 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMingyang Wang
AAdaM at SemEval-2024 Task 1: Augmentation and Adaptation for Multilingual Semantic Textual Relatedness
Apr 01, 2024
This paper presents our system developed for the SemEval-2024 Task 1: Semantic Textual Relatedness for African and Asian Languages. The shared task aims at measuring the semantic textual relatedness between pairs of sentences, with a focus on a range of under-represented languages. In this work, we propose using machine translation for data augmentation to address the low-resource challenge of limited training data. Moreover, we apply task-adaptive pre-training on unlabeled task data to bridge the gap between pre-training and task adaptation. For model training, we investigate both full fine-tuning and adapter-based tuning, and adopt the adapter framework for effective zero-shot cross-lingual transfer. We achieve competitive results in the shared task: our system performs the best among all ranked teams in both subtask A (supervised learning) and subtask C (cross-lingual transfer).
Rehearsal-Free Modular and Compositional Continual Learning for Language Models
Mar 31, 2024Continual learning aims at incrementally acquiring new knowledge while not forgetting existing knowledge. To overcome catastrophic forgetting, methods are either rehearsal-based, i.e., store data examples from previous tasks for data replay, or isolate parameters dedicated to each task. However, rehearsal-based methods raise privacy and memory issues, and parameter-isolation continual learning does not consider interaction between tasks, thus hindering knowledge transfer. In this work, we propose MoCL, a rehearsal-free Modular and Compositional Continual Learning framework which continually adds new modules to language models and composes them with existing modules. Experiments on various benchmarks show that MoCL outperforms state of the art and effectively facilitates knowledge transfer.
The Impact of Demonstrations on Multilingual In-Context Learning: A Multidimensional Analysis
Feb 20, 2024In-context learning is a popular inference strategy where large language models solve a task using only a few labelled demonstrations without needing any parameter updates. Compared to work on monolingual (English) in-context learning, multilingual in-context learning is under-explored, and we lack an in-depth understanding of the role of demonstrations in this context. To address this gap, we conduct a multidimensional analysis of multilingual in-context learning, experimenting with 5 models from different model families, 9 datasets covering classification and generation tasks, and 56 typologically diverse languages. Our results reveal that the effectiveness of demonstrations varies significantly across models, tasks, and languages. We also find that Llama 2-Chat, GPT-3.5, and GPT-4 are largely insensitive to the quality of demonstrations. Instead, a carefully crafted template often eliminates the benefits of demonstrations for some tasks and languages altogether. These findings show that the importance of demonstrations might be overestimated. Our work highlights the need for granular evaluation across multiple axes towards a better understanding of in-context learning.
OFA: A Framework of Initializing Unseen Subword Embeddings for Efficient Large-scale Multilingual Continued Pretraining
Nov 15, 2023Pretraining multilingual language models from scratch requires considerable computational resources and substantial training data. Therefore, a more efficient method is to adapt existing pretrained language models (PLMs) to new languages via vocabulary extension and continued pretraining. However, this method usually randomly initializes the embeddings of new subwords and introduces substantially more embedding parameters to the language model, thus weakening the efficiency. To address these issues, we propose a novel framework: \textbf{O}ne \textbf{F}or \textbf{A}ll (\textbf{\textsc{Ofa}}), which wisely initializes the embeddings of unseen subwords from target languages and thus can adapt a PLM to multiple languages efficiently and effectively. \textsc{Ofa} takes advantage of external well-aligned multilingual word embeddings and injects the alignment knowledge into the new embeddings. In addition, \textsc{Ofa} applies matrix factorization and replaces the cumbersome embeddings with two lower-dimensional matrices, which significantly reduces the number of parameters while not sacrificing the performance. Through extensive experiments, we show models initialized by \textsc{Ofa} are efficient and outperform several baselines. \textsc{Ofa} not only accelerates the convergence of continued pretraining, which is friendly to a limited computation budget, but also improves the zero-shot crosslingual transfer on a wide range of downstream tasks. We make our code and models publicly available.
