 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSihun Baek
Differentially Private CutMix for Split Learning with Vision Transformer
Oct 28, 2022
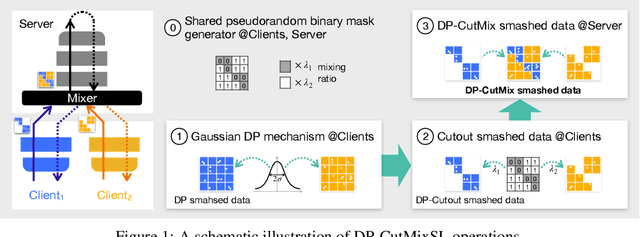
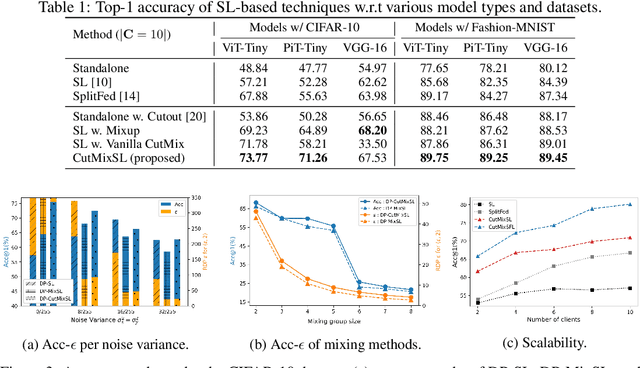

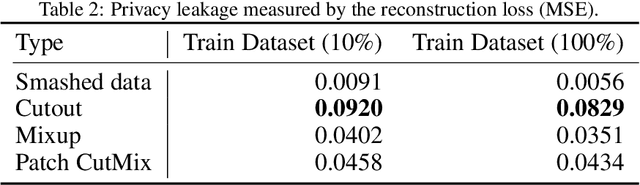
Recently, vision transformer (ViT) has started to outpace the conventional CNN in computer vision tasks. Considering privacy-preserving distributed learning with ViT, federated learning (FL) communicates models, which becomes ill-suited due to ViT' s large model size and computing costs. Split learning (SL) detours this by communicating smashed data at a cut-layer, yet suffers from data privacy leakage and large communication costs caused by high similarity between ViT' s smashed data and input data. Motivated by this problem, we propose DP-CutMixSL, a differentially private (DP) SL framework by developing DP patch-level randomized CutMix (DP-CutMix), a novel privacy-preserving inter-client interpolation scheme that replaces randomly selected patches in smashed data. By experiment, we show that DP-CutMixSL not only boosts privacy guarantees and communication efficiency, but also achieves higher accuracy than its Vanilla SL counterpart. Theoretically, we analyze that DP-CutMix amplifies R\'enyi DP (RDP), which is upper-bounded by its Vanilla Mixup counterpart.
Visual Transformer Meets CutMix for Improved Accuracy, Communication Efficiency, and Data Privacy in Split Learning
Jul 01, 2022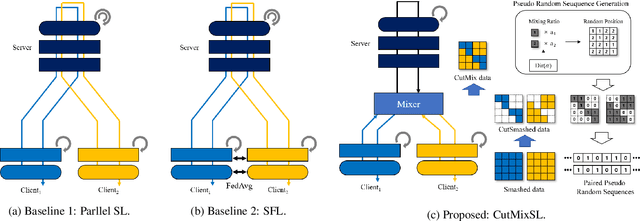
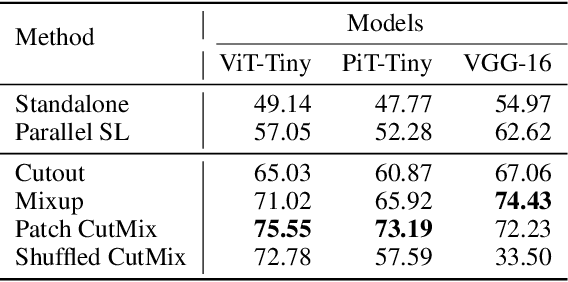
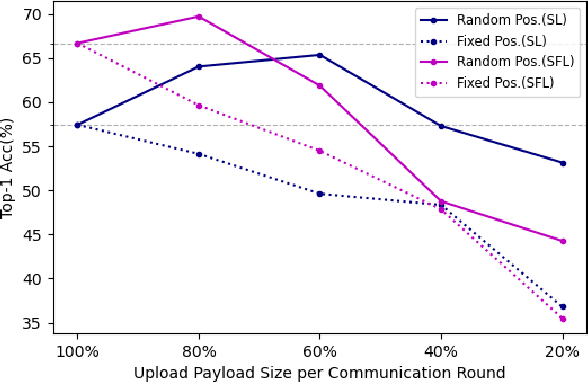
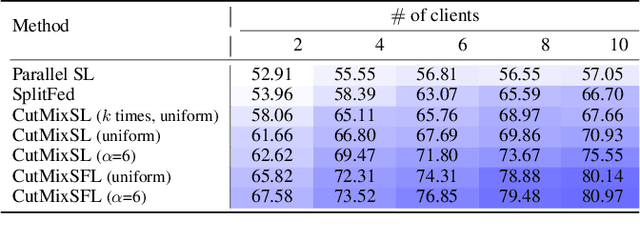
This article seeks for a distributed learning solution for the visual transformer (ViT) architectures. Compared to convolutional neural network (CNN) architectures, ViTs often have larger model sizes, and are computationally expensive, making federated learning (FL) ill-suited. Split learning (SL) can detour this problem by splitting a model and communicating the hidden representations at the split-layer, also known as smashed data. Notwithstanding, the smashed data of ViT are as large as and as similar as the input data, negating the communication efficiency of SL while violating data privacy. To resolve these issues, we propose a new form of CutSmashed data by randomly punching and compressing the original smashed data. Leveraging this, we develop a novel SL framework for ViT, coined CutMixSL, communicating CutSmashed data. CutMixSL not only reduces communication costs and privacy leakage, but also inherently involves the CutMix data augmentation, improving accuracy and scalability. Simulations corroborate that CutMixSL outperforms baselines such as parallelized SL and SplitFed that integrates FL with SL.