 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSigurdur Sigurdsson
Hip Fracture Prediction using the First Principal Component Derived from FEA-Computed Fracture Loads
Oct 03, 2022
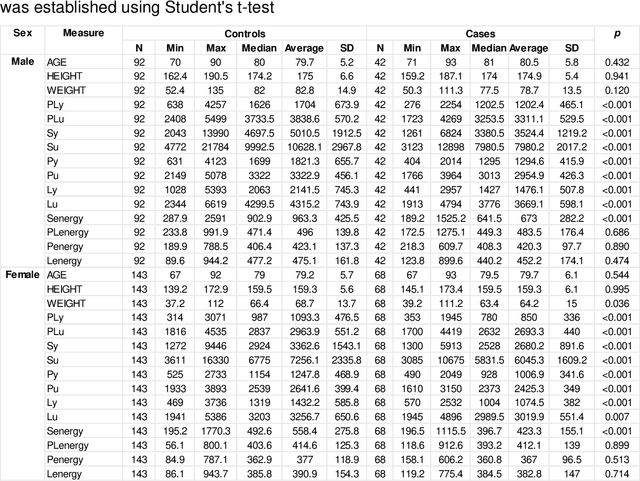
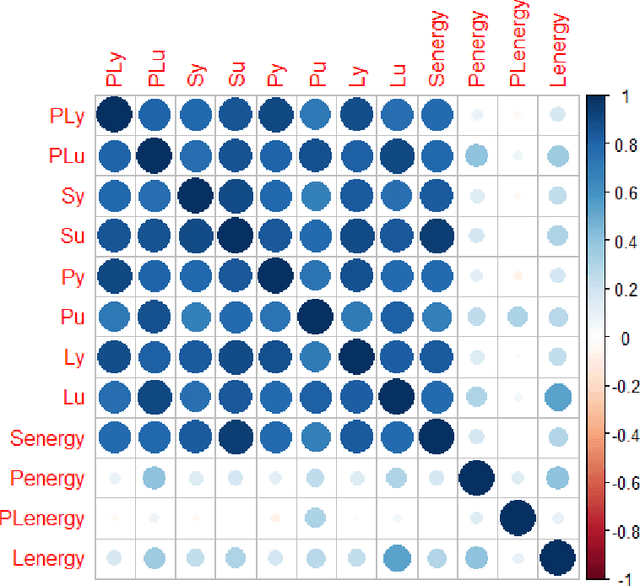
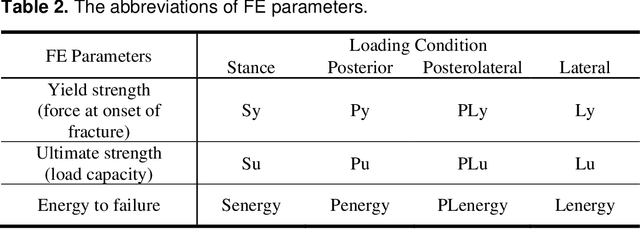
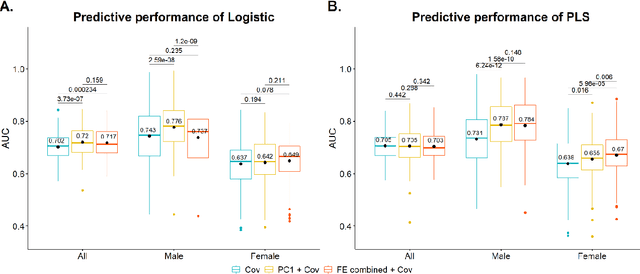
Hip fracture risk assessment is an important but challenging task. Quantitative CT-based patient specific finite element analysis (FEA) computes the force (fracture load) to break the proximal femur in a particular loading condition. It provides different structural information about the proximal femur that can influence a subject overall fracture risk. To obtain a more robust measure of fracture risk, we used principal component analysis (PCA) to develop a global FEA computed fracture risk index that incorporates the FEA-computed yield and ultimate failure loads and energies to failure in four loading conditions (single-limb stance and impact from a fall onto the posterior, posterolateral, and lateral aspects of the greater trochanter) of 110 hip fracture subjects and 235 age and sex matched control subjects from the AGES-Reykjavik study. We found that the first PC (PC1) of the FE parameters was the only significant predictor of hip fracture. Using a logistic regression model, we determined if prediction performance for hip fracture using PC1 differed