 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLukas Lange
AnnoCTR: A Dataset for Detecting and Linking Entities, Tactics, and Techniques in Cyber Threat Reports
Apr 11, 2024
Monitoring the threat landscape to be aware of actual or potential attacks is of utmost importance to cybersecurity professionals. Information about cyber threats is typically distributed using natural language reports. Natural language processing can help with managing this large amount of unstructured information, yet to date, the topic has received little attention. With this paper, we present AnnoCTR, a new CC-BY-SA-licensed dataset of cyber threat reports. The reports have been annotated by a domain expert with named entities, temporal expressions, and cybersecurity-specific concepts including implicitly mentioned techniques and tactics. Entities and concepts are linked to Wikipedia and the MITRE ATT&CK knowledge base, the most widely-used taxonomy for classifying types of attacks. Prior datasets linking to MITRE ATT&CK either provide a single label per document or annotate sentences out-of-context; our dataset annotates entire documents in a much finer-grained way. In an experimental study, we model the annotations of our dataset using state-of-the-art neural models. In our few-shot scenario, we find that for identifying the MITRE ATT&CK concepts that are mentioned explicitly or implicitly in a text, concept descriptions from MITRE ATT&CK are an effective source for training data augmentation.
Discourse-Aware In-Context Learning for Temporal Expression Normalization
Apr 11, 2024Temporal expression (TE) normalization is a well-studied problem. However, the predominately used rule-based systems are highly restricted to specific settings, and upcoming machine learning approaches suffer from a lack of labeled data. In this work, we explore the feasibility of proprietary and open-source large language models (LLMs) for TE normalization using in-context learning to inject task, document, and example information into the model. We explore various sample selection strategies to retrieve the most relevant set of examples. By using a window-based prompt design approach, we can perform TE normalization across sentences, while leveraging the LLM knowledge without training the model. Our experiments show competitive results to models designed for this task. In particular, our method achieves large performance improvements for non-standard settings by dynamically including relevant examples during inference.
Rehearsal-Free Modular and Compositional Continual Learning for Language Models
Mar 31, 2024Continual learning aims at incrementally acquiring new knowledge while not forgetting existing knowledge. To overcome catastrophic forgetting, methods are either rehearsal-based, i.e., store data examples from previous tasks for data replay, or isolate parameters dedicated to each task. However, rehearsal-based methods raise privacy and memory issues, and parameter-isolation continual learning does not consider interaction between tasks, thus hindering knowledge transfer. In this work, we propose MoCL, a rehearsal-free Modular and Compositional Continual Learning framework which continually adds new modules to language models and composes them with existing modules. Experiments on various benchmarks show that MoCL outperforms state of the art and effectively facilitates knowledge transfer.
BoschAI @ Causal News Corpus 2023: Robust Cause-Effect Span Extraction using Multi-Layer Sequence Tagging and Data Augmentation
Dec 11, 2023



Understanding causality is a core aspect of intelligence. The Event Causality Identification with Causal News Corpus Shared Task addresses two aspects of this challenge: Subtask 1 aims at detecting causal relationships in texts, and Subtask 2 requires identifying signal words and the spans that refer to the cause or effect, respectively. Our system, which is based on pre-trained transformers, stacked sequence tagging, and synthetic data augmentation, ranks third in Subtask 1 and wins Subtask 2 with an F1 score of 72.8, corresponding to a margin of 13 pp. to the second-best system.
DelucionQA: Detecting Hallucinations in Domain-specific Question Answering
Dec 08, 2023Hallucination is a well-known phenomenon in text generated by large language models (LLMs). The existence of hallucinatory responses is found in almost all application scenarios e.g., summarization, question-answering (QA) etc. For applications requiring high reliability (e.g., customer-facing assistants), the potential existence of hallucination in LLM-generated text is a critical problem. The amount of hallucination can be reduced by leveraging information retrieval to provide relevant background information to the LLM. However, LLMs can still generate hallucinatory content for various reasons (e.g., prioritizing its parametric knowledge over the context, failure to capture the relevant information from the context, etc.). Detecting hallucinations through automated methods is thus paramount. To facilitate research in this direction, we introduce a sophisticated dataset, DelucionQA, that captures hallucinations made by retrieval-augmented LLMs for a domain-specific QA task. Furthermore, we propose a set of hallucination detection methods to serve as baselines for future works from the research community. Analysis and case study are also provided to share valuable insights on hallucination phenomena in the target scenario.
