 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShuiwang Li
Tracking Transforming Objects: A Benchmark
Apr 28, 2024
Tracking transforming objects holds significant importance in various fields due to the dynamic nature of many real-world scenarios. By enabling systems accurately represent transforming objects over time, tracking transforming objects facilitates advancements in areas such as autonomous systems, human-computer interaction, and security applications. Moreover, understanding the behavior of transforming objects provides valuable insights into complex interactions or processes, contributing to the development of intelligent systems capable of robust and adaptive perception in dynamic environments. However, current research in the field mainly focuses on tracking generic objects. In this study, we bridge this gap by collecting a novel dedicated Dataset for Tracking Transforming Objects, called DTTO, which contains 100 sequences, amounting to approximately 9.3K frames. We provide carefully hand-annotated bounding boxes for each frame within these sequences, making DTTO the pioneering benchmark dedicated to tracking transforming objects. We thoroughly evaluate 20 state-of-the-art trackers on the benchmark, aiming to comprehend the performance of existing methods and provide a comparison for future research on DTTO. With the release of DTTO, our goal is to facilitate further research and applications related to tracking transforming objects.
Towards Discriminative Representations with Contrastive Instances for Real-Time UAV Tracking
Aug 22, 2023Maintaining high efficiency and high precision are two fundamental challenges in UAV tracking due to the constraints of computing resources, battery capacity, and UAV maximum load. Discriminative correlation filters (DCF)-based trackers can yield high efficiency on a single CPU but with inferior precision. Lightweight Deep learning (DL)-based trackers can achieve a good balance between efficiency and precision but performance gains are limited by the compression rate. High compression rate often leads to poor discriminative representations. To this end, this paper aims to enhance the discriminative power of feature representations from a new feature-learning perspective. Specifically, we attempt to learn more disciminative representations with contrastive instances for UAV tracking in a simple yet effective manner, which not only requires no manual annotations but also allows for developing and deploying a lightweight model. We are the first to explore contrastive learning for UAV tracking. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and VisDrone2018, show that the proposed DRCI tracker significantly outperforms state-of-the-art UAV tracking methods.
Learning Disentangled Representation with Mutual Information Maximization for Real-Time UAV Tracking
Aug 20, 2023Efficiency has been a critical problem in UAV tracking due to limitations in computation resources, battery capacity, and unmanned aerial vehicle maximum load. Although discriminative correlation filters (DCF)-based trackers prevail in this field for their favorable efficiency, some recently proposed lightweight deep learning (DL)-based trackers using model compression demonstrated quite remarkable CPU efficiency as well as precision. Unfortunately, the model compression methods utilized by these works, though simple, are still unable to achieve satisfying tracking precision with higher compression rates. This paper aims to exploit disentangled representation learning with mutual information maximization (DR-MIM) to further improve DL-based trackers' precision and efficiency for UAV tracking. The proposed disentangled representation separates the feature into an identity-related and an identity-unrelated features. Only the latter is used, which enhances the effectiveness of the feature representation for subsequent classification and regression tasks. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and VisDrone2018, show that our DR-MIM tracker significantly outperforms state-of-the-art UAV tracking methods.
Tracking Small and Fast Moving Objects: A Benchmark
Sep 09, 2022



With more and more large-scale datasets available for training, visual tracking has made great progress in recent years. However, current research in the field mainly focuses on tracking generic objects. In this paper, we present TSFMO, a benchmark for \textbf{T}racking \textbf{S}mall and \textbf{F}ast \textbf{M}oving \textbf{O}bjects. This benchmark aims to encourage research in developing novel and accurate methods for this challenging task particularly. TSFMO consists of 250 sequences with about 50k frames in total. Each frame in these sequences is carefully and manually annotated with a bounding box. To the best of our knowledge, TSFMO is the first benchmark dedicated to tracking small and fast moving objects, especially connected to sports. To understand how existing methods perform and to provide comparison for future research on TSFMO, we extensively evaluate 20 state-of-the-art trackers on the benchmark. The evaluation results exhibit that more effort are required to improve tracking small and fast moving objects. Moreover, to encourage future research, we proposed a novel tracker S-KeepTrack which surpasses all 20 evaluated approaches. By releasing TSFMO, we expect to facilitate future researches and applications of tracking small and fast moving objects. The TSFMO and evaluation results as well as S-KeepTrack are available at \url{https://github.com/CodeOfGithub/S-KeepTrack}.
Rank-Based Filter Pruning for Real-Time UAV Tracking
Jul 05, 2022