from that using FE parameters combined by stratified random resampling with respect to hip fracture status. The results showed that the average of the area under the receive operating characteristic curve (AUC) using PC1 was always higher than that using all FE parameters combined in the male subjects. The AUC of PC1 and AUC of the FE parameters combined were not significantly different than that in the female subjects or in all subjects
Fast and Robust Femur Segmentation from Computed Tomography Images for Patient-Specific Hip Fracture Risk Screening
Apr 20, 2022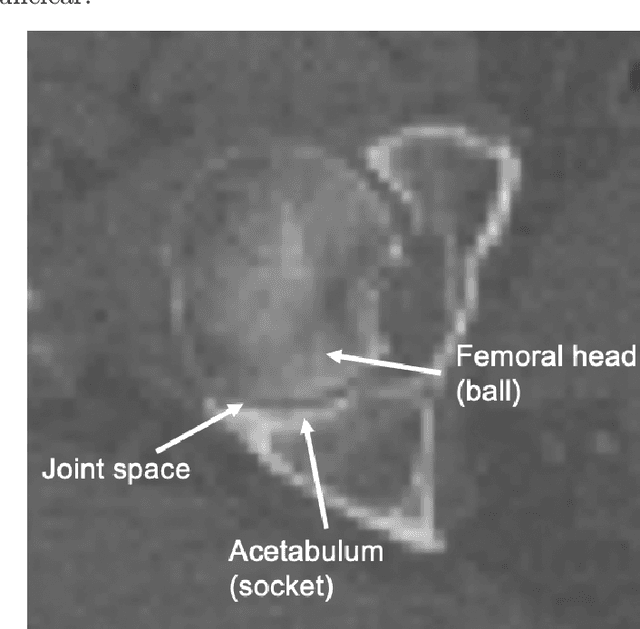
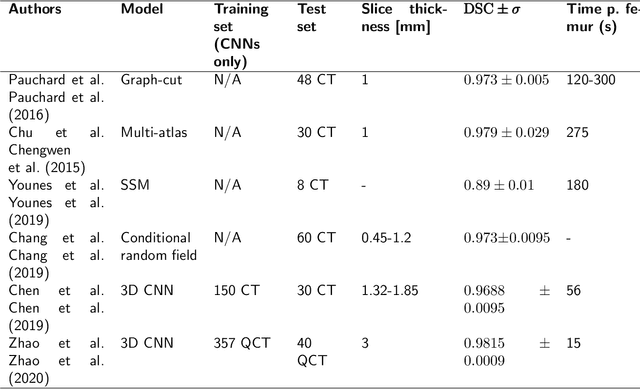
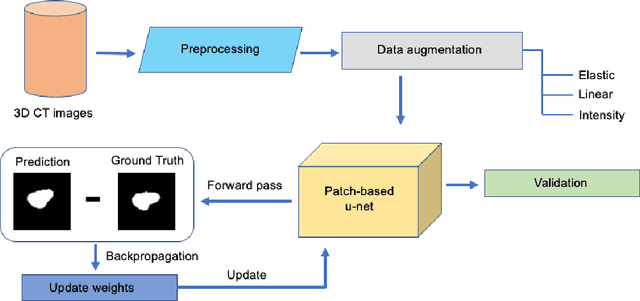
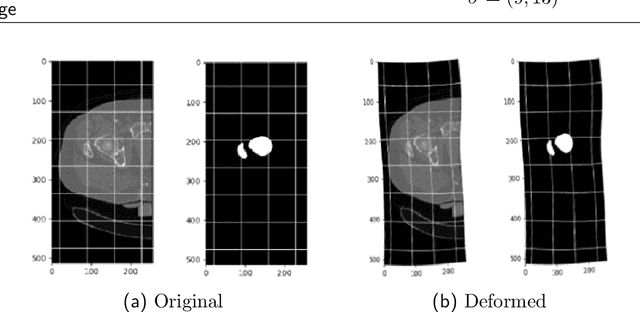
Osteoporosis is a common bone disease that increases the risk of bone fracture. Hip-fracture risk screening methods based on finite element analysis depend on segmented computed tomography (CT) images; however, current femur segmentation methods require manual delineations of large data sets. Here we propose a deep neural network for fully automated, accurate, and fast segmentation of the proximal femur from CT. Evaluation on a set of 1147 proximal femurs with ground truth segmentations demonstrates that our method is apt for hip-fracture risk screening, bringing us one step closer to a clinically viable option for screening at-risk patients for hip-fracture susceptibility.
