 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamy Jelassi
Q-Probe: A Lightweight Approach to Reward Maximization for Language Models
Feb 22, 2024
We present an approach called Q-probing to adapt a pre-trained language model to maximize a task-specific reward function. At a high level, Q-probing sits between heavier approaches such as finetuning and lighter approaches such as few shot prompting, but can also be combined with either. The idea is to learn a simple linear function on a model's embedding space that can be used to reweight candidate completions. We theoretically show that this sampling procedure is equivalent to a KL-constrained maximization of the Q-probe as the number of samples increases. To train the Q-probes we consider either reward modeling or a class of novel direct policy learning objectives based on importance weighted policy gradients. With this technique, we see gains in domains with ground-truth rewards (code generation) as well as implicit rewards defined by preference data, even outperforming finetuning in data-limited regimes. Moreover, a Q-probe can be trained on top of an API since it only assumes access to sampling and embeddings. Code: https://github.com/likenneth/q_probe .
Repeat After Me: Transformers are Better than State Space Models at Copying
Feb 01, 2024Transformers are the dominant architecture for sequence modeling, but there is growing interest in models that use a fixed-size latent state that does not depend on the sequence length, which we refer to as "generalized state space models" (GSSMs). In this paper we show that while GSSMs are promising in terms of inference-time efficiency, they are limited compared to transformer models on tasks that require copying from the input context. We start with a theoretical analysis of the simple task of string copying and prove that a two layer transformer can copy strings of exponential length while GSSMs are fundamentally limited by their fixed-size latent state. Empirically, we find that transformers outperform GSSMs in terms of efficiency and generalization on synthetic tasks that require copying the context. Finally, we evaluate pretrained large language models and find that transformer models dramatically outperform state space models at copying and retrieving information from context. Taken together, these results suggest a fundamental gap between transformers and GSSMs on tasks of practical interest.
Length Generalization in Arithmetic Transformers
Jun 27, 2023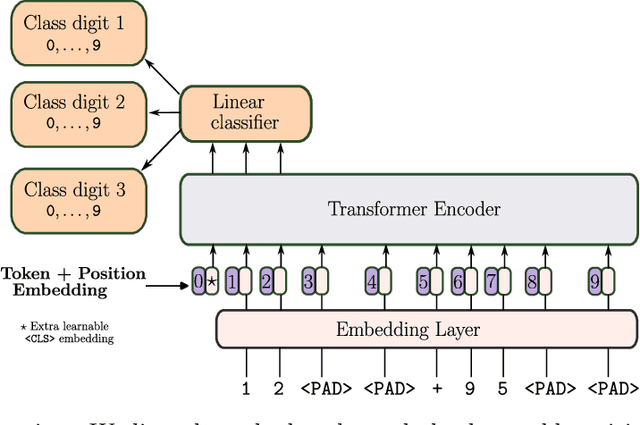
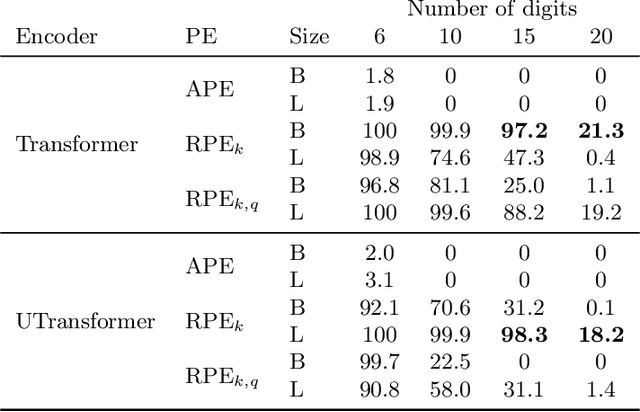
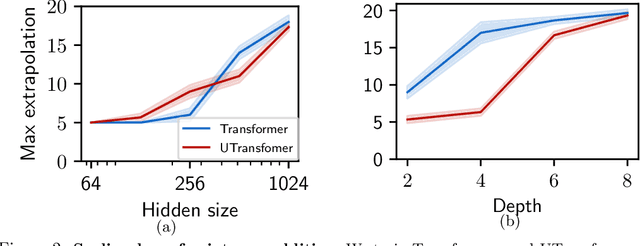

We examine how transformers cope with two challenges: learning basic integer arithmetic, and generalizing to longer sequences than seen during training. We find that relative position embeddings enable length generalization for simple tasks, such as addition: models trained on $5$-digit numbers can perform $15$-digit sums. However, this method fails for multiplication, and we propose train set priming: adding a few ($10$ to $50$) long sequences to the training set. We show that priming allows models trained on $5$-digit $\times$ $3$-digit multiplications to generalize to $35\times 3$ examples. We also show that models can be primed for different generalization lengths, and that the priming sample size scales as the logarithm of the training set size. Finally, we discuss potential applications of priming beyond arithmetic.
