 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSheng Zhong
IMU-Aided Event-based Stereo Visual Odometry
May 07, 2024
Direct methods for event-based visual odometry solve the mapping and camera pose tracking sub-problems by establishing implicit data association in a way that the generative model of events is exploited. The main bottlenecks faced by state-of-the-art work in this field include the high computational complexity of mapping and the limited accuracy of tracking. In this paper, we improve our previous direct pipeline \textit{Event-based Stereo Visual Odometry} in terms of accuracy and efficiency. To speed up the mapping operation, we propose an efficient strategy of edge-pixel sampling according to the local dynamics of events. The mapping performance in terms of completeness and local smoothness is also improved by combining the temporal stereo results and the static stereo results. To circumvent the degeneracy issue of camera pose tracking in recovering the yaw component of general 6-DoF motion, we introduce as a prior the gyroscope measurements via pre-integration. Experiments on publicly available datasets justify our improvement. We release our pipeline as an open-source software for future research in this field.
Subtoxic Questions: Dive Into Attitude Change of LLM's Response in Jailbreak Attempts
Apr 12, 2024As Large Language Models (LLMs) of Prompt Jailbreaking are getting more and more attention, it is of great significance to raise a generalized research paradigm to evaluate attack strengths and a basic model to conduct subtler experiments. In this paper, we propose a novel approach by focusing on a set of target questions that are inherently more sensitive to jailbreak prompts, aiming to circumvent the limitations posed by enhanced LLM security. Through designing and analyzing these sensitive questions, this paper reveals a more effective method of identifying vulnerabilities in LLMs, thereby contributing to the advancement of LLM security. This research not only challenges existing jailbreaking methodologies but also fortifies LLMs against potential exploits.
Powerful Lossy Compression for Noisy Images
Mar 26, 2024
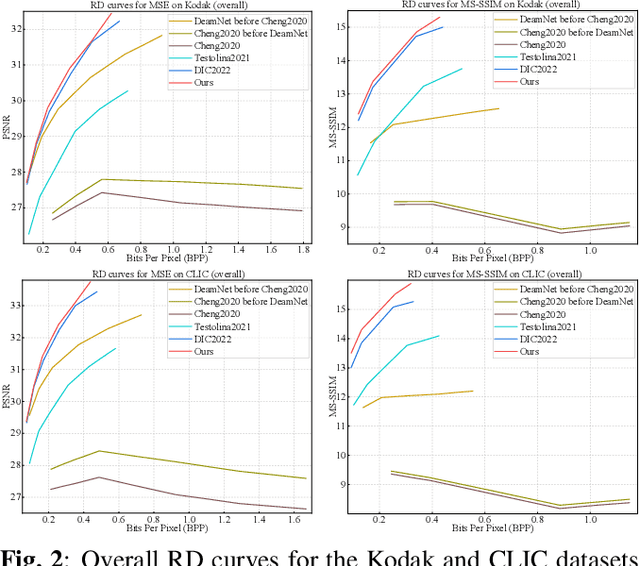
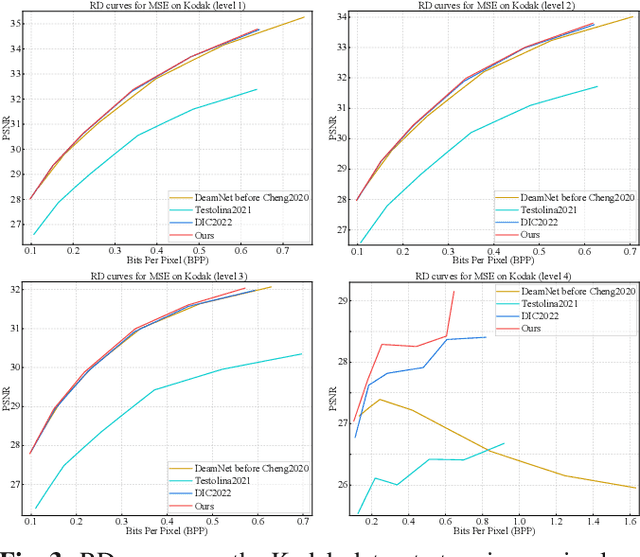

Image compression and denoising represent fundamental challenges in image processing with many real-world applications. To address practical demands, current solutions can be categorized into two main strategies: 1) sequential method; and 2) joint method. However, sequential methods have the disadvantage of error accumulation as there is information loss between multiple individual models. Recently, the academic community began to make some attempts to tackle this problem through end-to-end joint methods. Most of them ignore that different regions of noisy images have different characteristics. To solve these problems, in this paper, our proposed signal-to-noise ratio~(SNR) aware joint solution exploits local and non-local features for image compression and denoising simultaneously. We design an end-to-end trainable network, which includes the main encoder branch, the guidance branch, and the signal-to-noise ratio~(SNR) aware branch. We conducted extensive experiments on both synthetic and real-world datasets, demonstrating that our joint solution outperforms existing state-of-the-art methods.
