 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSebastian Möller
A Dataset for Pharmacovigilance in German, French, and Japanese: Annotating Adverse Drug Reactions across Languages
Mar 27, 2024
User-generated data sources have gained significance in uncovering Adverse Drug Reactions (ADRs), with an increasing number of discussions occurring in the digital world. However, the existing clinical corpora predominantly revolve around scientific articles in English. This work presents a multilingual corpus of texts concerning ADRs gathered from diverse sources, including patient fora, social media, and clinical reports in German, French, and Japanese. Our corpus contains annotations covering 12 entity types, four attribute types, and 13 relation types. It contributes to the development of real-world multilingual language models for healthcare. We provide statistics to highlight certain challenges associated with the corpus and conduct preliminary experiments resulting in strong baselines for extracting entities and relations between these entities, both within and across languages.
Protect and Extend -- Using GANs for Synthetic Data Generation of Time-Series Medical Records
Mar 01, 2024Preservation of private user data is of paramount importance for high Quality of Experience (QoE) and acceptability, particularly with services treating sensitive data, such as IT-based health services. Whereas anonymization techniques were shown to be prone to data re-identification, synthetic data generation has gradually replaced anonymization since it is relatively less time and resource-consuming and more robust to data leakage. Generative Adversarial Networks (GANs) have been used for generating synthetic datasets, especially GAN frameworks adhering to the differential privacy phenomena. This research compares state-of-the-art GAN-based models for synthetic data generation to generate time-series synthetic medical records of dementia patients which can be distributed without privacy concerns. Predictive modeling, autocorrelation, and distribution analysis are used to assess the Quality of Generating (QoG) of the generated data. The privacy preservation of the respective models is assessed by applying membership inference attacks to determine potential data leakage risks. Our experiments indicate the superiority of the privacy-preserving GAN (PPGAN) model over other models regarding privacy preservation while maintaining an acceptable level of QoG. The presented results can support better data protection for medical use cases in the future.
LLMCheckup: Conversational Examination of Large Language Models via Interpretability Tools