Depth Dependence of $μ$P Learning Rates in ReLU MLPs
May 13, 2023In this short note we consider random fully connected ReLU networks of width $n$ and depth $L$ equipped with a mean-field weight initialization. Our purpose is to study the dependence on $n$ and $L$ of the maximal update ($\mu$P) learning rate, the largest learning rate for which the mean squared change in pre-activations after one step of gradient descent remains uniformly bounded at large $n,L$. As in prior work on $\mu$P of Yang et. al., we find that this maximal update learning rate is independent of $n$ for all but the first and last layer weights. However, we find that it has a non-trivial dependence of $L$, scaling like $L^{-3/2}.$
Vision Transformers provably learn spatial structure
Oct 13, 2022
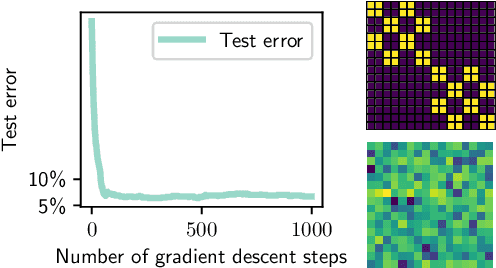
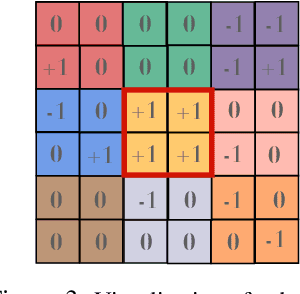
Vision Transformers (ViTs) have achieved comparable or superior performance than Convolutional Neural Networks (CNNs) in computer vision. This empirical breakthrough is even more remarkable since, in contrast to CNNs, ViTs do not embed any visual inductive bias of spatial locality. Yet, recent works have shown that while minimizing their training loss, ViTs specifically learn spatially localized patterns. This raises a central question: how do ViTs learn these patterns by solely minimizing their training loss using gradient-based methods from random initialization? In this paper, we provide some theoretical justification of this phenomenon. We propose a spatially structured dataset and a simplified ViT model. In this model, the attention matrix solely depends on the positional encodings. We call this mechanism the positional attention mechanism. On the theoretical side, we consider a binary classification task and show that while the learning problem admits multiple solutions that generalize, our model implicitly learns the spatial structure of the dataset while generalizing: we call this phenomenon patch association. We prove that patch association helps to sample-efficiently transfer to downstream datasets that share the same structure as the pre-training one but differ in the features. Lastly, we empirically verify that a ViT with positional attention performs similarly to the original one on CIFAR-10/100, SVHN and ImageNet.