Interaction-Driven Active 3D Reconstruction with Object Interiors
Oct 23, 2023



We introduce an active 3D reconstruction method which integrates visual perception, robot-object interaction, and 3D scanning to recover both the exterior and interior, i.e., unexposed, geometries of a target 3D object. Unlike other works in active vision which focus on optimizing camera viewpoints to better investigate the environment, the primary feature of our reconstruction is an analysis of the interactability of various parts of the target object and the ensuing part manipulation by a robot to enable scanning of occluded regions. As a result, an understanding of part articulations of the target object is obtained on top of complete geometry acquisition. Our method operates fully automatically by a Fetch robot with built-in RGBD sensors. It iterates between interaction analysis and interaction-driven reconstruction, scanning and reconstructing detected moveable parts one at a time, where both the articulated part detection and mesh reconstruction are carried out by neural networks. In the final step, all the remaining, non-articulated parts, including all the interior structures that had been exposed by prior part manipulations and subsequently scanned, are reconstructed to complete the acquisition. We demonstrate the performance of our method via qualitative and quantitative evaluation, ablation studies, comparisons to alternatives, as well as experiments in a real environment.
GradSim: Gradient-Based Language Grouping for Effective Multilingual Training
Oct 23, 2023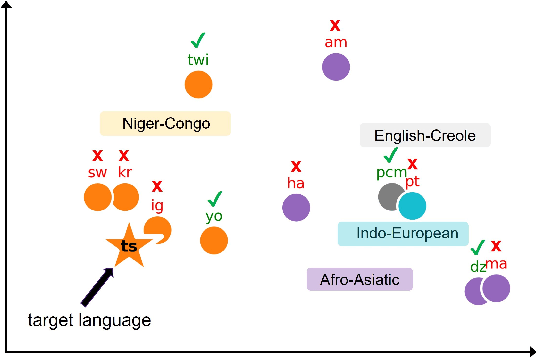
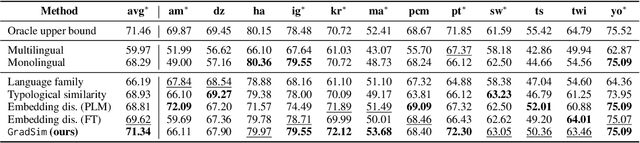

Most languages of the world pose low-resource challenges to natural language processing models. With multilingual training, knowledge can be shared among languages. However, not all languages positively influence each other and it is an open research question how to select the most suitable set of languages for multilingual training and avoid negative interference among languages whose characteristics or data distributions are not compatible. In this paper, we propose GradSim, a language grouping method based on gradient similarity. Our experiments on three diverse multilingual benchmark datasets show that it leads to the largest performance gains compared to other similarity measures and it is better correlated with cross-lingual model performance. As a result, we set the new state of the art on AfriSenti, a benchmark dataset for sentiment analysis on low-resource African languages. In our extensive analysis, we further reveal that besides linguistic features, the topics of the datasets play an important role for language grouping and that lower layers of transformer models encode language-specific features while higher layers capture task-specific information.
Meta-Reinforcement Learning Based on Self-Supervised Task Representation Learning
Apr 29, 2023



Meta-reinforcement learning enables artificial agents to learn from related training tasks and adapt to new tasks efficiently with minimal interaction data. However, most existing research is still limited to narrow task distributions that are parametric and stationary, and does not consider out-of-distribution tasks during the evaluation, thus, restricting its application. In this paper, we propose MoSS, a context-based Meta-reinforcement learning algorithm based on Self-Supervised task representation learning to address this challenge. We extend meta-RL to broad non-parametric task distributions which have never been explored before, and also achieve state-of-the-art results in non-stationary and out-of-distribution tasks. Specifically, MoSS consists of a task inference module and a policy module. We utilize the Gaussian mixture model for task representation to imitate the parametric and non-parametric task variations. Additionally, our online adaptation strategy enables the agent to react at the first sight of a task change, thus being applicable in non-stationary tasks. MoSS also exhibits strong generalization robustness in out-of-distributions tasks which benefits from the reliable and robust task representation. The policy is built on top of an off-policy RL algorithm and the entire network is trained completely off-policy to ensure high sample efficiency. On MuJoCo and Meta-World benchmarks, MoSS outperforms prior works in terms of asymptotic performance, sample efficiency (3-50x faster), adaptation efficiency, and generalization robustness on broad and diverse task distributions.