GradSim: Gradient-Based Language Grouping for Effective Multilingual Training
Oct 23, 2023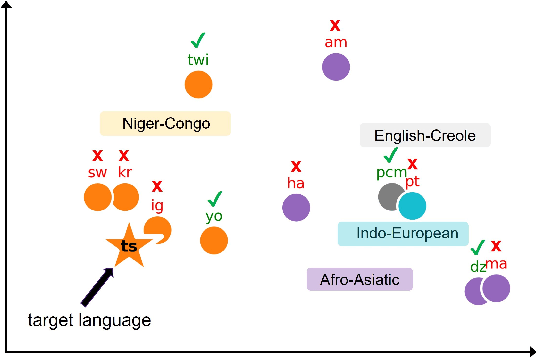
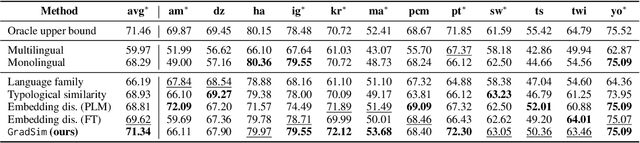
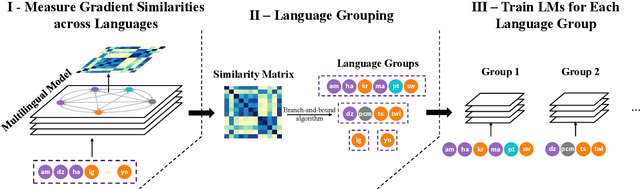

Most languages of the world pose low-resource challenges to natural language processing models. With multilingual training, knowledge can be shared among languages. However, not all languages positively influence each other and it is an open research question how to select the most suitable set of languages for multilingual training and avoid negative interference among languages whose characteristics or data distributions are not compatible. In this paper, we propose GradSim, a language grouping method based on gradient similarity. Our experiments on three diverse multilingual benchmark datasets show that it leads to the largest performance gains compared to other similarity measures and it is better correlated with cross-lingual model performance. As a result, we set the new state of the art on AfriSenti, a benchmark dataset for sentiment analysis on low-resource African languages. In our extensive analysis, we further reveal that besides linguistic features, the topics of the datasets play an important role for language grouping and that lower layers of transformer models encode language-specific features while higher layers capture task-specific information.
TADA: Efficient Task-Agnostic Domain Adaptation for Transformers
May 22, 2023



Intermediate training of pre-trained transformer-based language models on domain-specific data leads to substantial gains for downstream tasks. To increase efficiency and prevent catastrophic forgetting alleviated from full domain-adaptive pre-training, approaches such as adapters have been developed. However, these require additional parameters for each layer, and are criticized for their limited expressiveness. In this work, we introduce TADA, a novel task-agnostic domain adaptation method which is modular, parameter-efficient, and thus, data-efficient. Within TADA, we retrain the embeddings to learn domain-aware input representations and tokenizers for the transformer encoder, while freezing all other parameters of the model. Then, task-specific fine-tuning is performed. We further conduct experiments with meta-embeddings and newly introduced meta-tokenizers, resulting in one model per task in multi-domain use cases. Our broad evaluation in 4 downstream tasks for 14 domains across single- and multi-domain setups and high- and low-resource scenarios reveals that TADA is an effective and efficient alternative to full domain-adaptive pre-training and adapters for domain adaptation, while not introducing additional parameters or complex training steps.
