 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSifa Zheng
Neural Radiance Field in Autonomous Driving: A Survey
Apr 26, 2024
Neural Radiance Field (NeRF) has garnered significant attention from both academia and industry due to its intrinsic advantages, particularly its implicit representation and novel view synthesis capabilities. With the rapid advancements in deep learning, a multitude of methods have emerged to explore the potential applications of NeRF in the domain of Autonomous Driving (AD). However, a conspicuous void is apparent within the current literature. To bridge this gap, this paper conducts a comprehensive survey of NeRF's applications in the context of AD. Our survey is structured to categorize NeRF's applications in Autonomous Driving (AD), specifically encompassing perception, 3D reconstruction, simultaneous localization and mapping (SLAM), and simulation. We delve into in-depth analysis and summarize the findings for each application category, and conclude by providing insights and discussions on future directions in this field. We hope this paper serves as a comprehensive reference for researchers in this domain. To the best of our knowledge, this is the first survey specifically focused on the applications of NeRF in the Autonomous Driving domain.
What Truly Matters in Trajectory Prediction for Autonomous Driving?
Jun 27, 2023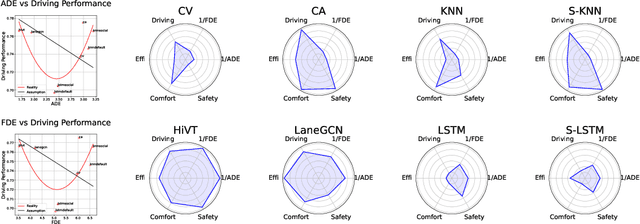
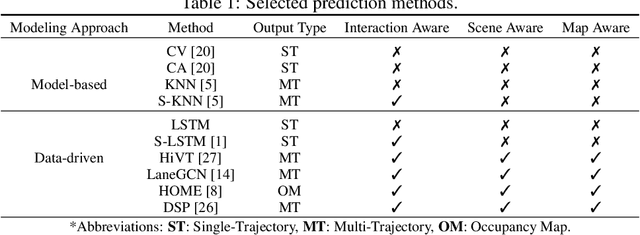
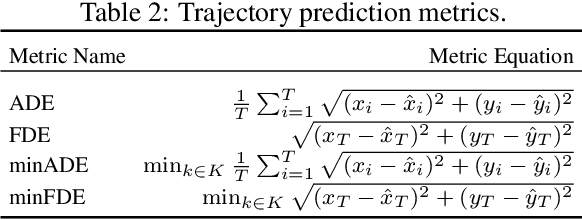
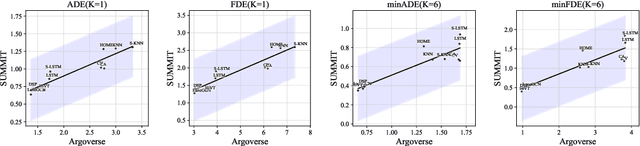
In the autonomous driving system, trajectory prediction plays a vital role in ensuring safety and facilitating smooth navigation. However, we observe a substantial discrepancy between the accuracy of predictors on fixed datasets and their driving performance when used in downstream tasks. This discrepancy arises from two overlooked factors in the current evaluation protocols of trajectory prediction: 1) the dynamics gap between the dataset and real driving scenario; and 2) the computational efficiency of predictors. In real-world scenarios, prediction algorithms influence the behavior of autonomous vehicles, which, in turn, alter the behaviors of other agents on the road. This interaction results in predictor-specific dynamics that directly impact prediction results. As other agents' responses are predetermined on datasets, a significant dynamics gap arises between evaluations conducted on fixed datasets and actual driving scenarios. Furthermore, focusing solely on accuracy fails to address the demand for computational efficiency, which is critical for the real-time response required by the autonomous driving system. Therefore, in this paper, we demonstrate that an interactive, task-driven evaluation approach for trajectory prediction is crucial to reflect its efficacy for autonomous driving.
Synthesize Efficient Safety Certificates for Learning-Based Safe Control using Magnitude Regularization
Sep 23, 2022



