 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnnemarie Friedrich
FREB-TQA: A Fine-Grained Robustness Evaluation Benchmark for Table Question Answering
Apr 29, 2024
Table Question Answering (TQA) aims at composing an answer to a question based on tabular data. While prior research has shown that TQA models lack robustness, understanding the underlying cause and nature of this issue remains predominantly unclear, posing a significant obstacle to the development of robust TQA systems. In this paper, we formalize three major desiderata for a fine-grained evaluation of robustness of TQA systems. They should (i) answer questions regardless of alterations in table structure, (ii) base their responses on the content of relevant cells rather than on biases, and (iii) demonstrate robust numerical reasoning capabilities. To investigate these aspects, we create and publish a novel TQA evaluation benchmark in English. Our extensive experimental analysis reveals that none of the examined state-of-the-art TQA systems consistently excels in these three aspects. Our benchmark is a crucial instrument for monitoring the behavior of TQA systems and paves the way for the development of robust TQA systems. We release our benchmark publicly.
AnnoCTR: A Dataset for Detecting and Linking Entities, Tactics, and Techniques in Cyber Threat Reports
Apr 11, 2024Monitoring the threat landscape to be aware of actual or potential attacks is of utmost importance to cybersecurity professionals. Information about cyber threats is typically distributed using natural language reports. Natural language processing can help with managing this large amount of unstructured information, yet to date, the topic has received little attention. With this paper, we present AnnoCTR, a new CC-BY-SA-licensed dataset of cyber threat reports. The reports have been annotated by a domain expert with named entities, temporal expressions, and cybersecurity-specific concepts including implicitly mentioned techniques and tactics. Entities and concepts are linked to Wikipedia and the MITRE ATT&CK knowledge base, the most widely-used taxonomy for classifying types of attacks. Prior datasets linking to MITRE ATT&CK either provide a single label per document or annotate sentences out-of-context; our dataset annotates entire documents in a much finer-grained way. In an experimental study, we model the annotations of our dataset using state-of-the-art neural models. In our few-shot scenario, we find that for identifying the MITRE ATT&CK concepts that are mentioned explicitly or implicitly in a text, concept descriptions from MITRE ATT&CK are an effective source for training data augmentation.
BoschAI @ Causal News Corpus 2023: Robust Cause-Effect Span Extraction using Multi-Layer Sequence Tagging and Data Augmentation
Dec 11, 2023



Understanding causality is a core aspect of intelligence. The Event Causality Identification with Causal News Corpus Shared Task addresses two aspects of this challenge: Subtask 1 aims at detecting causal relationships in texts, and Subtask 2 requires identifying signal words and the spans that refer to the cause or effect, respectively. Our system, which is based on pre-trained transformers, stacked sequence tagging, and synthetic data augmentation, ranks third in Subtask 1 and wins Subtask 2 with an F1 score of 72.8, corresponding to a margin of 13 pp. to the second-best system.
BoschAI @ PLABA 2023: Leveraging Edit Operations in End-to-End Neural Sentence Simplification
Nov 03, 2023



Automatic simplification can help laypeople to comprehend complex scientific text. Language models are frequently applied to this task by translating from complex to simple language. In this paper, we describe our system based on Llama 2, which ranked first in the PLABA shared task addressing the simplification of biomedical text. We find that the large portion of shared tokens between input and output leads to weak training signals and conservatively editing models. To mitigate these issues, we propose sentence-level and token-level loss weights. They give higher weight to modified tokens, indicated by edit distance and edit operations, respectively. We conduct an empirical evaluation on the PLABA dataset and find that both approaches lead to simplifications closer to those created by human annotators (+1.8% / +3.5% SARI), simpler language (-1 / -1.1 FKGL) and more edits (1.6x / 1.8x edit distance) compared to the same model fine-tuned with standard cross entropy. We furthermore show that the hyperparameter $\lambda$ in token-level loss weights can be used to control the edit distance and the simplicity level (FKGL).
MuLMS: A Multi-Layer Annotated Text Corpus for Information Extraction in the Materials Science Domain
Oct 24, 2023



