 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShaokui Wei
BackdoorBench: A Comprehensive Benchmark and Analysis of Backdoor Learning
Jan 26, 2024
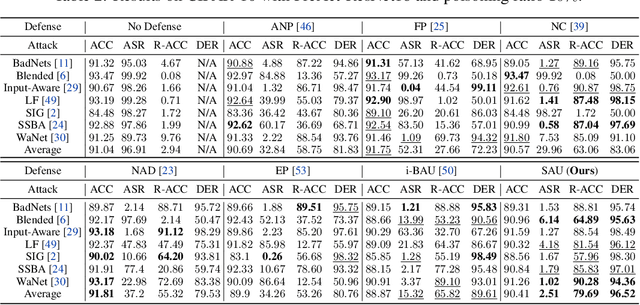
As an emerging and vital topic for studying deep neural networks' vulnerability (DNNs), backdoor learning has attracted increasing interest in recent years, and many seminal backdoor attack and defense algorithms are being developed successively or concurrently, in the status of a rapid arms race. However, mainly due to the diverse settings, and the difficulties of implementation and reproducibility of existing works, there is a lack of a unified and standardized benchmark of backdoor learning, causing unfair comparisons, and unreliable conclusions (e.g., misleading, biased or even false conclusions). Consequently, it is difficult to evaluate the current progress and design the future development roadmap of this literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning called BackdoorBench. Our benchmark makes three valuable contributions to the research community. 1) We provide an integrated implementation of state-of-the-art (SOTA) backdoor learning algorithms (currently including 16 attack and 27 defense algorithms), based on an extensible modular-based codebase. 2) We conduct comprehensive evaluations of 12 attacks against 16 defenses, with 5 poisoning ratios, based on 4 models and 4 datasets, thus 11,492 pairs of evaluations in total. 3) Based on above evaluations, we present abundant analysis from 8 perspectives via 18 useful analysis tools, and provide several inspiring insights about backdoor learning. We hope that our efforts could build a solid foundation of backdoor learning to facilitate researchers to investigate existing algorithms, develop more innovative algorithms, and explore the intrinsic mechanism of backdoor learning. Finally, we have created a user-friendly website at http://backdoorbench.com, which collects all important information of BackdoorBench, including codebase, docs, leaderboard, and model Zoo.
Defenses in Adversarial Machine Learning: A Survey
Dec 13, 2023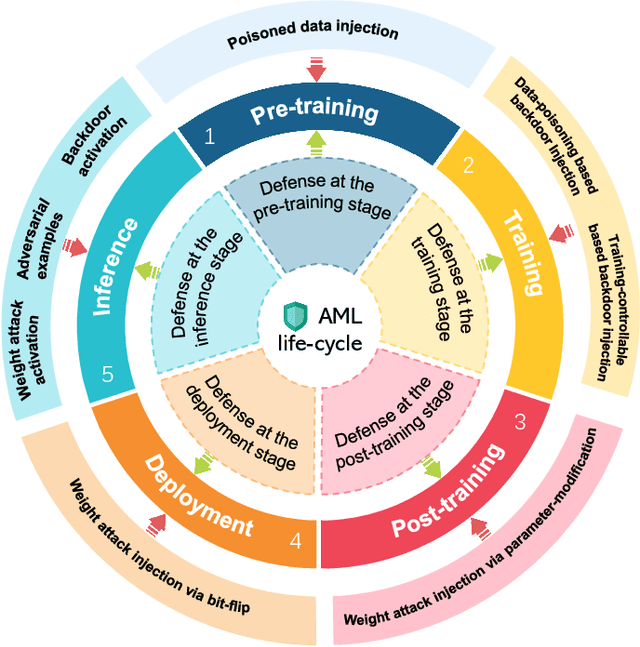
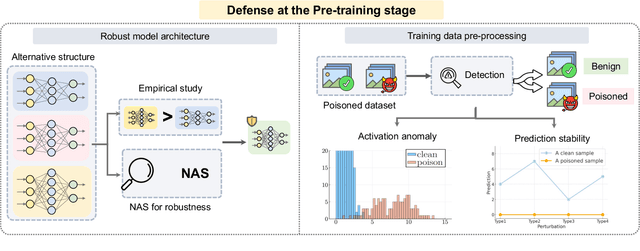
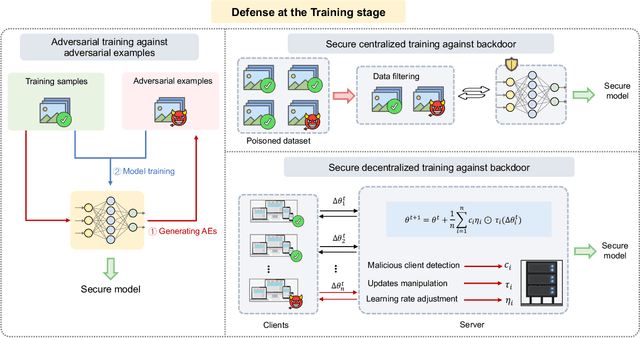
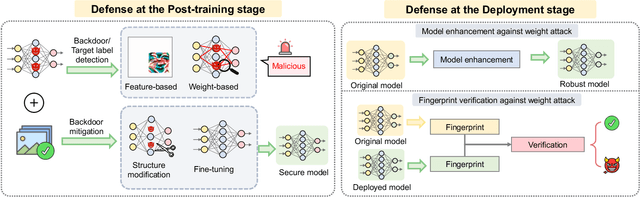
Adversarial phenomenon has been widely observed in machine learning (ML) systems, especially in those using deep neural networks, describing that ML systems may produce inconsistent and incomprehensible predictions with humans at some particular cases. This phenomenon poses a serious security threat to the practical application of ML systems, and several advanced attack paradigms have been developed to explore