Dissecting adaptive methods in GANs
Oct 09, 2022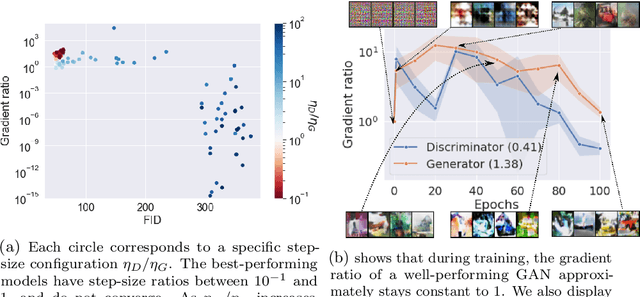
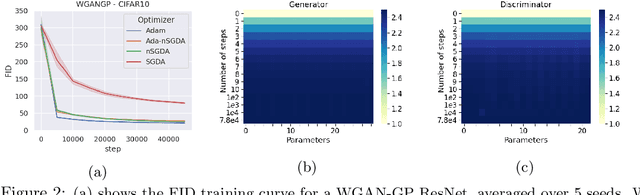
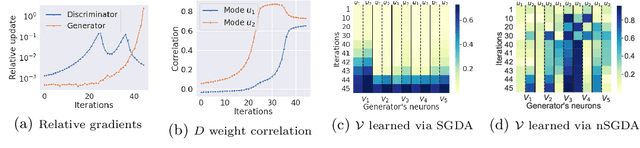
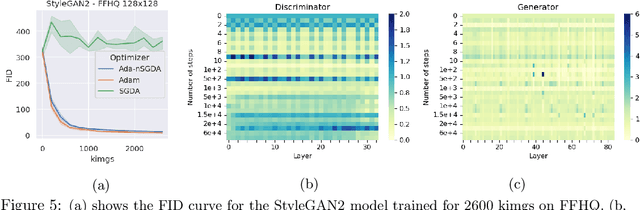
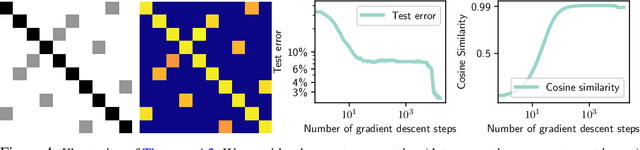
Adaptive methods are a crucial component widely used for training generative adversarial networks (GANs). While there has been some work to pinpoint the "marginal value of adaptive methods" in standard tasks, it remains unclear why they are still critical for GAN training. In this paper, we formally study how adaptive methods help train GANs; inspired by the grafting method proposed in arXiv:2002.11803 [cs.LG], we separate the magnitude and direction components of the Adam updates, and graft them to the direction and magnitude of SGDA updates respectively. By considering an update rule with the magnitude of the Adam update and the normalized direction of SGD, we empirically show that the adaptive magnitude of Adam is key for GAN training. This motivates us to have a closer look at the class of normalized stochastic gradient descent ascent (nSGDA) methods in the context of GAN training. We propose a synthetic theoretical framework to compare the performance of nSGDA and SGDA for GAN training with neural networks. We prove that in that setting, GANs trained with nSGDA recover all the modes of the true distribution, whereas the same networks trained with SGDA (and any learning rate configuration) suffer from mode collapse. The critical insight in our analysis is that normalizing the gradients forces the discriminator and generator to be updated at the same pace. We also experimentally show that for several datasets, Adam's performance can be recovered with nSGDA methods.
