 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShiyi Cao
Optimizing LLM Queries in Relational Workloads
Mar 09, 2024
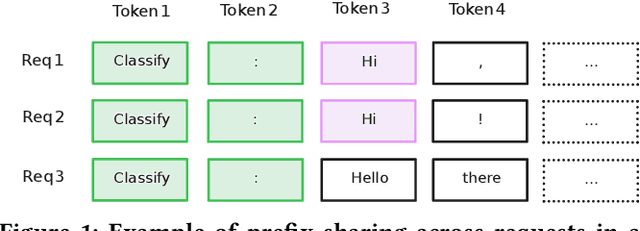
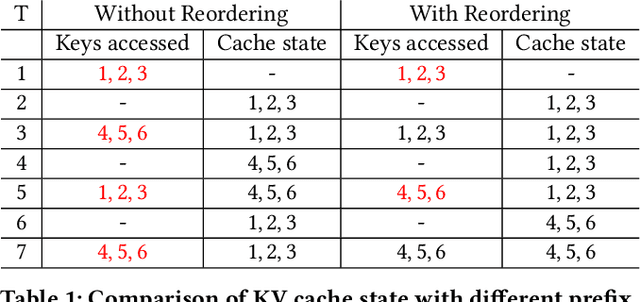
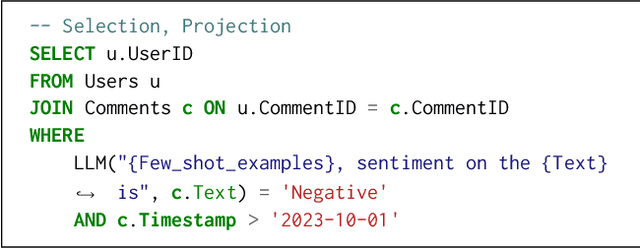

Analytical database providers (e.g., Redshift, Databricks, BigQuery) have rapidly added support for invoking Large Language Models (LLMs) through native user-defined functions (UDFs) to help users perform natural language tasks, such as classification, entity extraction, and translation, inside analytical workloads. For instance, an analyst might want to extract customer sentiments on millions of product reviews. However, LLM inference is highly expensive in both computational and economic terms: for example, an NVIDIA L4 GPU running Llama2-7B can only process 6 KB of text per second. In this paper, we explore how to optimize LLM inference for analytical workloads that invoke LLMs within relational queries. We show that relational queries present novel opportunities for accelerating LLM inference, including reordering rows to maximize key-value (KV) cache reuse within the LLM inference engine, reordering columns within a row to further increase cache reuse, and deduplicating redundant inference requests. We implement these optimizations in Apache Spark, with vLLM as the model serving backend and achieve up to 4.4x improvement in end-to-end latency on a benchmark of diverse LLM-based queries on real datasets. To the best of our knowledge, this is the first work to explicitly address the problem of optimizing LLM invocations within SQL queries.
Fairness in Serving Large Language Models
Dec 31, 2023High-demand LLM inference services (e.g., ChatGPT and BARD) support a wide range of requests from short chat conversations to long document reading. To ensure that all client requests are processed fairly, most major LLM inference services have request rate limits, to ensure that no client can dominate the request queue. However, this rudimentary notion of fairness also results in under-utilization of the resources and poor client experience when there is spare capacity. While there is a rich literature on fair scheduling, serving LLMs presents new challenges due to their unpredictable request lengths and their unique batching characteristics on parallel accelerators. This paper introduces the definition of LLM serving fairness based on a cost function that accounts for the number of input and output tokens processed. To achieve fairness in serving, we propose a novel scheduling algorithm, the Virtual Token Counter (VTC), a fair scheduler based on the continuous batching mechanism. We prove a 2x tight upper bound on the service difference between two backlogged clients, adhering to the requirement of work-conserving. Through extensive experiments, we demonstrate the superior performance of VTC in ensuring fairness, especially in contrast to other baseline methods, which exhibit shortcomings under various conditions.
Efficiently Programming Large Language Models using SGLang
Dec 12, 2023Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
S-LoRA: Serving Thousands of Concurrent LoRA Adapters
Nov 07, 2023The "pretrain-then-finetune" paradigm is commonly adopted in the deployment of large language models. Low-Rank Adaptation (LoRA), a parameter-efficient fine-tuning method, is often employed to adapt a base model to a multitude of tasks, resulting in a substantial collection of LoRA adapters derived from one base model. We observe that this paradigm presents significant opportunities for batched inference during serving. To capitalize on these opportunities, we present S-LoRA, a system designed for the scalable serving of many LoRA adapters. S-LoRA stores all adapters in the main memory and fetches the adapters used by the currently running queries to the GPU memory. To efficiently use the GPU memory and reduce fragmentation, S-LoRA proposes Unified Paging. Unified Paging uses a unified memory pool to manage dynamic adapter weights with different ranks and KV cache tensors with varying sequence lengths. Additionally, S-LoRA employs a novel tensor parallelism strategy and highly optimized custom CUDA kernels for heterogeneous batching of LoRA computation. Collectively, these features enable S-LoRA to serve thousands of LoRA adapters on a single GPU or across multiple GPUs with a small overhead. Compared to state-of-the-art libraries such as HuggingFace PEFT and vLLM (with naive support of LoRA serving), S-LoRA can improve the throughput by up to 4 times and increase the number of served adapters by several orders of magnitude. As a result, S-LoRA enables scalable serving of many task-specific fine-tuned models and offers the potential for large-scale customized fine-tuning services. The code is available at https://github.com/S-LoRA/S-LoRA