Unmanned aerial vehicle (UAV) tracking has wide potential applications in such as agriculture, navigation, and public security. However, the limitations of computing resources, battery capacity, and maximum load of UAV hinder the deployment of deep learning-based tracking algorithms on UAV. Consequently, discriminative correlation filters (DCF) trackers stand out in the UAV tracking community because of their high efficiency. However, their precision is usually much lower than trackers based on deep learning. Model compression is a promising way to narrow the gap (i.e., effciency, precision) between DCF- and deep learning- based trackers, which has not caught much attention in UAV tracking. In this paper, we propose the P-SiamFC++ tracker, which is the first to use rank-based filter pruning to compress the SiamFC++ model, achieving a remarkable balance between efficiency and precision. Our method is general and may encourage further studies on UAV tracking with model compression. Extensive experiments on four UAV benchmarks, including UAV123@10fps, DTB70, UAVDT and Vistrone2018, show that P-SiamFC++ tracker significantly outperforms state-of-the-art UAV tracking methods.
SSPNet: Scale Selection Pyramid Network for Tiny Person Detection from UAV Images
Jul 04, 2021



With the increasing demand for search and rescue, it is highly demanded to detect objects of interest in large-scale images captured by Unmanned Aerial Vehicles (UAVs), which is quite challenging due to extremely small scales of objects. Most existing methods employed Feature Pyramid Network (FPN) to enrich shallow layers' features by combing deep layers' contextual features. However, under the limitation of the inconsistency in gradient computation across different layers, the shallow layers in FPN are not fully exploited to detect tiny objects. In this paper, we propose a Scale Selection Pyramid network (SSPNet) for tiny person detection, which consists of three components: Context Attention Module (CAM), Scale Enhancement Module (SEM), and Scale Selection Module (SSM). CAM takes account of context information to produce hierarchical attention heatmaps. SEM highlights features of specific scales at different layers, leading the detector to focus on objects of specific scales instead of vast backgrounds. SSM exploits adjacent layers' relationships to fulfill suitable feature sharing between deep layers and shallow layers, thereby avoiding the inconsistency in gradient computation across different layers. Besides, we propose a Weighted Negative Sampling (WNS) strategy to guide the detector to select more representative samples. Experiments on the TinyPerson benchmark show that our method outperforms other state-of-the-art (SOTA) detectors.
Equivalence of Correlation Filter and Convolution Filter in Visual Tracking
May 04, 2021(Discriminative) Correlation Filter has been successfully applied to visual tracking and has advanced the field significantly in recent years. Correlation filter-based trackers consider visual tracking as a problem of matching the feature template of the object and candidate regions in the detection sample, in which correlation filter provides the means to calculate the similarities. In contrast, convolution filter is usually used for blurring, sharpening, embossing, edge detection, etc in image processing. On the surface, correlation filter and convolution filter are usually used for different purposes. In this paper, however, we proves, for the first time, that correlation filter and convolution filter are equivalent in the sense that their minimum mean-square errors (MMSEs) in visual tracking are equal, under the condition that the optimal solutions exist and the ideal filter response is Gaussian and centrosymmetric. This result gives researchers the freedom to choose correlation or convolution in formulating their trackers. It also suggests that the explanation of the ideal response in terms of similarities is not essential.
Learning Residue-Aware Correlation Filters and Refining Scale Estimates with the GrabCut for Real-Time UAV Tracking
Apr 07, 2021