Dual-Space Optimization: Improved Molecule Sequence Design by Latent Prompt Transformer
Feb 27, 2024Designing molecules with desirable properties, such as drug-likeliness and high binding affinities towards protein targets, is a challenging problem. In this paper, we propose the Dual-Space Optimization (DSO) method that integrates latent space sampling and data space selection to solve this problem. DSO iteratively updates a latent space generative model and a synthetic dataset in an optimization process that gradually shifts the generative model and the synthetic data towards regions of desired property values. Our generative model takes the form of a Latent Prompt Transformer (LPT) where the latent vector serves as the prompt of a causal transformer. Our extensive experiments demonstrate effectiveness of the proposed method, which sets new performance benchmarks across single-objective, multi-objective and constrained molecule design tasks.
A Grammatical Compositional Model for Video Action Detection
Oct 04, 2023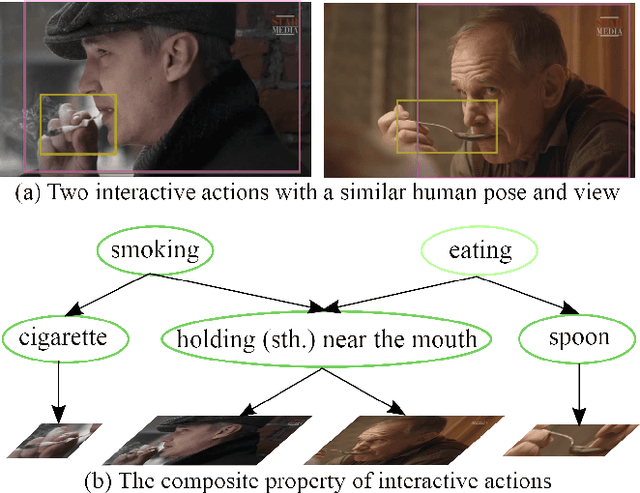

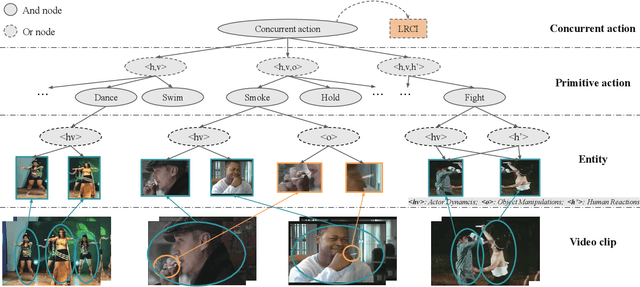

Analysis of human actions in videos demands understanding complex human dynamics, as well as the interaction between actors and context. However, these interaction relationships usually exhibit large intra-class variations from diverse human poses or object manipulations, and fine-grained inter-class differences between similar actions. Thus the performance of existing methods is severely limited. Motivated by the observation that interactive actions can be decomposed into actor dynamics and participating objects or humans, we propose to investigate the composite property of them. In this paper, we present a novel Grammatical Compositional Model (GCM) for action detection based on typical And-Or graphs. Our model exploits the intrinsic structures and latent relationships of actions in a hierarchical manner to harness both the compositionality of grammar models and the capability of expressing rich features of DNNs. The proposed model can be readily embodied into a neural network module for efficient optimization in an end-to-end manner. Extensive experiments are conducted on the AVA dataset and the Something-Else task to demonstrate the superiority of our model, meanwhile the interpretability is enhanced through an inference parsing procedure.