Keeping track of all relevant recent publications and experimental results for a research area is a challenging task. Prior work has demonstrated the efficacy of information extraction models in various scientific areas. Recently, several datasets have been released for the yet understudied materials science domain. However, these datasets focus on sub-problems such as parsing synthesis procedures or on sub-domains, e.g., solid oxide fuel cells. In this resource paper, we present MuLMS, a new dataset of 50 open-access articles, spanning seven sub-domains of materials science. The corpus has been annotated by domain experts with several layers ranging from named entities over relations to frame structures. We present competitive neural models for all tasks and demonstrate that multi-task training with existing related resources leads to benefits.
MuLMS-AZ: An Argumentative Zoning Dataset for the Materials Science Domain
Jul 05, 2023



Scientific publications follow conventionalized rhetorical structures. Classifying the Argumentative Zone (AZ), e.g., identifying whether a sentence states a Motivation, a Result or Background information, has been proposed to improve processing of scholarly documents. In this work, we adapt and extend this idea to the domain of materials science research. We present and release a new dataset of 50 manually annotated research articles. The dataset spans seven sub-topics and is annotated with a materials-science focused multi-label annotation scheme for AZ. We detail corpus statistics and demonstrate high inter-annotator agreement. Our computational experiments show that using domain-specific pre-trained transformer-based text encoders is key to high classification performance. We also find that AZ categories from existing datasets in other domains are transferable to varying degrees.
MIST: a Large-Scale Annotated Resource and Neural Models for Functions of Modal Verbs in English Scientific Text
Dec 14, 2022



Modal verbs (e.g., "can", "should", or "must") occur highly frequently in scientific articles. Decoding their function is not straightforward: they are often used for hedging, but they may also denote abilities and restrictions. Understanding their meaning is important for various NLP tasks such as writing assistance or accurate information extraction from scientific text. To foster research on the usage of modals in this genre, we introduce the MIST (Modals In Scientific Text) dataset, which contains 3737 modal instances in five scientific domains annotated for their semantic, pragmatic, or rhetorical function. We systematically evaluate a set of competitive neural architectures on MIST. Transfer experiments reveal that leveraging non-scientific data is of limited benefit for modeling the distinctions in MIST. Our corpus analysis provides evidence that scientific communities differ in their usage of modal verbs, yet, classifiers trained on scientific data generalize to some extent to unseen scientific domains.
A Survey of Methods for Addressing Class Imbalance in Deep-Learning Based Natural Language Processing
Oct 10, 2022



Many natural language processing (NLP) tasks are naturally imbalanced, as some target categories occur much more frequently than others in the real world. In such scenarios, current NLP models still tend to perform poorly on less frequent classes. Addressing class imbalance in NLP is an active research topic, yet, finding a good approach for a particular task and imbalance scenario is difficult. With this survey, the first overview on class imbalance in deep-learning based NLP, we provide guidance for NLP researchers and practitioners dealing with imbalanced data. We first discuss various types of controlled and real-world class imbalance. Our survey then covers approaches that have been explicitly proposed for class-imbalanced NLP tasks or, originating in the computer vision community, have been evaluated on them. We organize the methods by whether they are based on sampling, data augmentation, choice of loss function, staged learning, or model design. Finally, we discuss open problems such as dealing with multi-label scenarios, and propose systematic benchmarking and reporting in order to move forward on this problem as a community.
A Kind Introduction to Lexical and Grammatical Aspect, with a Survey of Computational Approaches
Aug 18, 2022
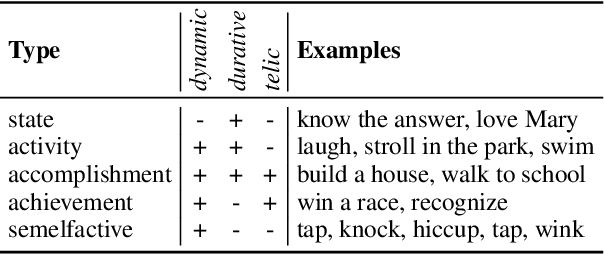

