 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShawn Xu
ELIXR: Towards a general purpose X-ray artificial intelligence system through alignment of large language models and radiology vision encoders
Aug 02, 2023
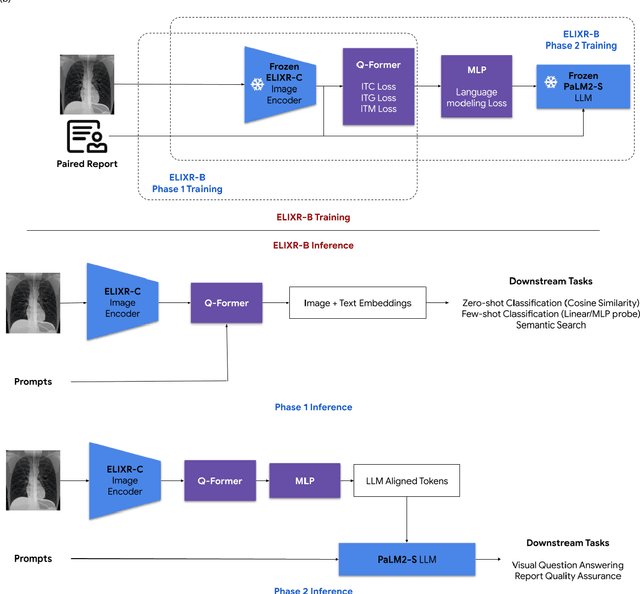
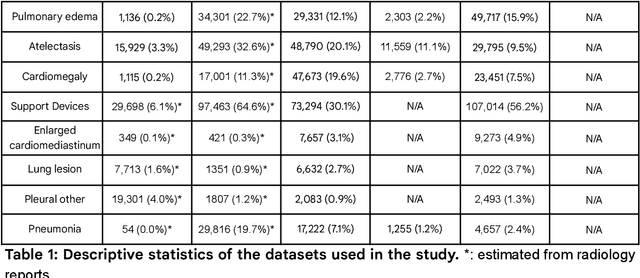
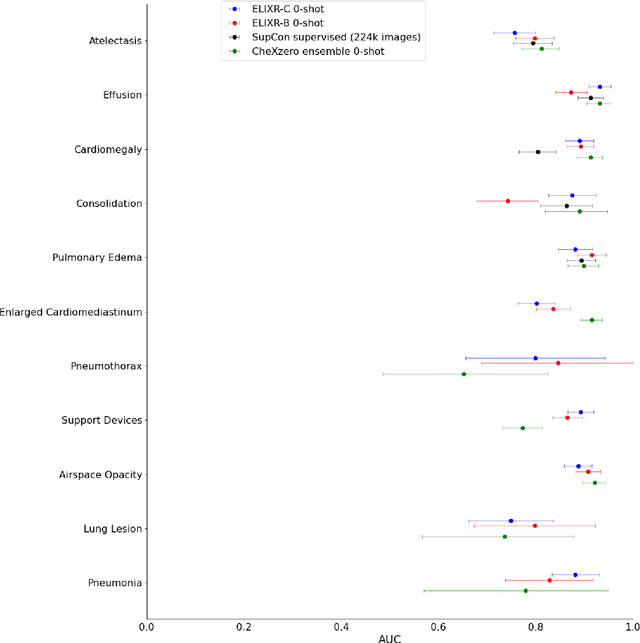
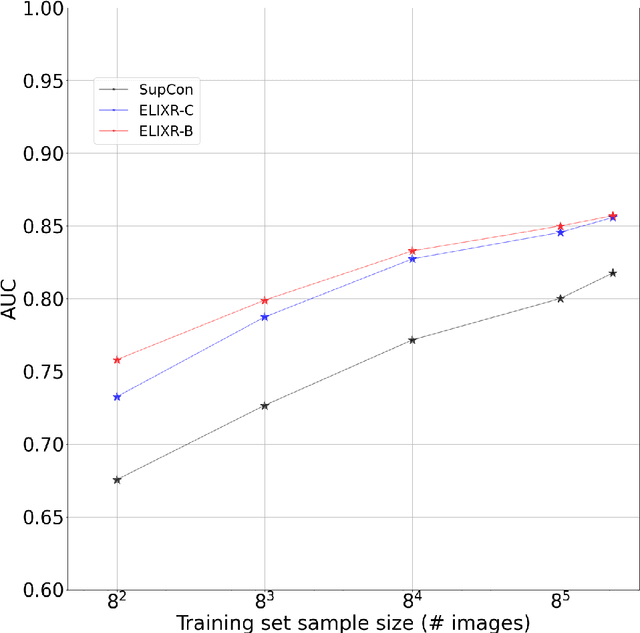
Our approach, which we call Embeddings for Language/Image-aligned X-Rays, or ELIXR, leverages a language-aligned image encoder combined or grafted onto a fixed LLM, PaLM 2, to perform a broad range of tasks. We train this lightweight adapter architecture using images paired with corresponding free-text radiology reports from the MIMIC-CXR dataset. ELIXR achieved state-of-the-art performance on zero-shot chest X-ray (CXR) classification (mean AUC of 0.850 across 13 findings), data-efficient CXR classification (mean AUCs of 0.893 and 0.898 across five findings (atelectasis, cardiomegaly, consolidation, pleural effusion, and pulmonary edema) for 1% (~2,200 images) and 10% (~22,000 images) training data), and semantic search (0.76 normalized discounted cumulative gain (NDCG) across nineteen queries, including perfect retrieval on twelve of them). Compared to existing data-efficient methods including supervised contrastive learning (SupCon), ELIXR required two orders of magnitude less data to reach similar performance. ELIXR also showed promise on CXR vision-language tasks, demonstrating overall accuracies of 58.7% and 62.5% on visual question answering and report quality assurance tasks, respectively. These results suggest that ELIXR is a robust and versatile approach to CXR AI.