Jointly Optimizing Image Compression with Low-light Image Enhancement
May 24, 2023
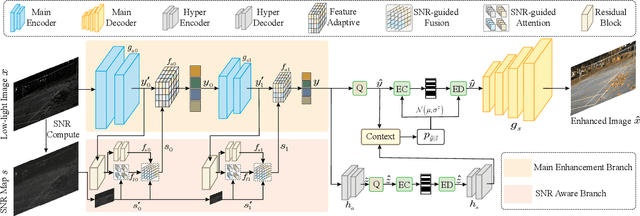
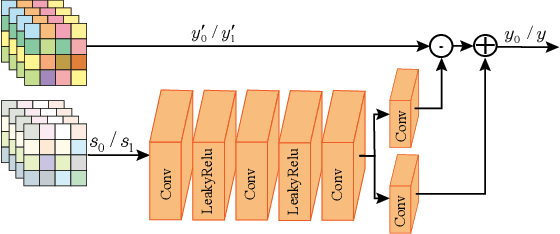
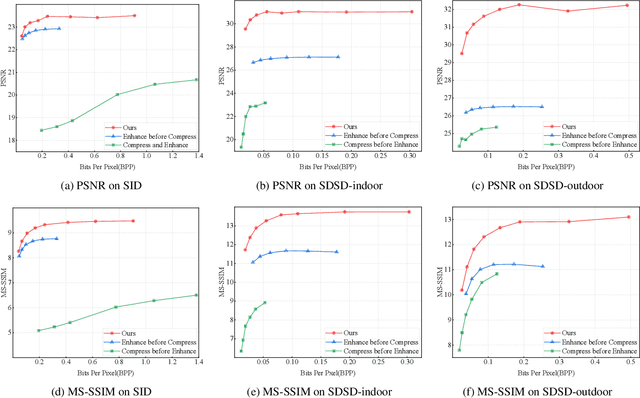
Learning-based image compression methods have made great progress. Most of them are designed for generic natural images. In fact, low-light images frequently occur due to unavoidable environmental influences or technical limitations, such as insufficient lighting or limited exposure time. %When general-purpose image compression algorithms compress low-light images, useful detail information is lost, resulting in a dramatic decrease in image enhancement. Once low-light images are compressed by existing general image compression approaches, useful information(e.g., texture details) would be lost resulting in a dramatic performance decrease in low-light image enhancement. To simultaneously achieve a higher compression rate and better enhancement performance for low-light images, we propose a novel image compression framework with joint optimization of low-light image enhancement. We design an end-to-end trainable two-branch architecture with lower computational cost, which includes the main enhancement branch and the signal-to-noise ratio~(SNR) aware branch. Experimental results show that our proposed joint optimization framework achieves a significant improvement over existing ``Compress before Enhance" or ``Enhance before Compress" sequential solutions for low-light images. Source codes are included in the supplementary material.
CHSEL: Producing Diverse Plausible Pose Estimates from Contact and Free Space Data
May 14, 2023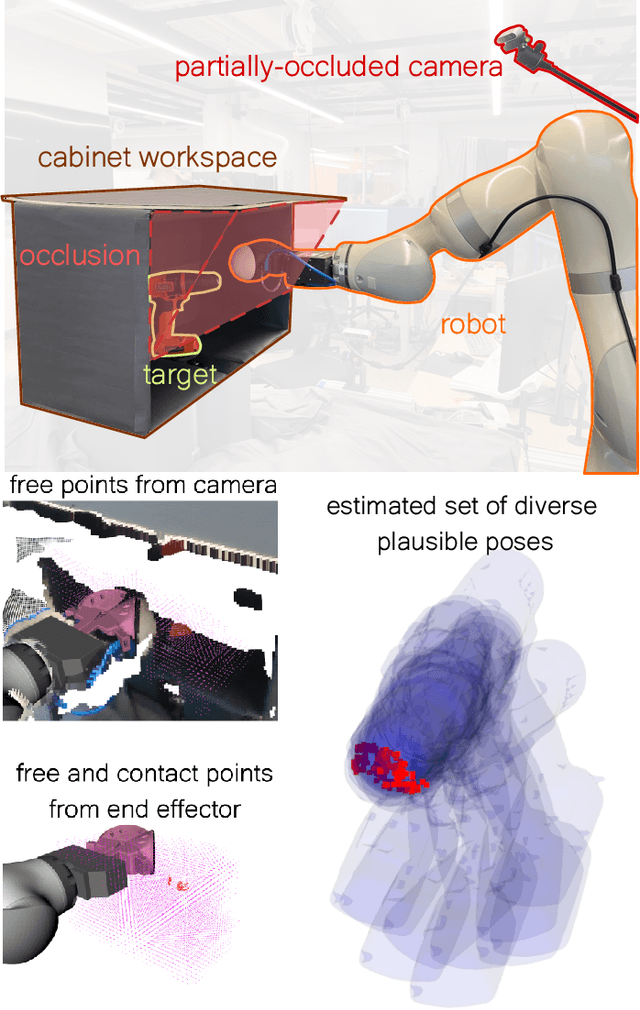
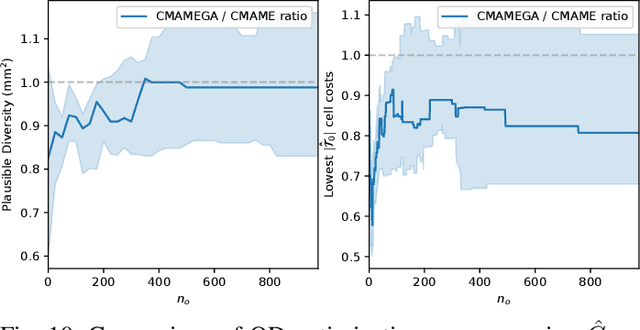