Jan 23, 2024Interpretability tools that offer explanations in the form of a dialogue have demonstrated their efficacy in enhancing users' understanding, as one-off explanations may occasionally fall short in providing sufficient information to the user. Current solutions for dialogue-based explanations, however, require many dependencies and are not easily transferable to tasks they were not designed for. With LLMCheckup, we present an easily accessible tool that allows users to chat with any state-of-the-art large language model (LLM) about its behavior. We enable LLMs to generate all explanations by themselves and take care of intent recognition without fine-tuning, by connecting them with a broad spectrum of Explainable AI (XAI) tools, e.g. feature attributions, embedding-based similarity, and prompting strategies for counterfactual and rationale generation. LLM (self-)explanations are presented as an interactive dialogue that supports follow-up questions and generates suggestions. LLMCheckup provides tutorials for operations available in the system, catering to individuals with varying levels of expertise in XAI and supports multiple input modalities. We introduce a new parsing strategy called multi-prompt parsing substantially enhancing the parsing accuracy of LLMs. Finally, we showcase the tasks of fact checking and commonsense question answering.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023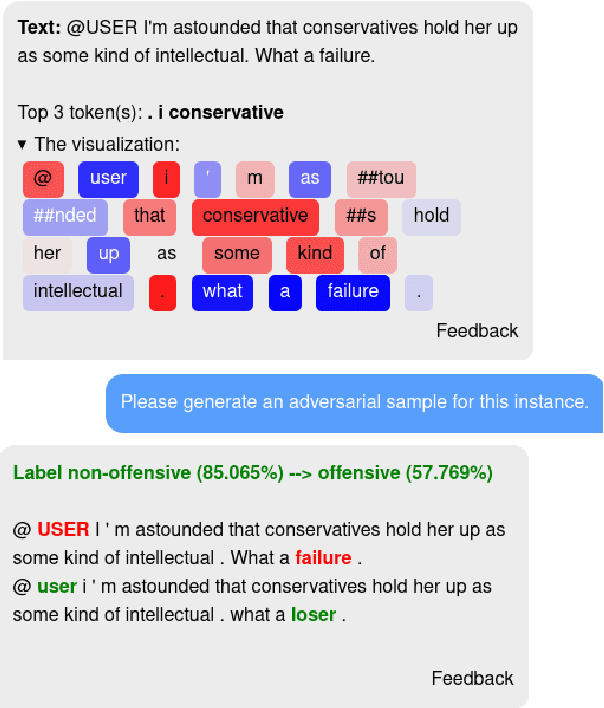
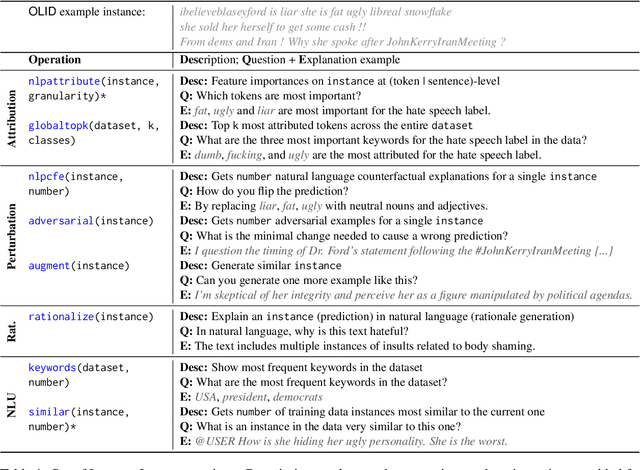
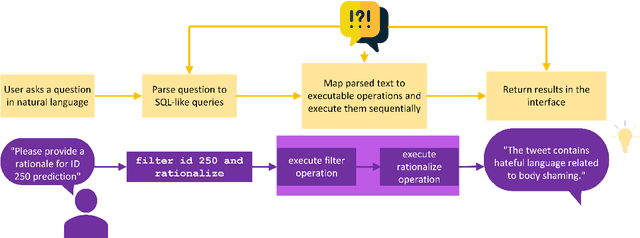
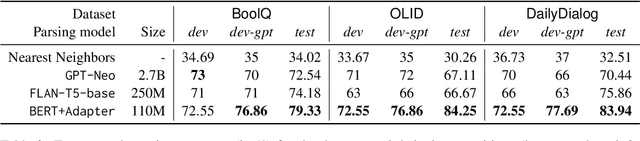
While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
MultiTACRED: A Multilingual Version of the TAC Relation Extraction Dataset
May 15, 2023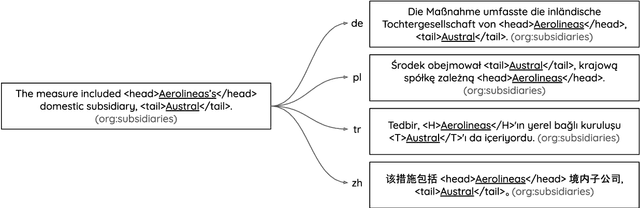
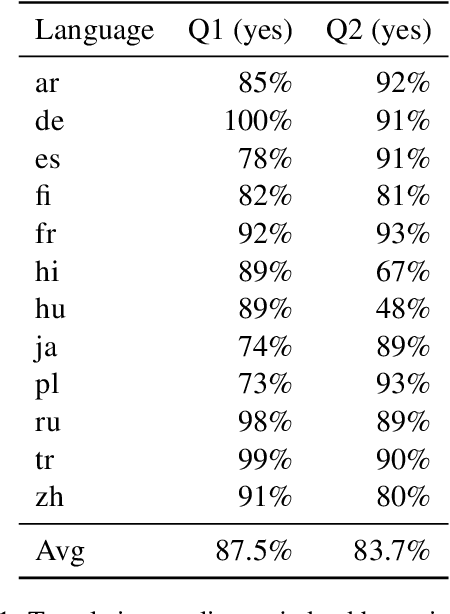


Relation extraction (RE) is a fundamental task in information extraction, whose extension to multilingual settings has been hindered by the lack of supervised resources comparable in size to large English datasets such as TACRED (Zhang et al., 2017). To address this gap, we introduce the MultiTACRED dataset, covering 12 typologically diverse languages from 9 language families, which is created by machine-translating TACRED instances and automatically projecting their entity annotations. We analyze translation and annotation projection quality, identify error categories, and experimentally evaluate fine-tuned pretrained mono- and multilingual language models in common transfer learning scenarios. Our analyses show that machine translation is a viable strategy to transfer RE instances, with native speakers judging more than 83% of the translated instances to be linguistically and semantically acceptable. We find monolingual RE model performance to be comparable to the English original for many of the target languages, and that multilingual models trained on a combination of English and target language data can outperform their monolingual counterparts. However, we also observe a variety of translation and annotation projection errors, both due to the MT systems and linguistic features of the target languages, such as pronoun-dropping, compounding and inflection, that degrade dataset quality and RE model performance.
