 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZhiqiang Xie
Blockchain-enabled Trustworthy Federated Unlearning
Jan 29, 2024
Federated unlearning is a promising paradigm for protecting the data ownership of distributed clients. It allows central servers to remove historical data effects within the machine learning model as well as address the "right to be forgotten" issue in federated learning. However, existing works require central servers to retain the historical model parameters from distributed clients, such that allows the central server to utilize these parameters for further training even, after the clients exit the training process. To address this issue, this paper proposes a new blockchain-enabled trustworthy federated unlearning framework. We first design a proof of federated unlearning protocol, which utilizes the Chameleon hash function to verify data removal and eliminate the data contributions stored in other clients' models. Then, an adaptive contribution-based retraining mechanism is developed to reduce the computational overhead and significantly improve the training efficiency. Extensive experiments demonstrate that the proposed framework can achieve a better data removal effect than the state-of-the-art frameworks, marking a significant stride towards trustworthy federated unlearning.
Efficiently Programming Large Language Models using SGLang
Dec 12, 2023Large language models (LLMs) are increasingly used for complex tasks requiring multiple chained generation calls, advanced prompting techniques, control flow, and interaction with external environments. However, efficient systems for programming and executing these applications are lacking. To bridge this gap, we introduce SGLang, a Structured Generation Language for LLMs. SGLang is designed for the efficient programming of LLMs and incorporates primitives for common LLM programming patterns. We have implemented SGLang as a domain-specific language embedded in Python, and we developed an interpreter, a compiler, and a high-performance runtime for SGLang. These components work together to enable optimizations such as parallelism, batching, caching, sharing, and other compilation techniques. Additionally, we propose RadixAttention, a novel technique that maintains a Least Recently Used (LRU) cache of the Key-Value (KV) cache for all requests in a radix tree, enabling automatic KV cache reuse across multiple generation calls at runtime. SGLang simplifies the writing of LLM programs and boosts execution efficiency. Our experiments demonstrate that SGLang can speed up common LLM tasks by up to 5x, while reducing code complexity and enhancing control.
High-throughput Generative Inference of Large Language Models with a Single GPU
Mar 13, 2023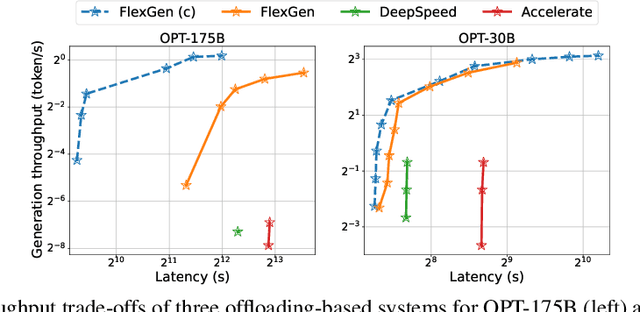

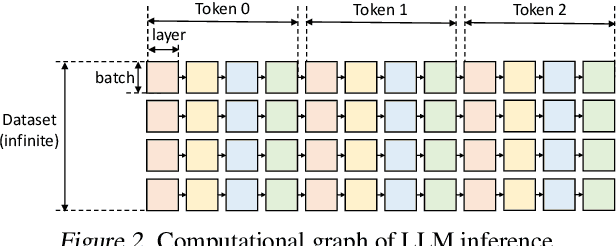
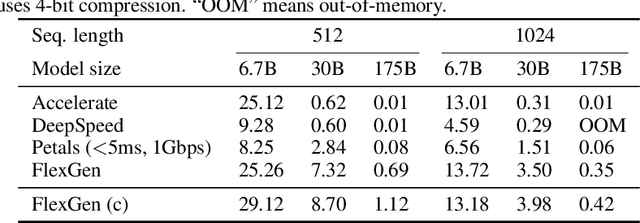
The high computational and memory requirements of large language model (LLM) inference traditionally make it feasible only with multiple high-end accelerators. Motivated by the emerging demand for latency-insensitive tasks with batched processing, this paper initiates the study of high-throughput LLM inference using limited resources, such as a single commodity GPU. We present FlexGen, a high-throughput generation engine for running LLMs with limited GPU memory. FlexGen can be flexibly configured under various hardware resource constraints by aggregating memory and computation from the GPU, CPU, and disk. Through a linear programming optimizer, it searches for efficient patterns to store and access tensors. FlexGen further compresses these weights and the attention cache to 4 bits with negligible accuracy loss. These techniques enable FlexGen to have a larger space of batch size choices and thus significantly increase maximum throughput. As a result, when running OPT-175B on a single 16GB GPU, FlexGen achieves significantly higher throughput compared to state-of-the-art offloading systems, reaching a generation throughput of 1 token/s for the first time with an effective batch size of 144. On the HELM benchmark, FlexGen can benchmark a 30B model with a 16GB GPU on 7 representative sub-scenarios in 21 hours. The code is available at https://github.com/FMInference/FlexGen
Dual-side Sparse Tensor Core
May 20, 2021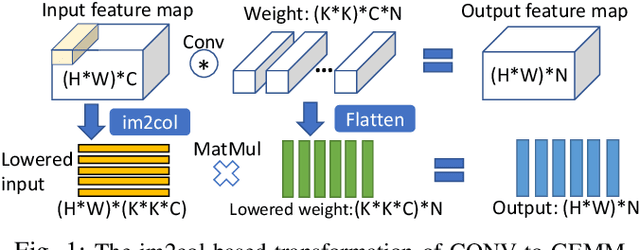