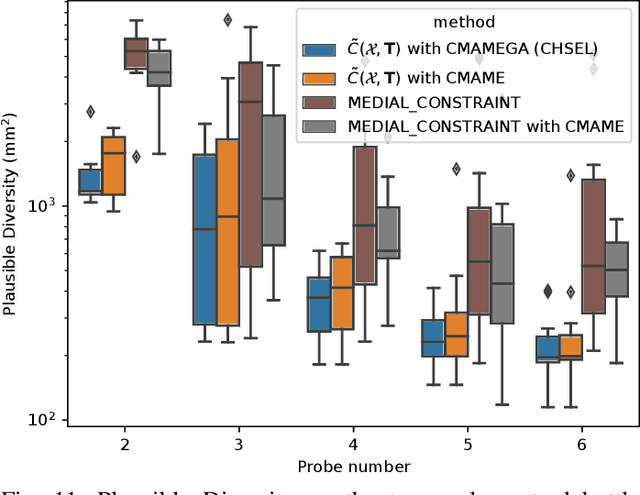
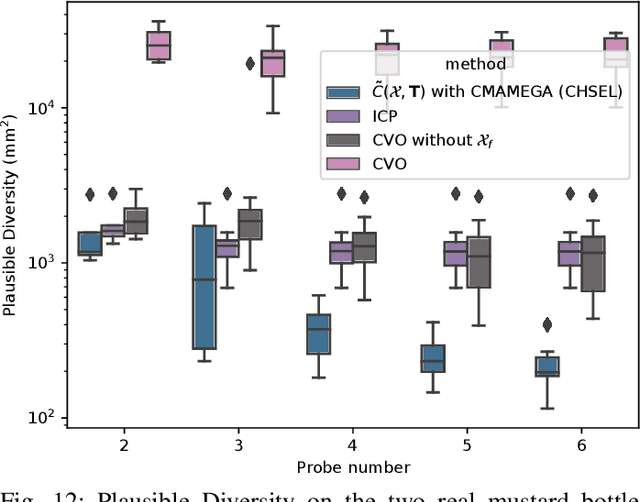
This paper proposes a novel method for estimating the set of plausible poses of a rigid object from a set of points with volumetric information, such as whether each point is in free space or on the surface of the object. In particular, we study how pose can be estimated from force and tactile data arising from contact. Using data derived from contact is challenging because it is inherently less information-dense than visual data, and thus the pose estimation problem is severely under-constrained when there are few contacts. Rather than attempting to estimate the true pose of the object, which is not tractable without a large number of contacts, we seek to estimate a plausible set of poses which obey the constraints imposed by the sensor data. Existing methods struggle to estimate this set because they are either designed for single pose estimates or require informative priors to be effective. Our approach to this problem, Constrained pose Hypothesis Set Elimination (CHSEL), has three key attributes: 1) It considers volumetric information, which allows us to account for known free space; 2) It uses a novel differentiable volumetric cost function to take advantage of powerful gradient-based optimization tools; and 3) It uses methods from the Quality Diversity (QD) optimization literature to produce a diverse set of high-quality poses. To our knowledge, QD methods have not been used previously for pose registration. We also show how to update our plausible pose estimates online as more data is gathered by the robot. Our experiments suggest that CHSEL shows large performance improvements over several baseline methods for both simulated and real-world data.