NLNDE at SemEval-2023 Task 12: Adaptive Pretraining and Source Language Selection for Low-Resource Multilingual Sentiment Analysis
Apr 28, 2023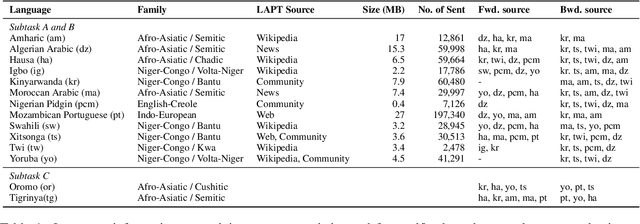
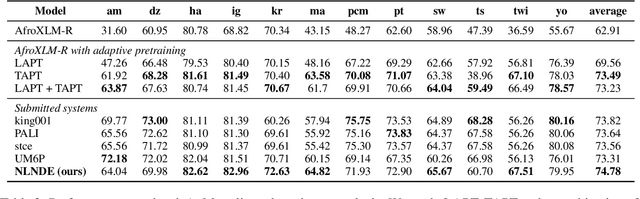
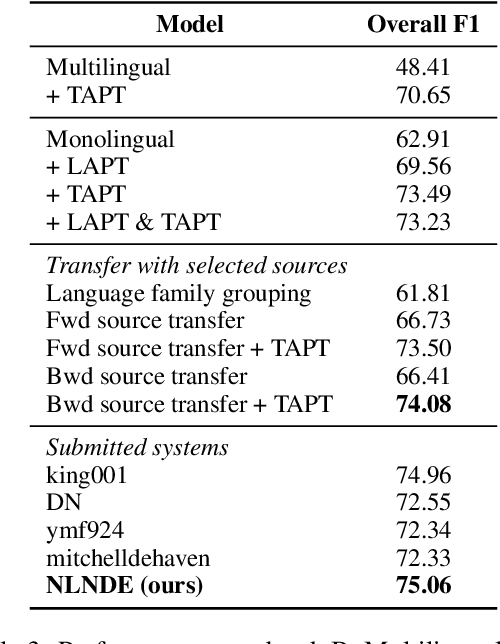
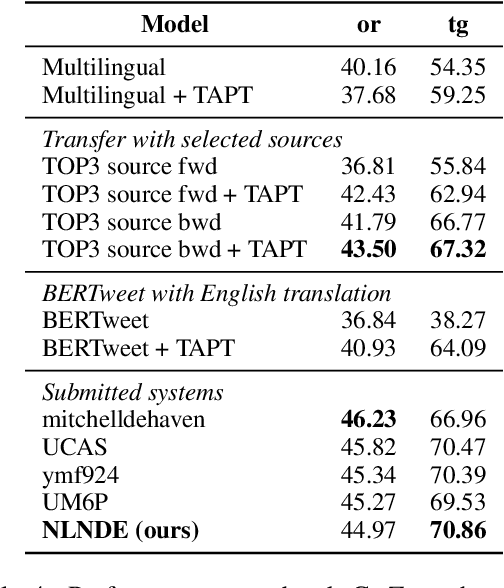
This paper describes our system developed for the SemEval-2023 Task 12 "Sentiment Analysis for Low-resource African Languages using Twitter Dataset". Sentiment analysis is one of the most widely studied applications in natural language processing. However, most prior work still focuses on a small number of high-resource languages. Building reliable sentiment analysis systems for low-resource languages remains challenging, due to the limited training data in this task. In this work, we propose to leverage language-adaptive and task-adaptive pretraining on African texts and study transfer learning with source language selection on top of an African language-centric pretrained language model. Our key findings are: (1) Adapting the pretrained model to the target language and task using a small yet relevant corpus improves performance remarkably by more than 10 F1 score points. (2) Selecting source languages with positive transfer gains during training can avoid harmful interference from dissimilar languages, leading to better results in multilingual and cross-lingual settings. In the shared task, our system wins 8 out of 15 tracks and, in particular, performs best in the multilingual evaluation.