Constructing Natural Language Explanations via Saliency Map Verbalization
Oct 13, 2022

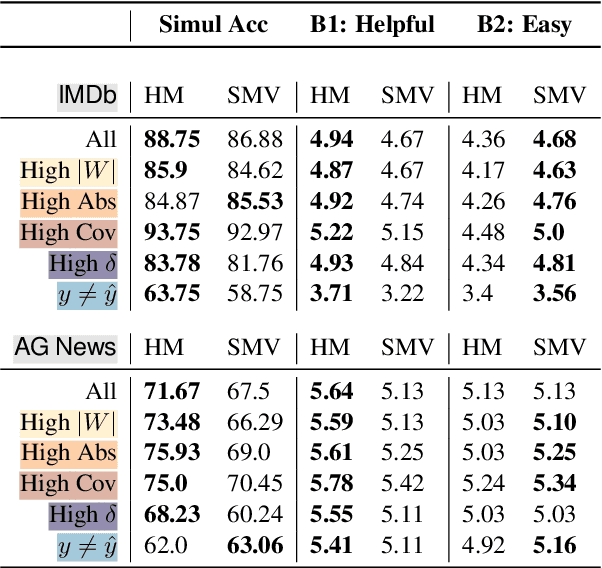
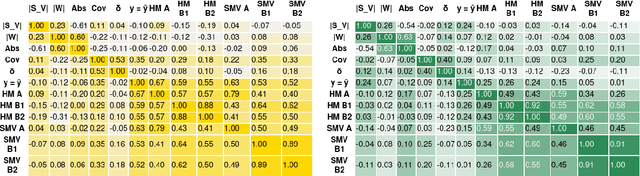
Saliency maps can explain a neural model's prediction by identifying important input features. While they excel in being faithful to the explained model, saliency maps in their entirety are difficult to interpret for humans, especially for instances with many input features. In contrast, natural language explanations (NLEs) are flexible and can be tuned to a recipient's expectations, but are costly to generate: Rationalization models are usually trained on specific tasks and require high-quality and diverse datasets of human annotations. We combine the advantages from both explainability methods by verbalizing saliency maps. We formalize this underexplored task and propose a novel methodology that addresses two key challenges of this approach -- what and how to verbalize. Our approach utilizes efficient search methods that are task- and model-agnostic and do not require another black-box model, and hand-crafted templates to preserve faithfulness. We conduct a human evaluation of explanation representations across two natural language processing (NLP) tasks: news topic classification and sentiment analysis. Our results suggest that saliency map verbalization makes explanations more understandable and less cognitively challenging to humans than conventional heatmap visualization.
Cross-lingual Approaches for the Detection of Adverse Drug Reactions in German from a Patient's Perspective
Aug 03, 2022
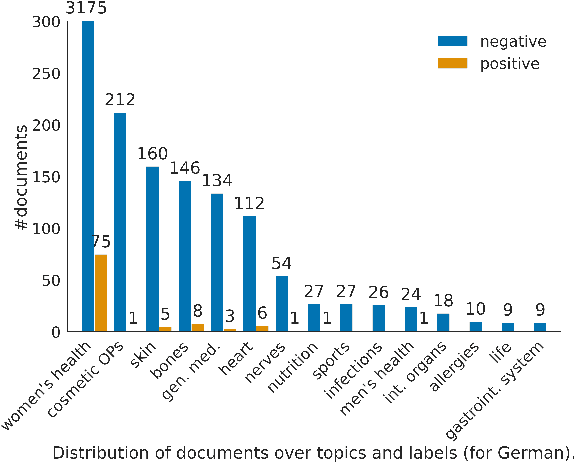

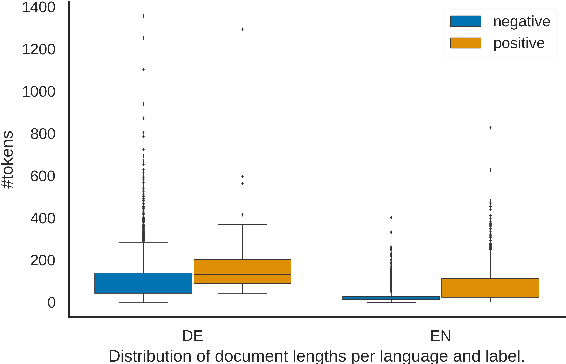
In this work, we present the first corpus for German Adverse Drug Reaction (ADR) detection in patient-generated content. The data consists of 4,169 binary annotated documents from a German patient forum, where users talk about health issues and get advice from medical doctors. As is common in social media data in this domain, the class labels of the corpus are very imbalanced. This and a high topic imbalance make it a very challenging dataset, since often, the same symptom can have several causes and is not always related to a medication intake. We aim to encourage further multi-lingual efforts in the domain of ADR detection and provide preliminary experiments for binary classification using different methods of zero- and few-shot learning based on a multi-lingual model. When fine-tuning XLM-RoBERTa first on English patient forum data and then on the new German data, we achieve an F1-score of 37.52 for the positive class. We make the dataset and models publicly available for the community.