Secure Split Learning against Property Inference, Data Reconstruction, and Feature Space Hijacking Attacks
Apr 19, 2023



Split learning of deep neural networks (SplitNN) has provided a promising solution to learning jointly for the mutual interest of a guest and a host, which may come from different backgrounds, holding features partitioned vertically. However, SplitNN creates a new attack surface for the adversarial participant, holding back its practical use in the real world. By investigating the adversarial effects of highly threatening attacks, including property inference, data reconstruction, and feature hijacking attacks, we identify the underlying vulnerability of SplitNN and propose a countermeasure. To prevent potential threats and ensure the learning guarantees of SplitNN, we design a privacy-preserving tunnel for information exchange between the guest and the host. The intuition is to perturb the propagation of knowledge in each direction with a controllable unified solution. To this end, we propose a new activation function named R3eLU, transferring private smashed data and partial loss into randomized responses in forward and backward propagations, respectively. We give the first attempt to secure split learning against three threatening attacks and present a fine-grained privacy budget allocation scheme. The analysis proves that our privacy-preserving SplitNN solution provides a tight privacy budget, while the experimental results show that our solution performs better than existing solutions in most cases and achieves a good tradeoff between defense and model usability.
Formation Flight in Dense Environments
Oct 08, 2022
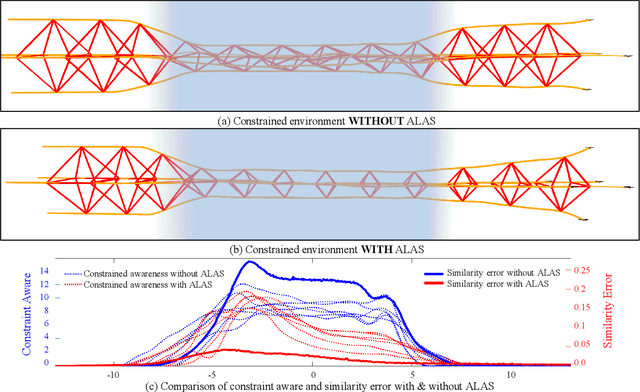
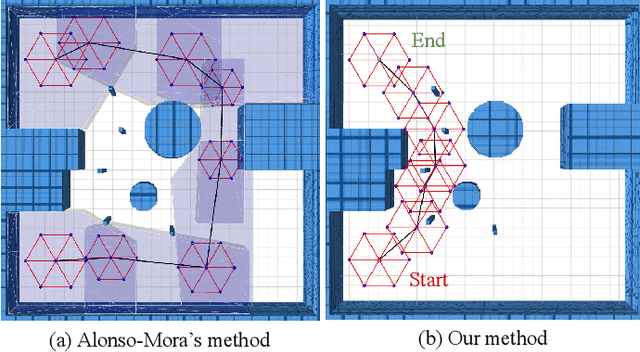
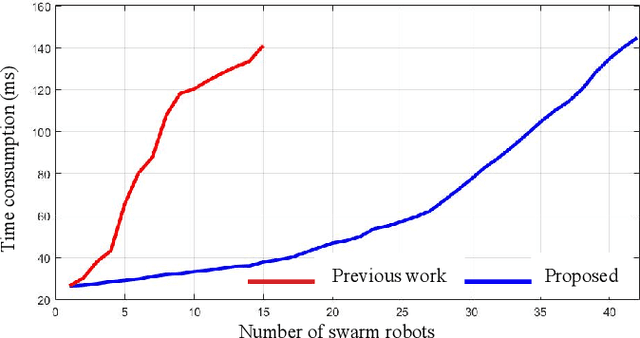
Formation flight has a vast potential for aerial robot swarms in various applications. However, existing methods lack the capability to achieve fully autonomous large-scale formation flight in dense environments. To bridge the gap, we present a complete formation flight system that effectively integrates real-world constraints into aerial formation navigation. This paper proposes a differentiable graph-based metric to quantify the overall similarity error between formations. This metric is invariant to rotation, translation, and scaling, providing more freedom for formation coordination. We design a distributed trajectory optimization framework that considers formation similarity, obstacle avoidance, and dynamic feasibility. The optimization is decoupled to make large-scale formation flights computationally feasible. To