Deep-Learning-Based Audio-Visual Speech Enhancement in Presence of Lombard Effect
May 29, 2019
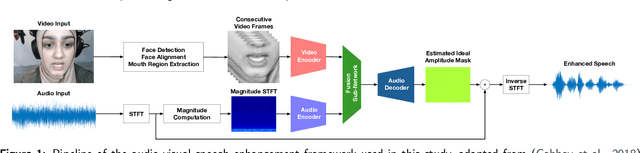
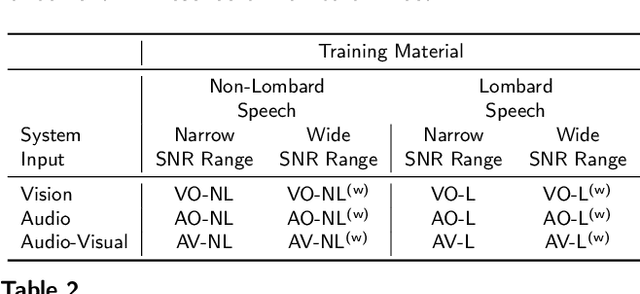
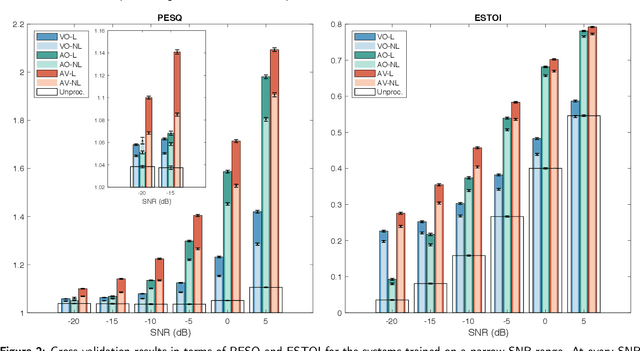
When speaking in presence of background noise, humans reflexively change their way of speaking in order to improve the intelligibility of their speech. This reflex is known as Lombard effect. Collecting speech in Lombard conditions is usually hard and costly. For this reason, speech enhancement systems are generally trained and evaluated on speech recorded in quiet to which noise is artificially added. Since these systems are often used in situations where Lombard speech occurs, in this work we perform an analysis of the impact that Lombard effect has on audio, visual and audio-visual speech enhancement, focusing on deep-learning-based systems, since they represent the current state of the art in the field. We conduct several experiments using an audio-visual Lombard speech corpus consisting of utterances spoken by 54 different talkers. The results show that training deep-learning-based models with Lombard speech is beneficial in terms of both estimated speech quality and estimated speech intelligibility at low signal to noise ratios, where the visual modality can play an important role in acoustically challenging situations. We also find that a performance difference between genders exists due to the distinct Lombard speech exhibited by males and females, and we analyse it in relation with acoustic and visual features. Furthermore, listening tests conducted with audio-visual stimuli show that the speech quality of the signals processed with systems trained using Lombard speech is statistically significantly better than the one obtained using systems trained with non-Lombard speech at a signal to noise ratio of -5 dB. Regarding speech intelligibility, we find a general tendency of the benefit in training the systems with Lombard speech.