A Transfer Learning Based Model for Text Readability Assessment in German
Jul 13, 2022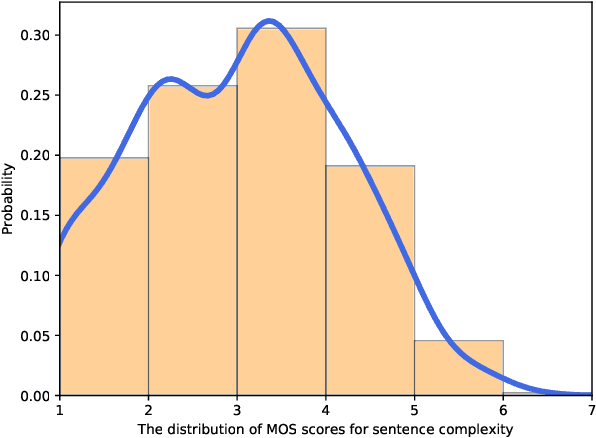
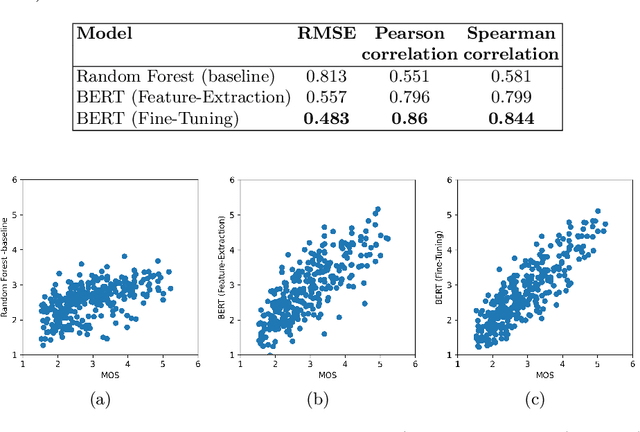
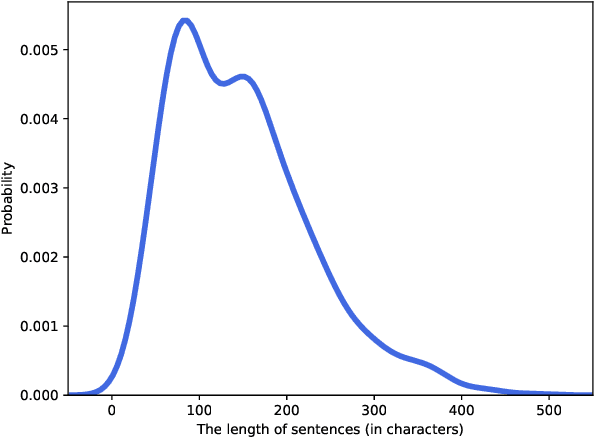
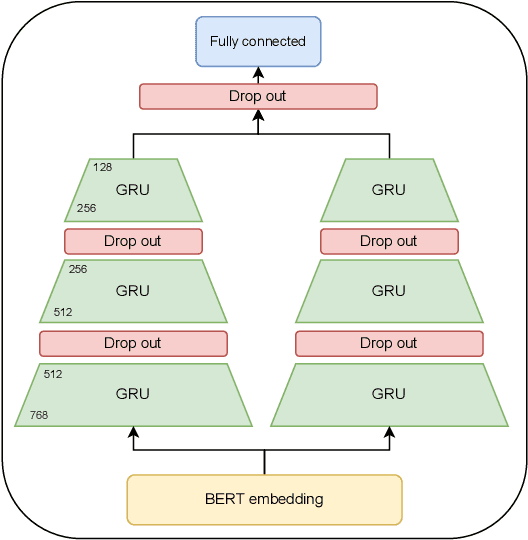
Text readability assessment has a wide range of applications for different target people, from language learners to people with disabilities. The fast pace of textual content production on the web makes it impossible to measure text complexity without the benefit of machine learning and natural language processing techniques. Although various research addressed the readability assessment of English text in recent years, there is still room for improvement of the models for other languages. In this paper, we proposed a new model for text complexity assessment for German text based on transfer learning. Our results show that the model outperforms more classical solutions based on linguistic features extraction from input text. The best model is based on the BERT pre-trained language model achieved the Root Mean Square Error (RMSE) of 0.483.