improve the elasticity of formation navigation in highly constrained scenes, we present a swarm reorganization method which adaptively adjusts the formation parameters and task assignments by generating local navigation goals. A novel swarm agreement strategy called global-remap-local-replan and a formation-level path planner is proposed in this work to coordinate the swarm global planning and local trajectory optimizations efficiently. To validate the proposed method, we design comprehensive benchmarks and simulations with other cutting-edge works in terms of adaptability, predictability, elasticity, resilience, and efficiency. Finally, integrated with palm-sized swarm platforms with onboard computers and sensors, the proposed method demonstrates its efficiency and robustness by achieving the largest scale formation flight in dense outdoor environments.
High-Fidelity Variable-Rate Image Compression via Invertible Activation Transformation
Sep 12, 2022
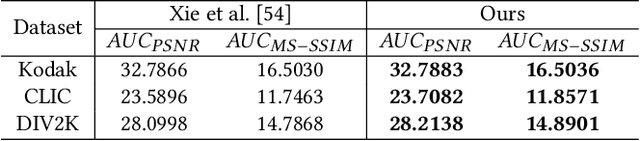
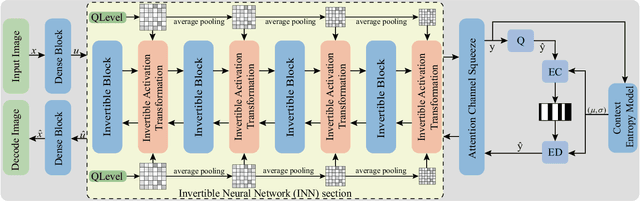
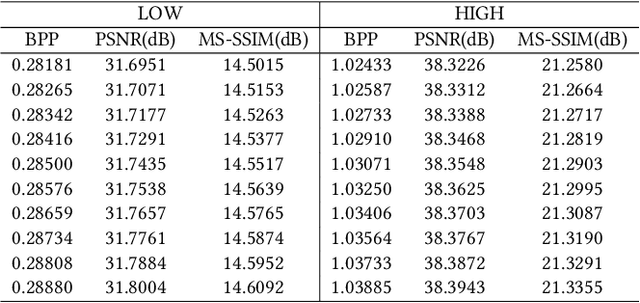
Learning-based methods have effectively promoted the community of image compression. Meanwhile, variational autoencoder (VAE) based variable-rate approaches have recently gained much attention to avoid the usage of a set of different networks for various compression rates. Despite the remarkable performance that has been achieved, these approaches would be readily corrupted once multiple compression/decompression operations are executed, resulting in the fact that image quality would be tremendously dropped and strong artifacts would appear. Thus, we try to tackle the issue of high-fidelity fine variable-rate image compression and propose the Invertible Activation Transformation (IAT) module. We implement the IAT in a mathematical invertible manner on a single rate Invertible Neural Network (INN) based model and the quality level (QLevel) would be fed into the IAT to generate scaling and bias tensors. IAT and QLevel together give the image compression model the ability of fine variable-rate control while better maintaining the image fidelity. Extensive experiments demonstrate that the single rate image compression model equipped with our IAT module has the ability to achieve variable-rate control without any compromise. And our IAT-embedded model obtains comparable rate-distortion performance with recent learning-based image compression methods. Furthermore, our method outperforms the state-of-the-art variable-rate image compression method by a large margin, especially after multiple re-encodings.