SwitchPrompt: Learning Domain-Specific Gated Soft Prompts for Classification in Low-Resource Domains
Feb 14, 2023
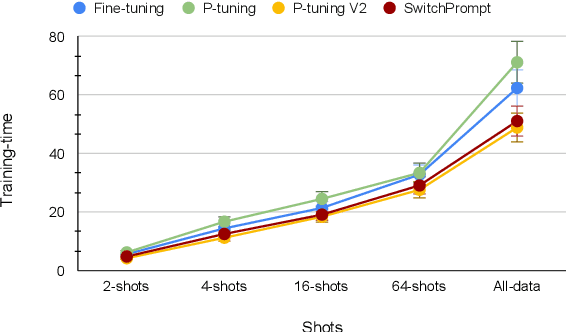

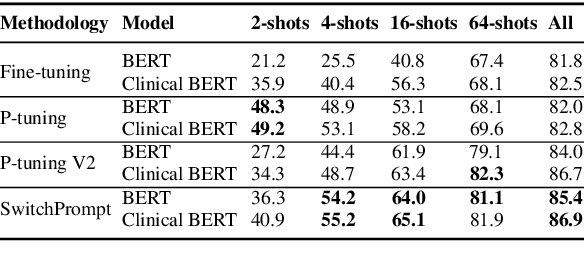
Prompting pre-trained language models leads to promising results across natural language processing tasks but is less effective when applied in low-resource domains, due to the domain gap between the pre-training data and the downstream task. In this work, we bridge this gap with a novel and lightweight prompting methodology called SwitchPrompt for the adaptation of language models trained on datasets from the general domain to diverse low-resource domains. Using domain-specific keywords with a trainable gated prompt, SwitchPrompt offers domain-oriented prompting, that is, effective guidance on the target domains for general-domain language models. Our few-shot experiments on three text classification benchmarks demonstrate the efficacy of the general-domain pre-trained language models when used with SwitchPrompt. They often even outperform their domain-specific counterparts trained with baseline state-of-the-art prompting methods by up to 10.7% performance increase in accuracy. This result indicates that SwitchPrompt effectively reduces the need for domain-specific language model pre-training.
Multilingual Normalization of Temporal Expressions with Masked Language Models
May 20, 2022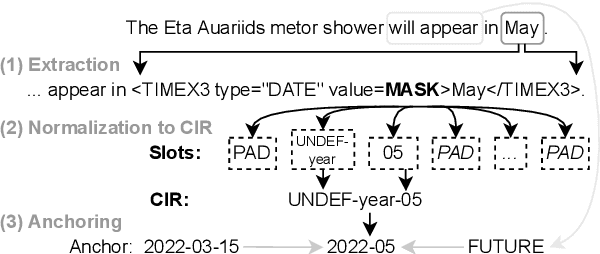
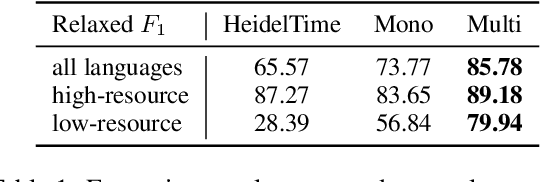
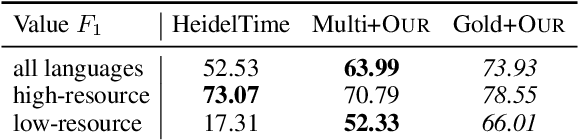
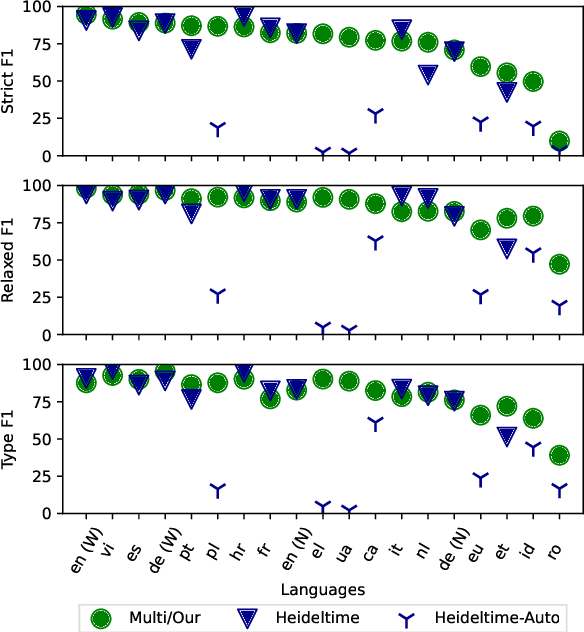
The detection and normalization of temporal expressions is an important task and a preprocessing step for many applications. However, prior work on normalization is rule-based, which severely limits the applicability in real-world multilingual settings, due to the costly creation of new rules. We propose a novel neural method for normalizing temporal expressions based on masked language modeling. Our multilingual method outperforms prior rule-based systems in many languages, and in particular, for low-resource languages with performance improvements of up to 35 F1 on average compared to the state of the art.