 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTatiana Anikina
LLMCheckup: Conversational Examination of Large Language Models via Interpretability Tools
Jan 23, 2024
Interpretability tools that offer explanations in the form of a dialogue have demonstrated their efficacy in enhancing users' understanding, as one-off explanations may occasionally fall short in providing sufficient information to the user. Current solutions for dialogue-based explanations, however, require many dependencies and are not easily transferable to tasks they were not designed for. With LLMCheckup, we present an easily accessible tool that allows users to chat with any state-of-the-art large language model (LLM) about its behavior. We enable LLMs to generate all explanations by themselves and take care of intent recognition without fine-tuning, by connecting them with a broad spectrum of Explainable AI (XAI) tools, e.g. feature attributions, embedding-based similarity, and prompting strategies for counterfactual and rationale generation. LLM (self-)explanations are presented as an interactive dialogue that supports follow-up questions and generates suggestions. LLMCheckup provides tutorials for operations available in the system, catering to individuals with varying levels of expertise in XAI and supports multiple input modalities. We introduce a new parsing strategy called multi-prompt parsing substantially enhancing the parsing accuracy of LLMs. Finally, we showcase the tasks of fact checking and commonsense question answering.
InterroLang: Exploring NLP Models and Datasets through Dialogue-based Explanations
Oct 23, 2023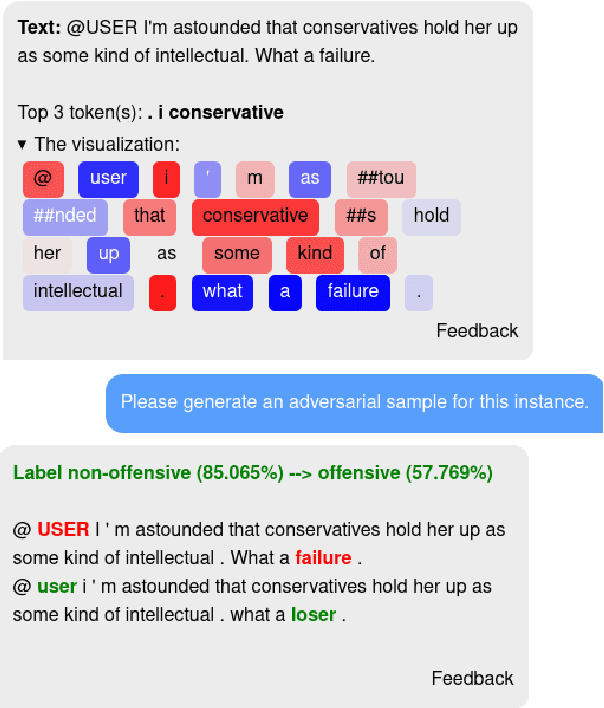
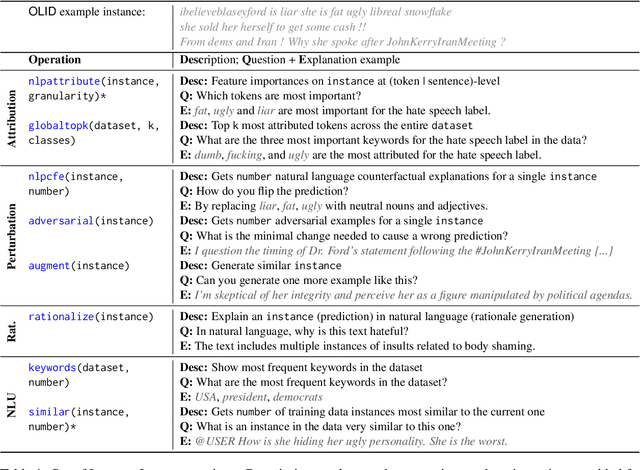
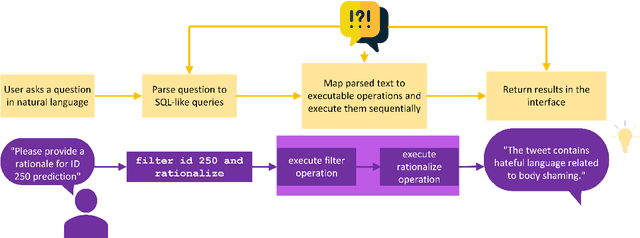
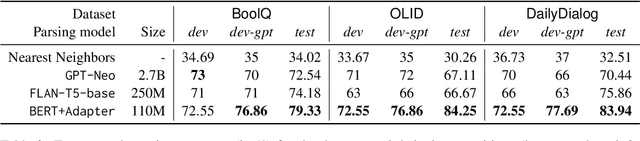
While recently developed NLP explainability methods let us open the black box in various ways (Madsen et al., 2022), a missing ingredient in this endeavor is an interactive tool offering a conversational interface. Such a dialogue system can help users explore datasets and models with explanations in a contextualized manner, e.g. via clarification or follow-up questions, and through a natural language interface. We adapt the conversational explanation framework TalkToModel (Slack et al., 2022) to the NLP domain, add new NLP-specific operations such as free-text rationalization, and illustrate its generalizability on three NLP tasks (dialogue act classification, question answering, hate speech detection). To recognize user queries for explanations, we evaluate fine-tuned and few-shot prompting models and implement a novel Adapter-based approach. We then conduct two user studies on (1) the perceived correctness and helpfulness of the dialogues, and (2) the simulatability, i.e. how objectively helpful dialogical explanations are for humans in figuring out the model's predicted label when it's not shown. We found rationalization and feature attribution were helpful in explaining the model behavior. Moreover, users could more reliably predict the model outcome based on an explanation dialogue rather than one-off explanations.
Anaphora Resolution in Dialogue: System Description (CODI-CRAC 2022 Shared Task)
Jan 05, 2023



We describe three models submitted for the CODI-CRAC 2022 shared task. To perform identity anaphora resolution, we test several combinations of the incremental clustering approach based on the Workspace Coreference System (WCS) with other coreference models. The best result is achieved by adding the ''cluster merging'' version of the coref-hoi model, which brings up to 10.33% improvement 1 over vanilla WCS clustering. Discourse deixis resolution is implemented as multi-task learning: we combine the learning objective of corefhoi with anaphor type classification. We adapt the higher-order resolution model introduced in Joshi et al. (2019) for bridging resolution given gold mentions and anaphors.