Energy-function-based safety certificates can provide provable safety guarantees for the safe control tasks of complex robotic systems. However, all recent studies about learning-based energy function synthesis only consider the feasibility, which might cause over-conservativeness and result in less efficient controllers. In this work, we proposed the magnitude regularization technique to improve the efficiency of safe controllers by reducing the conservativeness inside the energy function while keeping the promising provable safety guarantees. Specifically, we quantify the conservativeness by the magnitude of the energy function, and we reduce the conservativeness by adding a magnitude regularization term to the synthesis loss. We propose the SafeMR algorithm that uses reinforcement learning (RL) for the synthesis to unify the learning processes of safe controllers and energy functions. Experimental results show that the proposed method does reduce the conservativeness of the energy functions and outperforms the baselines in terms of the controller efficiency while guaranteeing safety.
Performance-Driven Controller Tuning via Derivative-Free Reinforcement Learning
Sep 11, 2022



Choosing an appropriate parameter set for the designed controller is critical for the final performance but usually requires a tedious and careful tuning process, which implies a strong need for automatic tuning methods. However, among existing methods, derivative-free ones suffer from poor scalability or low efficiency, while gradient-based ones are often unavailable due to possibly non-differentiable controller structure. To resolve the issues, we tackle the controller tuning problem using a novel derivative-free reinforcement learning (RL) framework, which performs timestep-wise perturbation in parameter space during experience collection and integrates derivative-free policy updates into the advanced actor-critic RL architecture to achieve high versatility and efficiency. To demonstrate the framework's efficacy, we conduct numerical experiments on two concrete examples from autonomous driving, namely, adaptive cruise control with PID controller and trajectory tracking with MPC controller. Experimental results show that the proposed method outperforms popular baselines and highlight its strong potential for controller tuning.
Zeroth-Order Actor-Critic
Jan 29, 2022



Zeroth-order optimization methods and policy gradient based first-order methods are two promising alternatives to solve reinforcement learning (RL) problems with complementary advantages. The former work with arbitrary policies, drive state-dependent and temporally-extended exploration, possess robustness-seeking property, but suffer from high sample complexity, while the latter are more sample efficient but restricted to differentiable policies and the learned policies are less robust. We propose Zeroth-Order Actor-Critic algorithm (ZOAC) that unifies these two methods into an on-policy actor-critic architecture to preserve the advantages from both. ZOAC conducts rollouts collection with timestep-wise perturbation in parameter space, first-order policy evaluation (PEV) and zeroth-order policy improvement (PIM) alternately in each iteration. We evaluate our proposed method on a range of challenging continuous control benchmarks using different types of policies, where ZOAC outperforms zeroth-order and first-order baseline algorithms.
Learn Zero-Constraint-Violation Policy in Model-Free Constrained Reinforcement Learning
Nov 25, 2021



In the trial-and-error mechanism of reinforcement learning (RL), a notorious contradiction arises when we expect to learn a safe policy: how to learn a safe policy without enough data and prior model about the dangerous region? Existing methods mostly use the posterior penalty for dangerous actions, which means that the agent is not penalized until experiencing danger. This fact causes that the agent cannot learn a zero-violation policy even after convergence. Otherwise, it would not receive any penalty and lose the knowledge about danger. In this paper, we propose the safe set actor-critic (SSAC) algorithm, which confines the policy update using safety-oriented energy functions, or the safety indexes. The safety index is designed to increase rapidly for potentially dangerous actions, which allows us to locate the safe set on the action space, or the control safe set. Therefore, we can identify the dangerous actions prior to taking them, and further obtain a zero constraint-violation policy after convergence.We claim that we can learn the energy function in a model-free manner similar to learning a value function. By using the energy function transition as the constraint objective, we formulate a constrained RL problem. We prove that our Lagrangian-based solutions make sure that the learned policy will converge to the constrained optimum under some assumptions. The proposed algorithm is evaluated on both the complex simulation environments and a hardware-in-loop (HIL) experiment with a real controller from the autonomous vehicle. Experimental results suggest that the converged policy in all environments achieves zero constraint violation and comparable performance with model-based baselines.
Joint Synthesis of Safety Certificate and Safe Control Policy using Constrained Reinforcement Learning
Nov 15, 2021