Towards understanding how momentum improves generalization in deep learning
Jul 13, 2022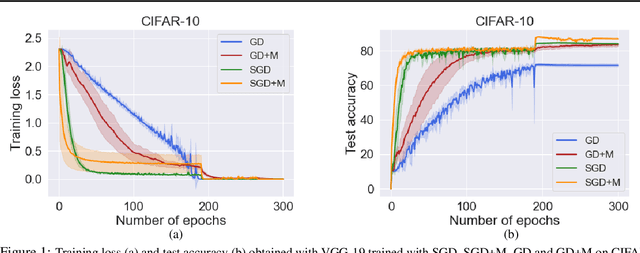
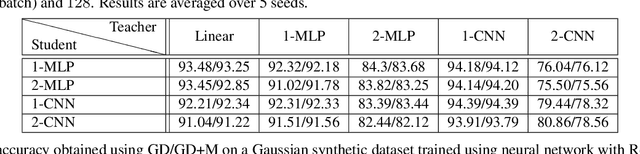
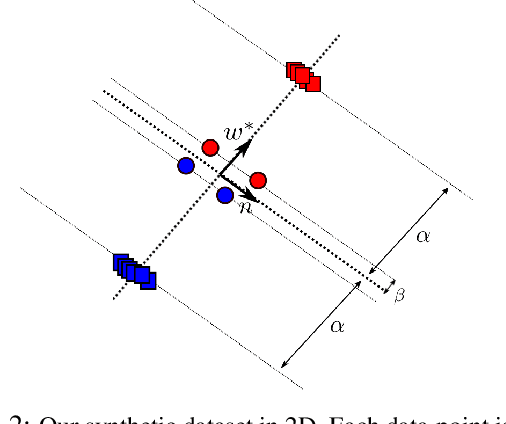

Stochastic gradient descent (SGD) with momentum is widely used for training modern deep learning architectures. While it is well-understood that using momentum can lead to faster convergence rate in various settings, it has also been observed that momentum yields higher generalization. Prior work argue that momentum stabilizes the SGD noise during training and this leads to higher generalization. In this paper, we adopt another perspective and first empirically show that gradient descent with momentum (GD+M) significantly improves generalization compared to gradient descent (GD) in some deep learning problems. From this observation, we formally study how momentum improves generalization. We devise a binary classification setting where a one-hidden layer (over-parameterized) convolutional neural network trained with GD+M provably generalizes better than the same network trained with GD, when both algorithms are similarly initialized. The key insight in our analysis is that momentum is beneficial in datasets where the examples share some feature but differ in their margin. Contrary to GD that memorizes the small margin data, GD+M still learns the feature in these data thanks to its historical gradients. Lastly, we empirically validate our theoretical findings.
Depth separation beyond radial functions
Feb 03, 2021High-dimensional depth separation results for neural networks show that certain functions can be efficiently approximated by two-hidden-layer networks but not by one-hidden-layer ones in high-dimensions $d$. Existing results of this type mainly focus on functions with an underlying radial or one-dimensional structure, which are usually not encountered in practice. The first contribution of this paper is to extend such results to a more general class of functions, namely functions with piece-wise oscillatory structure, by building on the proof strategy of (Eldan and Shamir, 2016). We complement these results by showing that, if the domain radius and the rate of oscillation of the objective function are constant, then approximation by one-hidden-layer networks holds at a $\mathrm{poly}(d)$ rate for any fixed error threshold. A common theme in the proof of such results is the fact that one-hidden-layer networks fail to approximate high-energy functions whose Fourier representation is spread in the domain. On the other hand, existing approximation results of a function by one-hidden-layer neural networks rely on the function having a sparse Fourier representation. The choice of the domain also represents a source of gaps between upper and lower approximation bounds. Focusing on a fixed approximation domain, namely the sphere $\mathbb{S}^{d-1}$ in dimension $d$, we provide a characterization of both functions which are efficiently approximable by one-hidden-layer networks and of functions which are provably not, in terms of their Fourier expansion.