it, mainly including backdoor attacks, weight attacks, and adversarial examples. For each individual attack paradigm, various defense paradigms have been developed to improve the model robustness against the corresponding attack paradigm. However, due to the independence and diversity of these defense paradigms, it is difficult to examine the overall robustness of an ML system against different kinds of attacks.This survey aims to build a systematic review of all existing defense paradigms from a unified perspective. Specifically, from the life-cycle perspective, we factorize a complete machine learning system into five stages, including pre-training, training, post-training, deployment, and inference stages, respectively. Then, we present a clear taxonomy to categorize and review representative defense methods at each individual stage. The unified perspective and presented taxonomies not only facilitate the analysis of the mechanism of each defense paradigm but also help us to understand connections and differences among different defense paradigms, which may inspire future research to develop more advanced, comprehensive defenses.
VDC: Versatile Data Cleanser for Detecting Dirty Samples via Visual-Linguistic Inconsistency
Sep 28, 2023The role of data in building AI systems has recently been emphasized by the emerging concept of data-centric AI. Unfortunately, in the real-world, datasets may contain dirty samples, such as poisoned samples from backdoor attack, noisy labels in crowdsourcing, and even hybrids of them. The presence of such dirty samples makes the DNNs vunerable and unreliable.Hence, it is critical to detect dirty samples to improve the quality and realiability of dataset. Existing detectors only focus on detecting poisoned samples or noisy labels, that are often prone to weak generalization when dealing with dirty samples from other domains.In this paper, we find a commonality of various dirty samples is visual-linguistic inconsistency between images and associated labels. To capture the semantic inconsistency between modalities, we propose versatile data cleanser (VDC) leveraging the surpassing capabilities of multimodal large language models (MLLM) in cross-modal alignment and reasoning.It consists of three consecutive modules: the visual question generation module to generate insightful questions about the image; the visual question answering module to acquire the semantics of the visual content by answering the questions with MLLM; followed by the visual answer evaluation module to evaluate the inconsistency.Extensive experiments demonstrate its superior performance and generalization to various categories and types of dirty samples.