NLNDE at SemEval-2023 Task 12: Adaptive Pretraining and Source Language Selection for Low-Resource Multilingual Sentiment Analysis
Apr 28, 2023
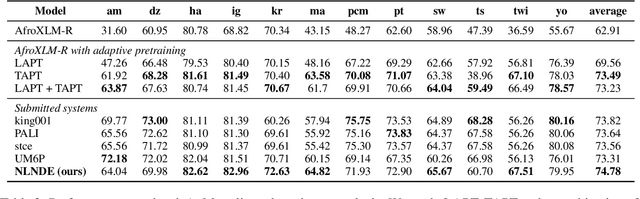
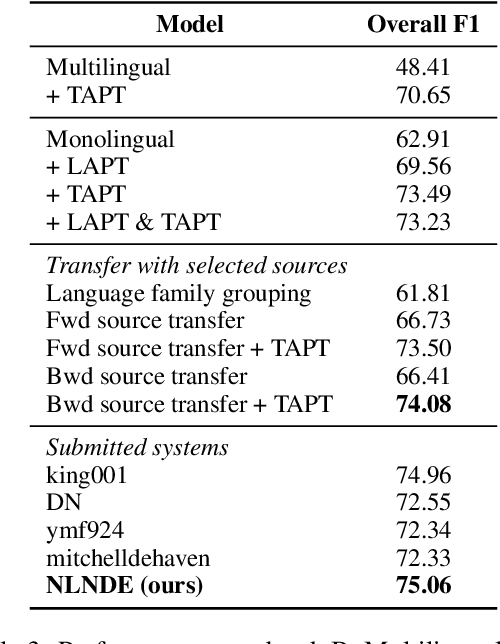
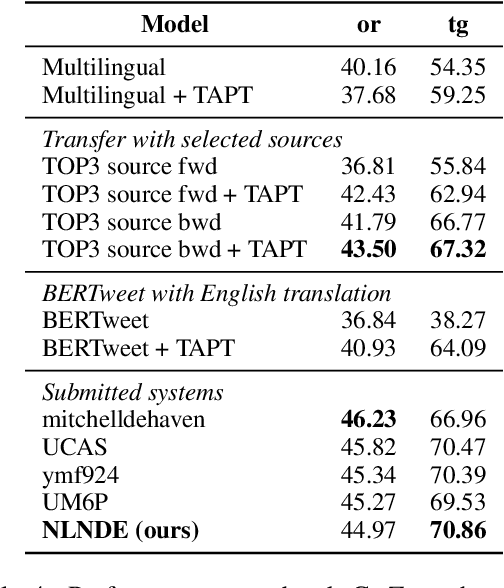
This paper describes our system developed for the SemEval-2023 Task 12 "Sentiment Analysis for Low-resource African Languages using Twitter Dataset". Sentiment analysis is one of the most widely studied applications in natural language processing. However, most prior work still focuses on a small number of high-resource languages. Building reliable sentiment analysis systems for low-resource languages remains challenging, due to the limited training data in this task. In this work, we propose to leverage language-adaptive and task-adaptive pretraining on African texts and study transfer learning with source language selection on top of an African language-centric pretrained language model. Our key findings are: (1) Adapting the pretrained model to the target language and task using a small yet relevant corpus improves performance remarkably by more than 10 F1 score points. (2) Selecting source languages with positive transfer gains during training can avoid harmful interference from dissimilar languages, leading to better results in multilingual and cross-lingual settings. In the shared task, our system wins 8 out of 15 tracks and, in particular, performs best in the multilingual evaluation.