Safety is the major consideration in controlling complex dynamical systems using reinforcement learning (RL), where the safety certificate can provide provable safety guarantee. A valid safety certificate is an energy function indicating that safe states are with low energy, and there exists a corresponding safe control policy that allows the energy function to always dissipate. The safety certificate and the safe control policy are closely related to each other and both challenging to synthesize. Therefore, existing learning-based studies treat either of them as prior knowledge to learn the other, which limits their applicability with general unknown dynamics. This paper proposes a novel approach that simultaneously synthesizes the energy-function-based safety certificate and learns the safe control policy with CRL. We do not rely on prior knowledge about either an available model-based controller or a perfect safety certificate. In particular, we formulate a loss function to optimize the safety certificate parameters by minimizing the occurrence of energy increases. By adding this optimization procedure as an outer loop to the Lagrangian-based constrained reinforcement learning (CRL), we jointly update the policy and safety certificate parameters and prove that they will converge to their respective local optima, the optimal safe policy and a valid safety certificate. We evaluate our algorithms on multiple safety-critical benchmark environments. The results show that the proposed algorithm learns provably safe policies with no constraint violation. The validity or feasibility of synthesized safety certificate is also verified numerically.
Feasible Actor-Critic: Constrained Reinforcement Learning for Ensuring Statewise Safety
May 28, 2021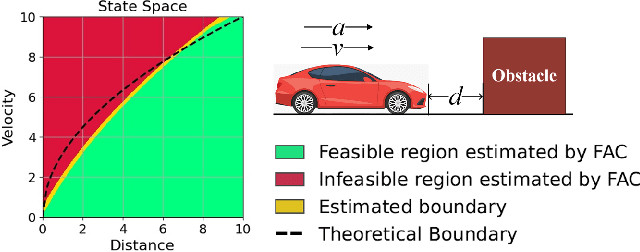


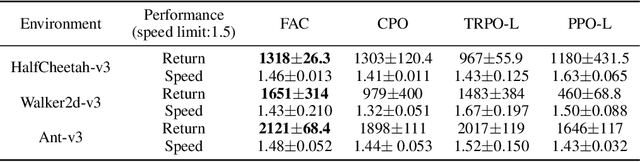
The safety constraints commonly used by existing safe reinforcement learning (RL) methods are defined only on expectation of initial states, but allow each certain state to be unsafe, which is unsatisfying for real-world safety-critical tasks. In this paper, we introduce the feasible actor-critic (FAC) algorithm, which is the first model-free constrained RL method that considers statewise safety, e.g, safety for each initial state. We claim that some states are inherently unsafe no matter what policy we choose, while for other states there exist policies ensuring safety, where we say such states and policies are feasible. By constructing a statewise Lagrange function available on RL sampling and adopting an additional neural network to approximate the statewise Lagrange multiplier, we manage to obtain the optimal feasible policy which ensures safety for each feasible state and the safest possible policy for infeasible states. Furthermore, the trained multiplier net can indicate whether a given state is feasible or not through the statewise complementary slackness condition. We provide theoretical guarantees that FAC outperforms previous expectation-based constrained RL methods in terms of both constraint satisfaction and reward optimization. Experimental results on both robot locomotive tasks and safe exploration tasks verify the safety enhancement and feasibility interpretation of the proposed method.
Model-based Constrained Reinforcement Learning using Generalized Control Barrier Function
Mar 05, 2021



Model information can be used to predict future trajectories, so it has huge potential to avoid dangerous region when implementing reinforcement learning (RL) on real-world tasks, like autonomous driving. However, existing studies mostly use model-free constrained RL, which causes inevitable constraint violations. This paper proposes a model-based feasibility enhancement technique of constrained RL, which enhances the feasibility of policy using generalized control barrier function (GCBF) defined on the distance to constraint boundary. By using the model information, the policy can be optimized safely without violating actual safety constraints, and the sample efficiency is increased. The major difficulty of infeasibility in solving the constrained policy gradient is handled by an adaptive coefficient mechanism. We evaluate the proposed method in both simulations and real vehicle experiments in a complex autonomous driving collision avoidance task. The proposed method achieves up to four times fewer constraint violations and converges 3.36 times faster than baseline constrained RL approaches.