Shared Adversarial Unlearning: Backdoor Mitigation by Unlearning Shared Adversarial Examples
Jul 20, 2023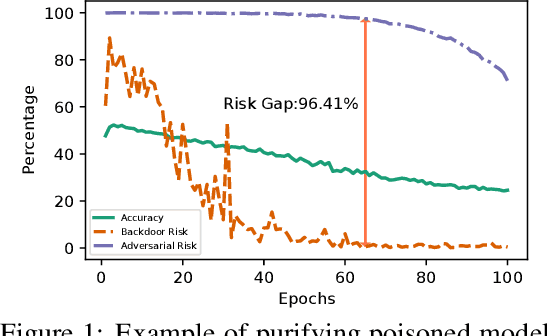

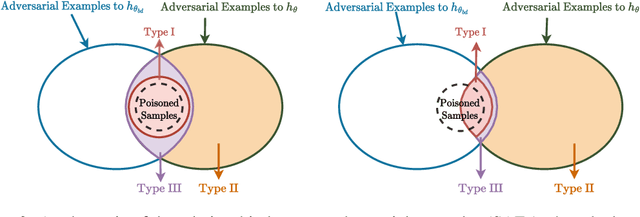
Backdoor attacks are serious security threats to machine learning models where an adversary can inject poisoned samples into the training set, causing a backdoored model which predicts poisoned samples with particular triggers to particular target classes, while behaving normally on benign samples. In this paper, we explore the task of purifying a backdoored model using a small clean dataset. By establishing the connection between backdoor risk and adversarial risk, we derive a novel upper bound for backdoor risk, which mainly captures the risk on the shared adversarial examples (SAEs) between the backdoored model and the purified model. This upper bound further suggests a novel bi-level optimization problem for mitigating backdoor using adversarial training techniques. To solve it, we propose Shared Adversarial Unlearning (SAU). Specifically, SAU first generates SAEs, and then, unlearns the generated SAEs such that they are either correctly classified by the purified model and/or differently classified by the two models, such that the backdoor effect in the backdoored model will be mitigated in the purified model. Experiments on various benchmark datasets and network architectures show that our proposed method achieves state-of-the-art performance for backdoor defense.
Boosting Backdoor Attack with A Learnable Poisoning Sample Selection Strategy
Jul 14, 2023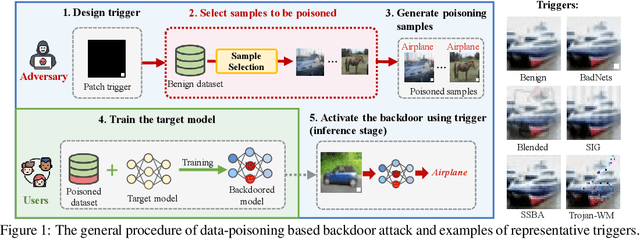
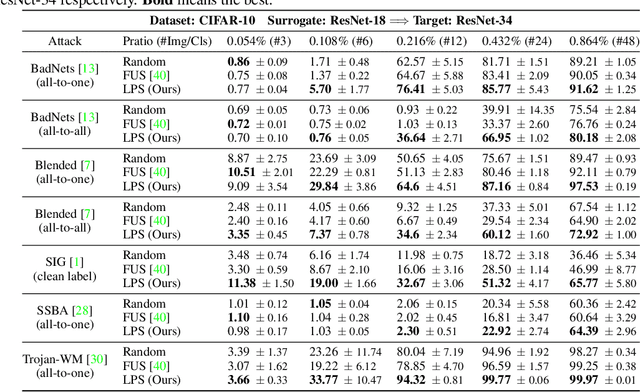
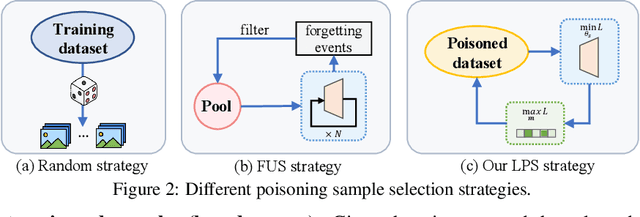
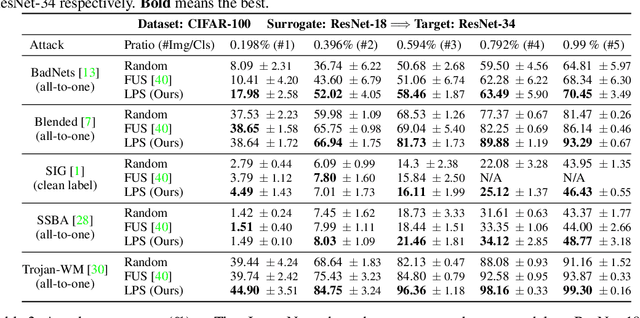
Data-poisoning based backdoor attacks aim to insert backdoor into models by manipulating training datasets without controlling the training process of the target model. Existing attack methods mainly focus on designing triggers or fusion strategies between triggers and benign samples. However, they often randomly select samples to be poisoned, disregarding the varying importance of each poisoning sample in terms of backdoor injection. A recent selection strategy filters a fixed-size poisoning sample pool by recording forgetting events, but it fails to consider the remaining samples outside the pool from a global perspective. Moreover, computing forgetting events requires significant additional computing resources. Therefore, how to efficiently and effectively select poisoning samples from the entire dataset is an urgent problem in backdoor attacks.To address