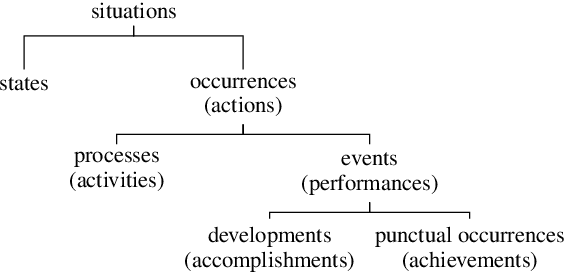
Aspectual meaning refers to how the internal temporal structure of situations is presented. This includes whether a situation is described as a state or as an event, whether the situation is finished or ongoing, and whether it is viewed as a whole or with a focus on a particular phase. This survey gives an overview of computational approaches to modeling lexical and grammatical aspect along with intuitive explanations of the necessary linguistic concepts and terminology. In particular, we describe the concepts of stativity, telicity, habituality, perfective and imperfective, as well as influential inventories of eventuality and situation types. We argue that because aspect is a crucial component of semantics, especially when it comes to reporting the temporal structure of situations in a precise way, future NLP approaches need to be able to handle and evaluate it systematically in order to achieve human-level language understanding.
Multi-label classification for biomedical literature: an overview of the BioCreative VII LitCovid Track for COVID-19 literature topic annotations
Apr 20, 2022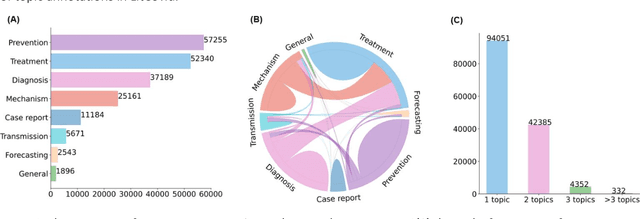
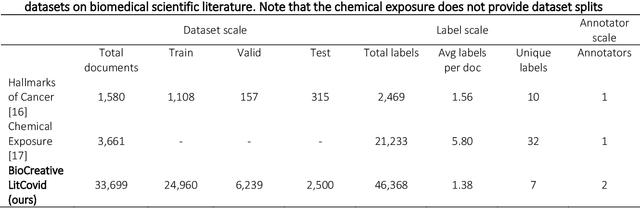
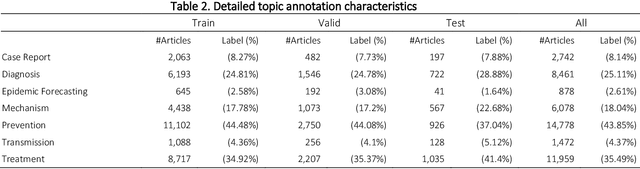
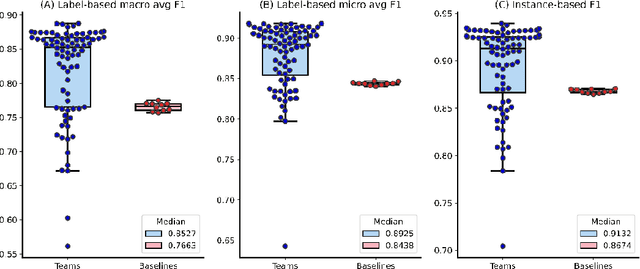
The COVID-19 pandemic has been severely impacting global society since December 2019. Massive research has been undertaken to understand the characteristics of the virus and design vaccines and drugs. The related findings have been reported in biomedical literature at a rate of about 10,000 articles on COVID-19 per month. Such rapid growth significantly challenges manual curation and interpretation. For instance, LitCovid is a literature database of COVID-19-related articles in PubMed, which has accumulated more than 200,000 articles with millions of accesses each month by users worldwide. One primary curation task is to assign up to eight topics (e.g., Diagnosis and Treatment) to the articles in LitCovid. Despite the continuing advances in biomedical text mining methods, few have been dedicated to topic annotations in COVID-19 literature. To close the gap, we organized the BioCreative LitCovid track to call for a community effort to tackle automated topic annotation for COVID-19 literature. The BioCreative LitCovid dataset, consisting of over 30,000 articles with manually reviewed topics, was created for training and testing. It is one of the largest multilabel classification datasets in biomedical scientific literature. 19 teams worldwide participated and made 80 submissions in total. Most teams used hybrid systems based on transformers. The highest performing submissions achieved 0.8875, 0.9181, and 0.9394 for macro F1-score, micro F1-score, and instance-based F1-score, respectively. The level of participation and results demonstrate a successful track and help close the gap between dataset curation and method development. The dataset is publicly available via https://ftp.ncbi.nlm.nih.gov/pub/lu/LitCovid/biocreative/ for benchmarking and further development.