Formation Flight in Dense Environments
Oct 08, 2022
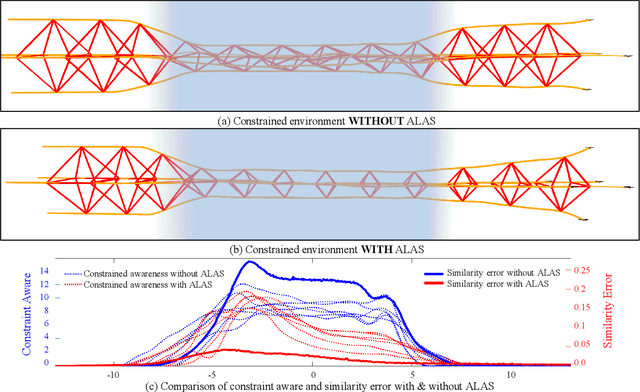
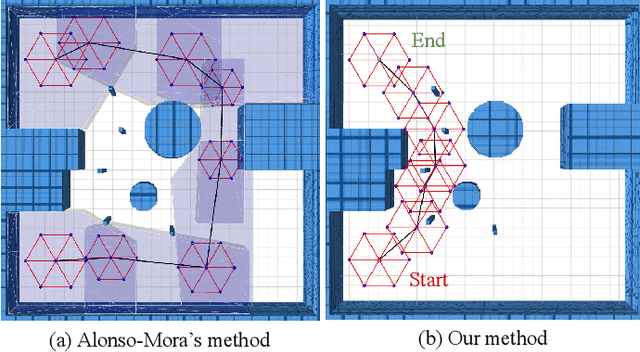
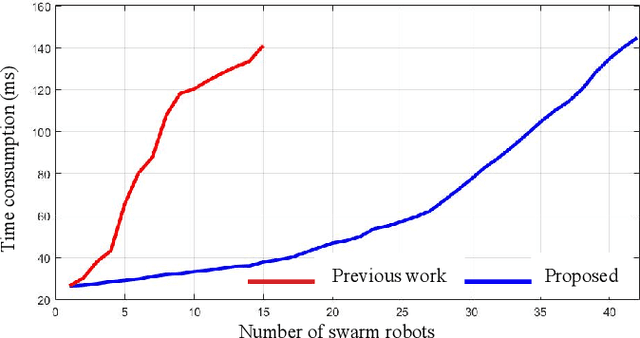
Formation flight has a vast potential for aerial robot swarms in various applications. However, existing methods lack the capability to achieve fully autonomous large-scale formation flight in dense environments. To bridge the gap, we present a complete formation flight system that effectively integrates real-world constraints into aerial formation navigation. This paper proposes a differentiable graph-based metric to quantify the overall similarity error between formations. This metric is invariant to rotation, translation, and scaling, providing more freedom for formation coordination. We design a distributed trajectory optimization framework that considers formation similarity, obstacle avoidance, and dynamic feasibility. The optimization is decoupled to make large-scale formation flights computationally feasible. To improve the elasticity of formation navigation in highly constrained scenes, we present a swarm reorganization method which adaptively adjusts the formation parameters and task assignments by generating local navigation goals. A novel swarm agreement strategy called global-remap-local-replan and a formation-level path planner is proposed in this work to coordinate the swarm global planning and local trajectory optimizations efficiently. To validate the proposed method, we design comprehensive benchmarks and simulations with other cutting-edge works in terms of adaptability, predictability, elasticity, resilience, and efficiency. Finally, integrated with palm-sized swarm platforms with onboard computers and sensors, the proposed method demonstrates its efficiency and robustness by achieving the largest scale formation flight in dense outdoor environments.
Meeting-Merging-Mission: A Multi-robot Coordinate Framework for Large-Scale Communication-Limited Exploration
Sep 16, 2021



This letter presents a complete framework Meeting-Merging-Mission for multi-robot exploration under communication restriction. Considering communication is limited in both bandwidth and range in the real world, we propose a lightweight environment presentation method and an efficient cooperative exploration strategy. For lower bandwidth, each robot utilizes specific polytopes to maintains free space and super frontier information (SFI) as the source for exploration decision-making. To reduce repeated exploration, we develop a mission-based protocol that drives robots to share collected information in stable rendezvous. We also design a complete path planning scheme for both centralized and decentralized cases. To validate that our framework is practical and generic, we present an extensive benchmark and deploy our system into multi-UGV and multi-UAV platforms.