it, firstly, we introduce a poisoning mask into the regular backdoor training loss. We suppose that a backdoored model training with hard poisoning samples has a more backdoor effect on easy ones, which can be implemented by hindering the normal training process (\ie, maximizing loss \wrt mask). To further integrate it with normal training process, we then propose a learnable poisoning sample selection strategy to learn the mask together with the model parameters through a min-max optimization.Specifically, the outer loop aims to achieve the backdoor attack goal by minimizing the loss based on the selected samples, while the inner loop selects hard poisoning samples that impede this goal by maximizing the loss. After several rounds of adversarial training, we finally select effective poisoning samples with high contribution. Extensive experiments on benchmark datasets demonstrate the effectiveness and efficiency of our approach in boosting backdoor attack performance.
Neural Polarizer: A Lightweight and Effective Backdoor Defense via Purifying Poisoned Features
Jun 29, 2023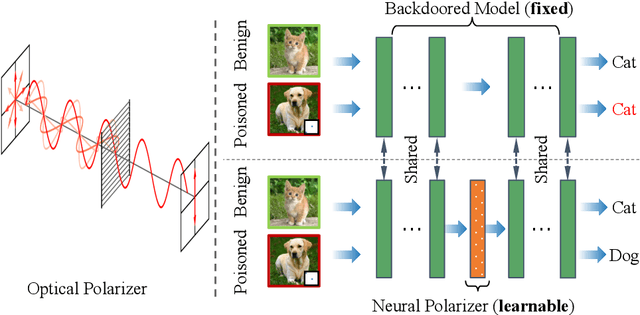
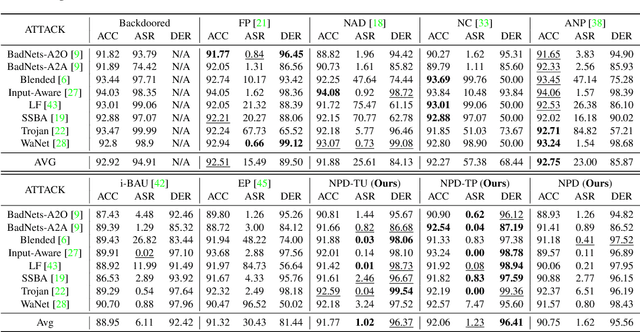
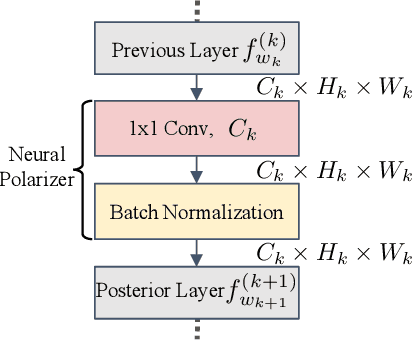
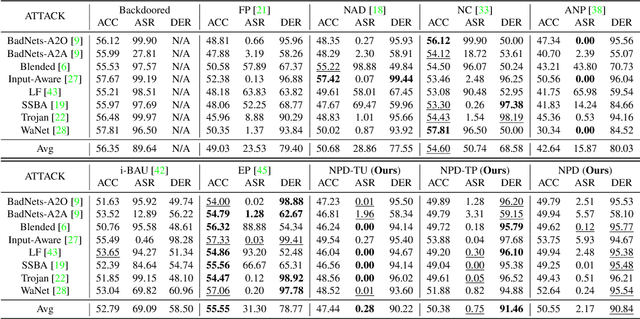
Recent studies have demonstrated the susceptibility of deep neural networks to backdoor attacks. Given a backdoored model, its prediction of a poisoned sample with trigger will be dominated by the trigger information, though trigger information and benign information coexist. Inspired by the mechanism of the optical polarizer that a polarizer could pass light waves with particular polarizations while filtering light waves with other polarizations, we propose a novel backdoor defense method by inserting a learnable neural polarizer into the backdoored model as an intermediate layer, in order to purify the poisoned sample via filtering trigger information while maintaining benign information. The neural polarizer is instantiated as one lightweight linear transformation layer, which is learned through solving a well designed bi-level optimization problem, based on a limited clean dataset. Compared to other fine-tuning-based defense methods which often adjust all parameters of the backdoored model, the proposed method only needs to learn one additional layer, such that it is more efficient and requires less clean data. Extensive experiments demonstrate the effectiveness and efficiency of our method in removing backdoors across various neural network architectures and datasets, especially in the case of very limited clean data.