Adaptivity without Compromise: A Momentumized, Adaptive, Dual Averaged Gradient Method for Stochastic Optimization
Jan 26, 2021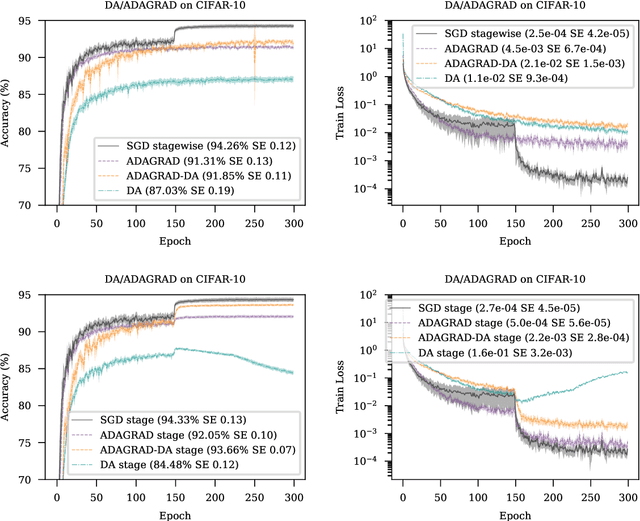
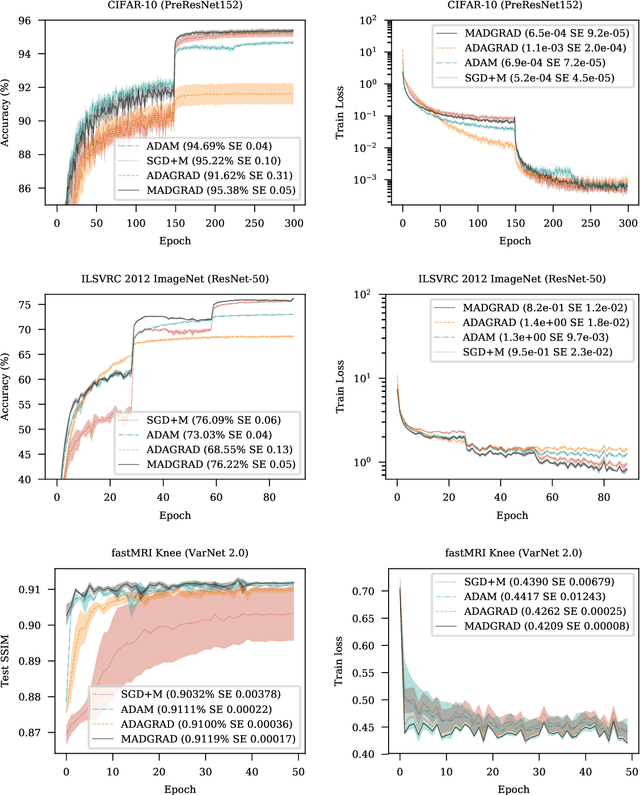
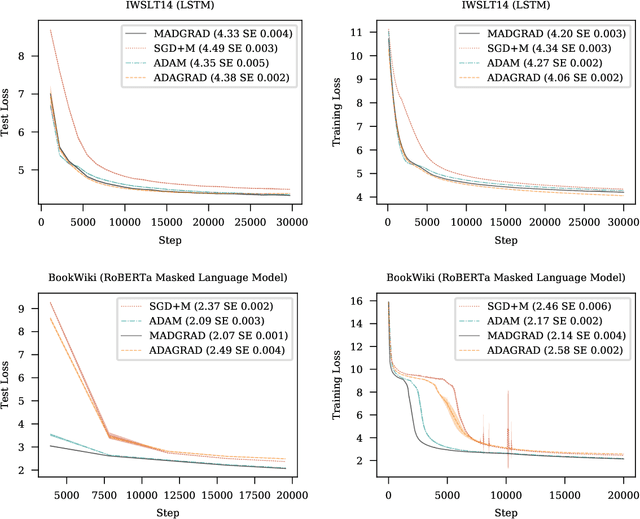
We introduce MADGRAD, a novel optimization method in the family of AdaGrad adaptive gradient methods. MADGRAD shows excellent performance on deep learning optimization problems from multiple fields, including classification and image-to-image tasks in vision, and recurrent and bidirectionally-masked models in natural language processing. For each of these tasks, MADGRAD matches or outperforms both SGD and ADAM in test set performance, even on problems for which adaptive methods normally perform poorly.
