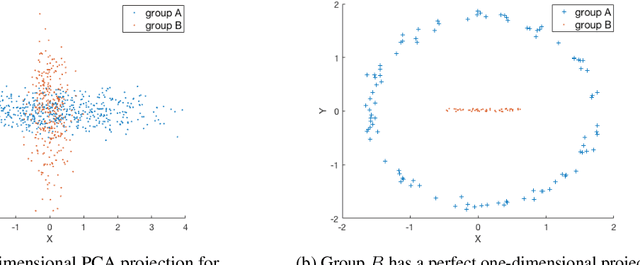
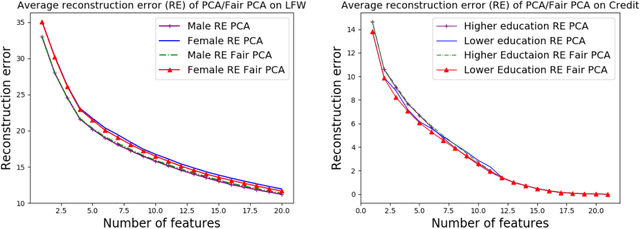
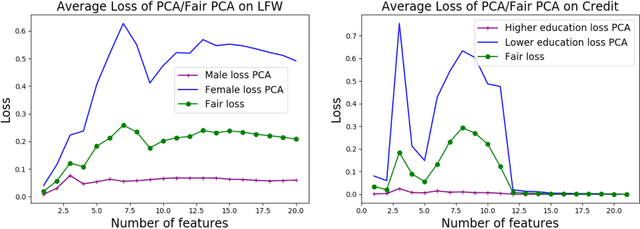
We investigate whether the standard dimensionality reduction technique of PCA inadvertently produces data representations with different fidelity for two different populations. We show on several real-world data sets, PCA has higher reconstruction error on population A than on B (for example, women versus men or lower- versus higher-educated individuals). This can happen even when the data set has a similar number of samples from A and B. This motivates our study of dimensionality reduction techniques which maintain similar fidelity for A and B. We define the notion of Fair PCA and give a polynomial-time algorithm for finding a low dimensional representation of the data which is nearly-optimal with respect to this measure. Finally, we show on real-world data sets that our algorithm can be used to efficiently generate a fair low dimensional representation of the data.