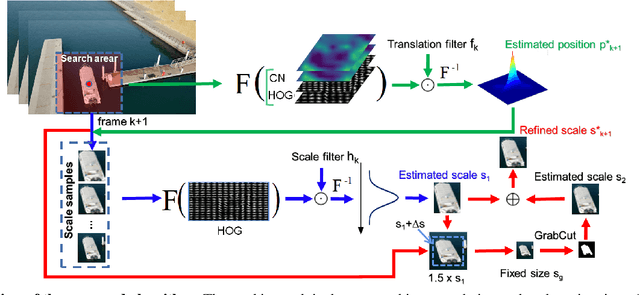
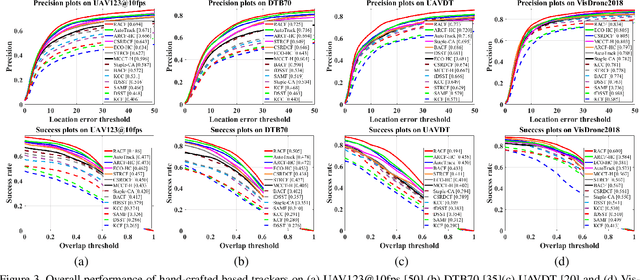
Unmanned aerial vehicle (UAV)-based tracking is attracting increasing attention and developing rapidly in applications such as agriculture, aviation, navigation, transportation and public security. Recently, discriminative correlation filters (DCF)-based trackers have stood out in UAV tracking community for their high efficiency and appealing robustness on a single CPU. However, due to limited onboard computation resources and other challenges the efficiency and accuracy of existing DCF-based approaches is still not satisfying. In this paper, we explore using segmentation by the GrabCut to improve the wildly adopted discriminative scale estimation in DCF-based trackers, which, as a mater of fact, greatly impacts the precision and accuracy of the trackers since accumulated scale error degrades the appearance model as online updating goes on. Meanwhile, inspired by residue representation, we exploit the residue nature inherent to videos and propose residue-aware correlation filters that show better convergence properties in filter learning. Extensive experiments are conducted on four UAV benchmarks, namely, UAV123@10fps, DTB70, UAVDT and Vistrone2018 (VisDrone2018-test-dev). The results show that our method achieves state-of-the-art performance.
The 1st Tiny Object Detection Challenge:Methods and Results
Oct 06, 2020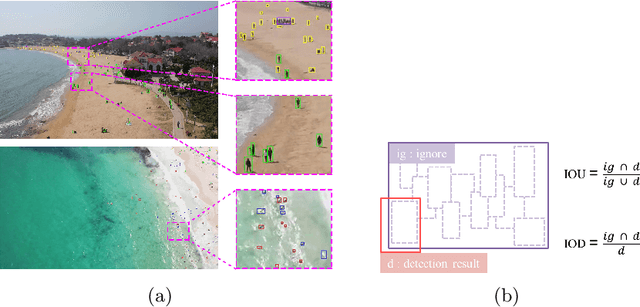
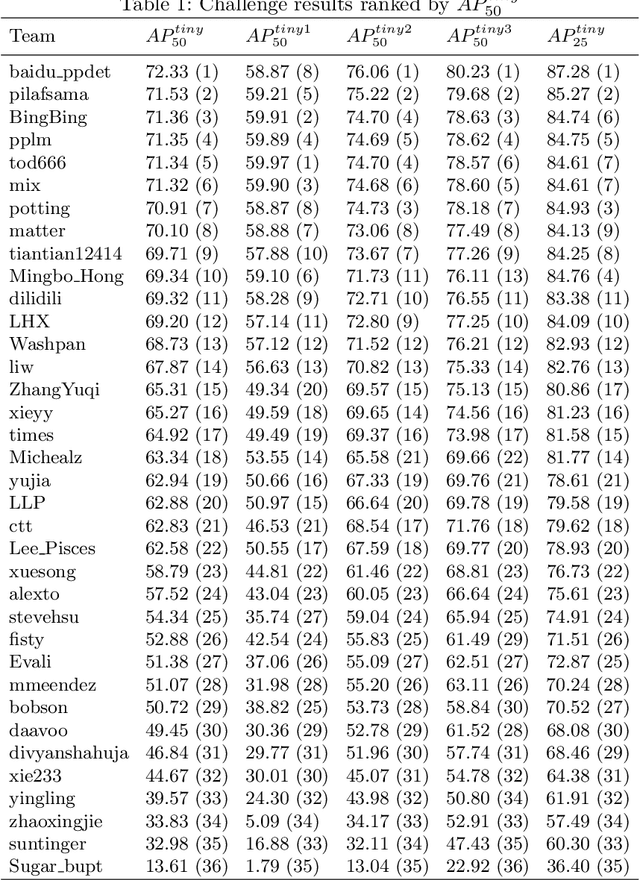
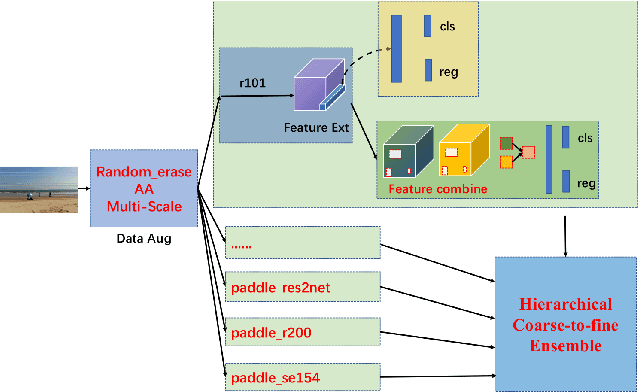

The 1st Tiny Object Detection (TOD) Challenge aims to encourage research in developing novel and accurate methods for tiny object detection in images which have wide views, with a current focus on tiny person detection. The TinyPerson dataset was used for the TOD Challenge and is publicly released. It has 1610 images and 72651 box-levelannotations. Around 36 participating teams from the globe competed inthe 1st TOD Challenge. In this paper, we provide a brief summary of the1st TOD Challenge including brief introductions to the top three methods.The submission leaderboard will be reopened for researchers that areinterested in the TOD challenge. The benchmark dataset and other information can be found at: https://github.com/ucas-vg/TinyBenchmark.