Unsupervised brain lesion segmentation from MRI using a convolutional autoencoder
Nov 23, 2018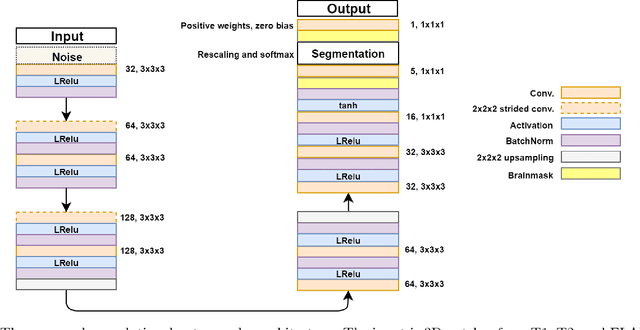
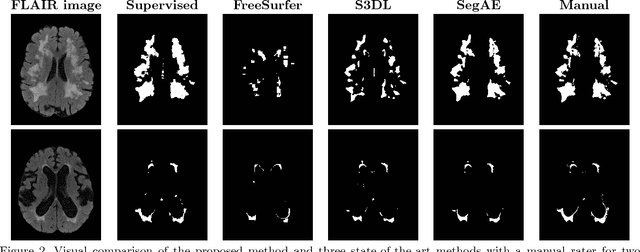

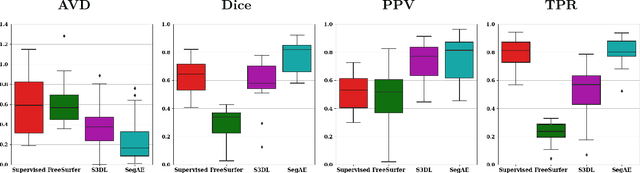
Lesions that appear hyperintense in both Fluid Attenuated Inversion Recovery (FLAIR) and T2-weighted magnetic resonance images (MRIs) of the human brain are common in the brains of the elderly population and may be caused by ischemia or demyelination. Lesions are biomarkers for various neurodegenerative diseases, making accurate quantification of them important for both disease diagnosis and progression. Automatic lesion detection using supervised learning requires manually annotated images, which can often be impractical to acquire. Unsupervised lesion detection, on the other hand, does not require any manual delineation; however, these methods can be challenging to construct due to the variability in lesion load, placement of lesions, and voxel intensities. Here we present a novel approach to address this problem using a convolutional autoencoder, which learns to segment brain lesions as well as the white matter, gray matter, and cerebrospinal fluid by reconstructing FLAIR images as conical combinations of softmax layer outputs generated from the corresponding T1, T2, and FLAIR images. Some of the advantages of this model are that it accurately learns to segment lesions regardless of lesion load, and it can be used to quickly and robustly segment new images that were not in the training set. Comparisons with state-of-the-art segmentation methods evaluated on ground truth manual labels indicate that the proposed method works well for generating accurate lesion segmentations without the need for manual annotations.