Enhancing Fine-Tuning Based Backdoor Defense with Sharpness-Aware Minimization
Apr 24, 2023



Backdoor defense, which aims to detect or mitigate the effect of malicious triggers introduced by attackers, is becoming increasingly critical for machine learning security and integrity. Fine-tuning based on benign data is a natural defense to erase the backdoor effect in a backdoored model. However, recent studies show that, given limited benign data, vanilla fine-tuning has poor defense performance. In this work, we provide a deep study of fine-tuning the backdoored model from the neuron perspective and find that backdoorrelated neurons fail to escape the local minimum in the fine-tuning process. Inspired by observing that the backdoorrelated neurons often have larger norms, we propose FTSAM, a novel backdoor defense paradigm that aims to shrink the norms of backdoor-related neurons by incorporating sharpness-aware minimization with fine-tuning. We demonstrate the effectiveness of our method on several benchmark datasets and network architectures, where it achieves state-of-the-art defense performance. Overall, our work provides a promising avenue for improving the robustness of machine learning models against backdoor attacks.
Mean Parity Fair Regression in RKHS
Feb 21, 2023



We study the fair regression problem under the notion of Mean Parity (MP) fairness, which requires the conditional mean of the learned function output to be constant with respect to the sensitive attributes. We address this problem by leveraging reproducing kernel Hilbert space (RKHS) to construct the functional space whose members are guaranteed to satisfy the fairness constraints. The proposed functional space suggests a closed-form solution for the fair regression problem that is naturally compatible with multiple sensitive attributes. Furthermore, by formulating the fairness-accuracy tradeoff as a relaxed fair regression problem, we derive a corresponding regression function that can be implemented efficiently and provides interpretable tradeoffs. More importantly, under some mild assumptions, the proposed method can be applied to regression problems with a covariance-based notion of fairness. Experimental results on benchmark datasets show the proposed methods achieve competitive and even superior performance compared with several state-of-the-art methods.
BackdoorBench: A Comprehensive Benchmark of Backdoor Learning
Jun 25, 2022



Backdoor learning is an emerging and important topic of studying the vulnerability of deep neural networks (DNNs). Many pioneering backdoor attack and defense methods are being proposed successively or concurrently, in the status of a rapid arms race. However, we find that the evaluations of new methods are often unthorough to verify their claims and real performance, mainly due to the rapid development, diverse settings, as well as the difficulties of implementation and reproducibility. Without thorough evaluations and comparisons, it is difficult to track the current progress and design the future development roadmap of the literature. To alleviate this dilemma, we build a comprehensive benchmark of backdoor learning, called BackdoorBench. It consists of an extensible modular based codebase (currently including implementations of 8 state-of-the-art (SOTA) attack and 9 SOTA defense algorithms), as well as a standardized protocol of a complete backdoor learning. We also provide comprehensive evaluations of every pair of 8 attacks against 9 defenses, with 5 poisoning ratios, based on 5 models and 4 datasets, thus 8,000 pairs of evaluations in total. We further present analysis from different perspectives about these 8,000 evaluations, studying the effects of attack against defense algorithms, poisoning ratio, model and dataset in backdoor learning. All codes and evaluations of BackdoorBench are publicly available at \url{https://backdoorbench.github.io}.