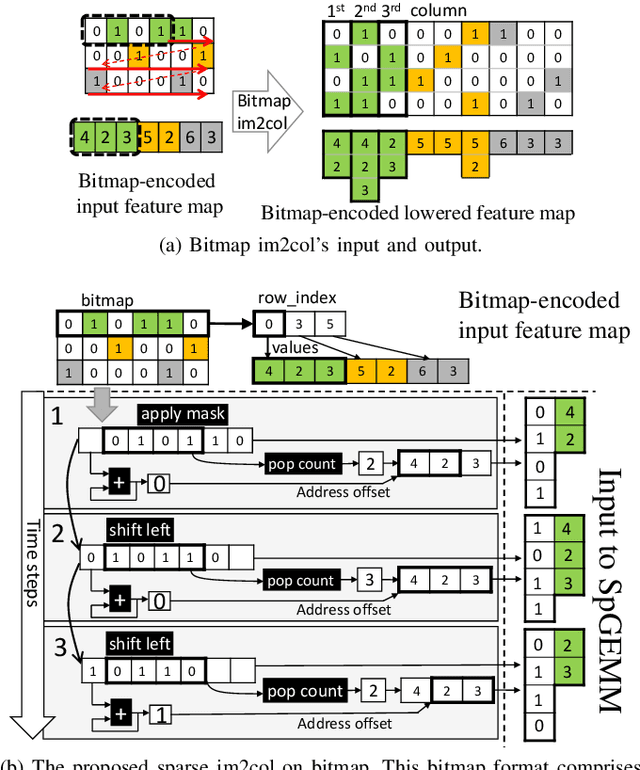
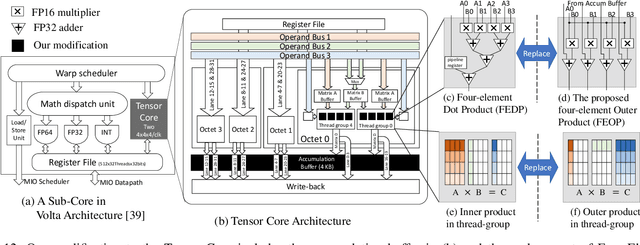
Leveraging sparsity in deep neural network (DNN) models is promising for accelerating model inference. Yet existing GPUs can only leverage the sparsity from weights but not activations, which are dynamic, unpredictable, and hence challenging to exploit. In this work, we propose a novel architecture to efficiently harness the dual-side sparsity (i.e., weight and activation sparsity). We take a systematic approach to understand the (dis)advantages of previous sparsity-related architectures and propose a novel, unexplored paradigm that combines outer-product computation primitive and bitmap-based encoding format. We demonstrate the feasibility of our design with minimal changes to the existing production-scale inner-product-based Tensor Core. We propose a set of novel ISA extensions and co-design the matrix-matrix multiplication and convolution algorithms, which are the two dominant computation patterns in today's DNN models, to exploit our new dual-side sparse Tensor Core. Our evaluation shows that our design can fully unleash the dual-side DNN sparsity and improve the performance by up to one order of magnitude with \hl{small} hardware overhead.
An Iterative Polishing Framework based on Quality Aware Masked Language Model for Chinese Poetry Generation
Nov 29, 2019



Owing to its unique literal and aesthetical characteristics, automatic generation of Chinese poetry is still challenging in Artificial Intelligence, which can hardly be straightforwardly realized by end-to-end methods. In this paper, we propose a novel iterative polishing framework for highly qualified Chinese poetry generation. In the first stage, an encoder-decoder structure is utilized to generate a poem draft. Afterwards, our proposed Quality-Aware Masked Language Model (QAMLM) is employed to polish the draft towards higher quality in terms of linguistics and literalness. Based on a multi-task learning scheme, QA-MLM is able to determine whether polishing is needed based on the poem draft. Furthermore, QAMLM is able to localize improper characters of the poem draft and substitute with newly predicted ones accordingly. Benefited from the masked language model structure, QAMLM incorporates global context information into the polishing process, which can obtain more appropriate polishing results than the unidirectional sequential decoding. Moreover, the iterative polishing process will be terminated automatically when QA-MLM regards the processed poem as a qualified one. Both human and automatic evaluation have been conducted, and the results demonstrate that our approach is effective to improve the performance of encoder-decoder structure.