Attribution in Scale and Space
Apr 08, 2020
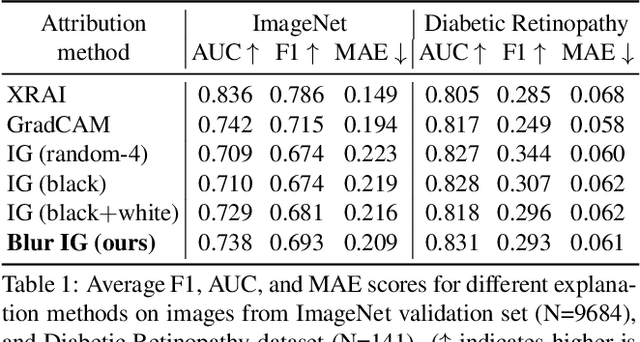
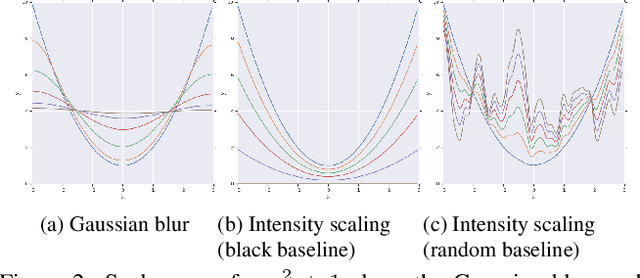
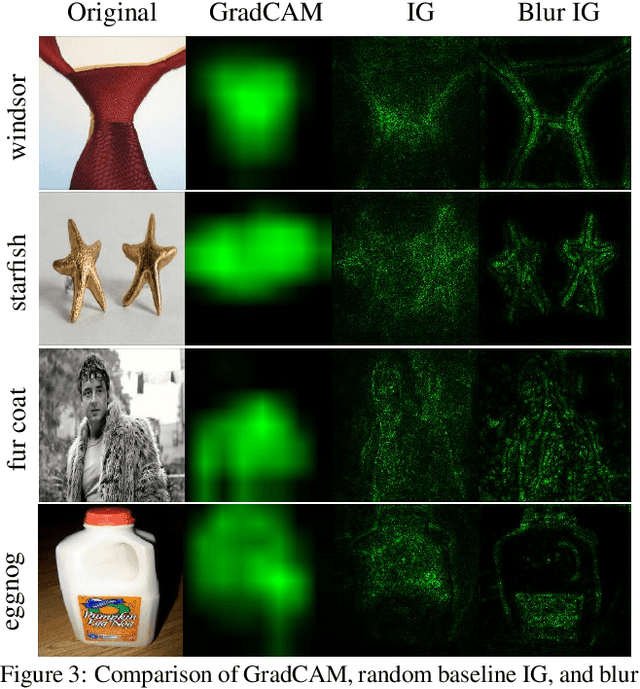
We study the attribution problem [28] for deep networks applied to perception tasks. For vision tasks, attribution techniques attribute the prediction of a network to the pixels of the input image. We propose a new technique called \emph{Blur Integrated Gradients}. This technique has several advantages over other methods. First, it can tell at what scale a network recognizes an object. It produces scores in the scale/frequency dimension, that we find captures interesting phenomena. Second, it satisfies the scale-space axioms [14], which imply that it employs perturbations that are free of artifact. We therefore produce explanations that are cleaner and consistent with the operation of deep networks. Third, it eliminates the need for a 'baseline' parameter for Integrated Gradients [31] for perception tasks. This is desirable because the choice of baseline has a significant effect on the explanations. We compare the proposed technique against previous techniques and demonstrate application on three tasks: ImageNet object recognition, Diabetic Retinopathy prediction, and AudioSet audio event identification.