Dual Averaging is Surprisingly Effective for Deep Learning Optimization
Oct 20, 2020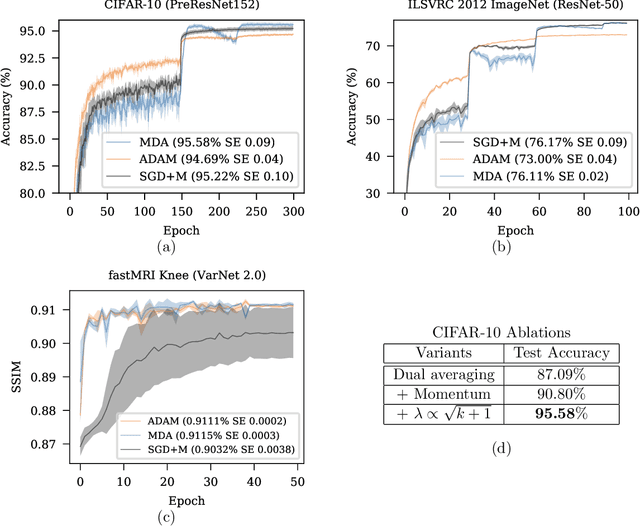
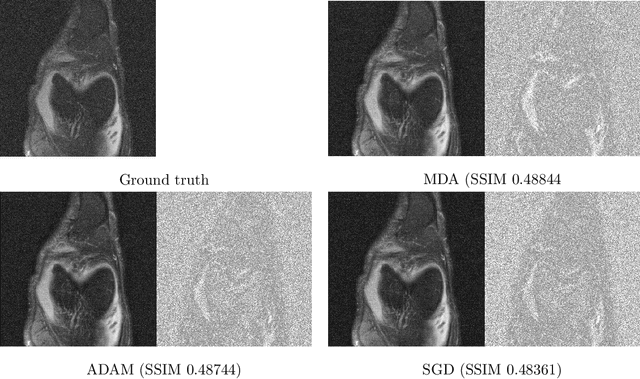
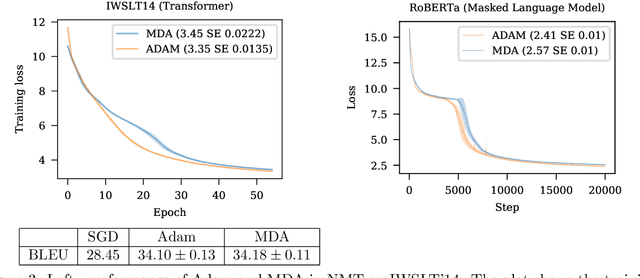
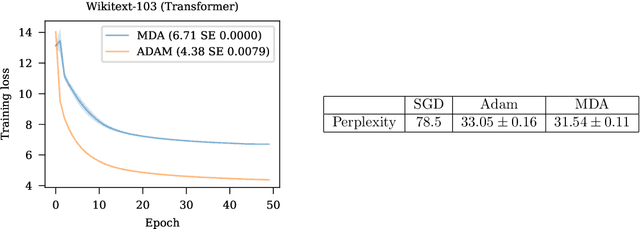
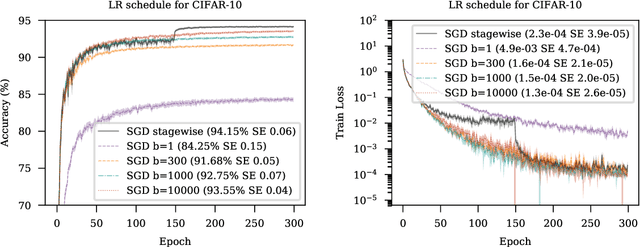
First-order stochastic optimization methods are currently the most widely used class of methods for training deep neural networks. However, the choice of the optimizer has become an ad-hoc rule that can significantly affect the performance. For instance, SGD with momentum (SGD+M) is typically used in computer vision (CV) and Adam is used for training transformer models for Natural Language Processing (NLP). Using the wrong method can lead to significant performance degradation. Inspired by the dual averaging algorithm, we propose Modernized Dual Averaging (MDA), an optimizer that is able to perform as well as SGD+M in CV and as Adam in NLP. Our method is not adaptive and is significantly simpler than Adam. We show that MDA induces a decaying uncentered $L_2$-regularization compared to vanilla SGD+M and hypothesize that this may explain why it works on NLP problems where SGD+M fails.