Effects of Lombard Reflex on the Performance of Deep-Learning-Based Audio-Visual Speech Enhancement Systems
Nov 15, 2018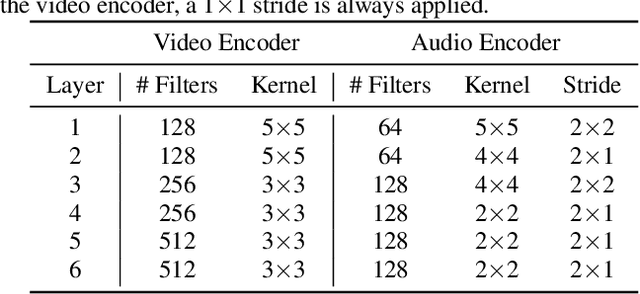
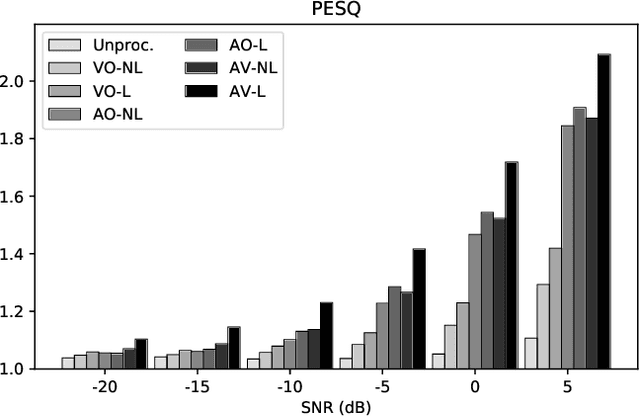

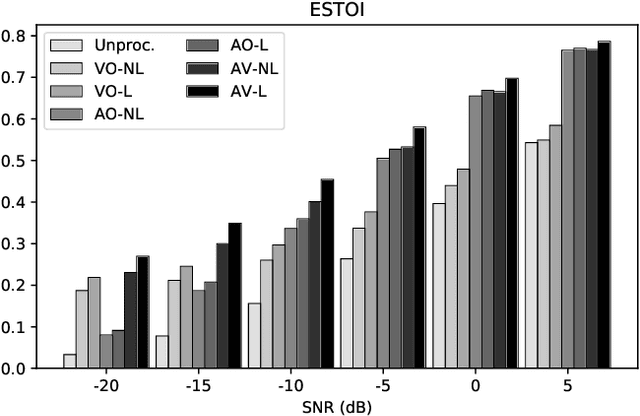
Humans tend to change their way of speaking when they are immersed in a noisy environment, a reflex known as Lombard effect. Current speech enhancement systems based on deep learning do not usually take into account this change in the speaking style, because they are trained with neutral (non-Lombard) speech utterances recorded under quiet conditions to which noise is artificially added. In this paper, we investigate the effects that the Lombard reflex has on the performance of audio-visual speech enhancement systems based on deep learning. The results show that a gap in the performance of as much as approximately 5 dB between the systems trained on neutral speech and the ones trained on Lombard speech exists. This indicates the benefit of taking into account the mismatch between neutral and Lombard speech in the design of audio-visual speech enhancement systems.
On Training Targets and Objective Functions for Deep-Learning-Based Audio-Visual Speech Enhancement
Nov 15, 2018
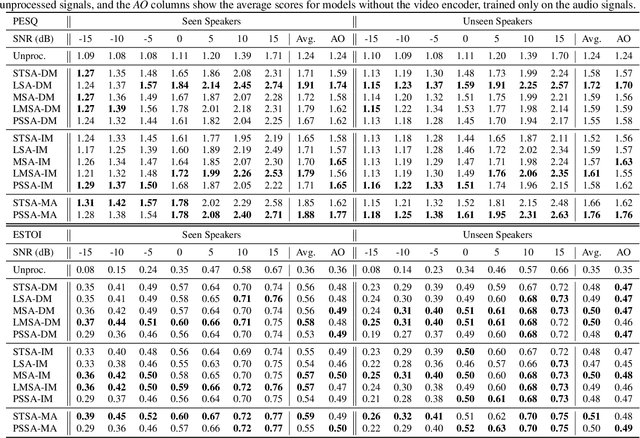
Audio-visual speech enhancement (AV-SE) is the task of improving speech quality and intelligibility in a noisy environment using audio and visual information from a talker. Recently, deep learning techniques have been adopted to solve the AV-SE task in a supervised manner. In this context, the choice of the target, i.e. the quantity to be estimated, and the objective function, which quantifies the quality of this estimate, to be used for training is critical for the performance. This work is the first that presents an experimental study of a range of different targets and objective functions used to train a deep-learning-based AV-SE system. The results show that the approaches that directly estimate a mask perform the best overall in terms of estimated speech quality and intelligibility, although the model that directly estimates the log magnitude spectrum performs as good in terms of estimated speech quality.