 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimin Fan
MEDITRON-70B: Scaling Medical Pretraining for Large Language Models
Nov 27, 2023
Large language models (LLMs) can potentially democratize access to medical knowledge. While many efforts have been made to harness and improve LLMs' medical knowledge and reasoning capacities, the resulting models are either closed-source (e.g., PaLM, GPT-4) or limited in scale (<= 13B parameters), which restricts their abilities. In this work, we improve access to large-scale medical LLMs by releasing MEDITRON: a suite of open-source LLMs with 7B and 70B parameters adapted to the medical domain. MEDITRON builds on Llama-2 (through our adaptation of Nvidia's Megatron-LM distributed trainer), and extends pretraining on a comprehensively curated medical corpus, including selected PubMed articles, abstracts, and internationally-recognized medical guidelines. Evaluations using four major medical benchmarks show significant performance gains over several state-of-the-art baselines before and after task-specific finetuning. Overall, MEDITRON achieves a 6% absolute performance gain over the best public baseline in its parameter class and 3% over the strongest baseline we finetuned from Llama-2. Compared to closed-source LLMs, MEDITRON-70B outperforms GPT-3.5 and Med-PaLM and is within 5% of GPT-4 and 10% of Med-PaLM-2. We release our code for curating the medical pretraining corpus and the MEDITRON model weights to drive open-source development of more capable medical LLMs.
DoGE: Domain Reweighting with Generalization Estimation
Oct 23, 2023The coverage and composition of the pretraining data corpus significantly impacts the generalization ability of large language models. Conventionally, the pretraining corpus is composed of various source domains (e.g. CommonCrawl, Wikipedia, Github etc.) according to certain sampling probabilities (domain weights). However, current methods lack a principled way to optimize domain weights for ultimate goal for generalization. We propose DOmain reweighting with Generalization Estimation (DoGE), where we reweigh the sampling probability from each domain based on its contribution to the final generalization objective assessed by a gradient-based generalization estimation function. First, we train a small-scale proxy model with a min-max optimization to obtain the reweighted domain weights. At each step, the domain weights are updated to maximize the overall generalization gain by mirror descent. Finally we use the obtained domain weights to train a larger scale full-size language model. On SlimPajama-6B dataset, with universal generalization objective, DoGE achieves better average perplexity and zero-shot reasoning accuracy. On out-of-domain generalization tasks, DoGE reduces perplexity on the target domain by a large margin. We further apply a parameter-selection scheme which improves the efficiency of generalization estimation.
Irreducible Curriculum for Language Model Pretraining
Oct 23, 2023Automatic data selection and curriculum design for training large language models is challenging, with only a few existing methods showing improvements over standard training. Furthermore, current schemes focus on domain-level selection, overlooking the more fine-grained contributions of each individual training point. It is difficult to apply traditional datapoint selection methods on large language models: most online batch selection methods perform two-times forward or backward passes, which introduces considerable extra costs with large-scale models. To mitigate these obstacles, we propose irreducible curriculum as a curriculum learning algorithm for language model pretraining, which prioritizes samples with higher learnability. Specifically, to avoid prohibitive extra computation overhead, we simulate the sample loss along the main model's training trajectory using a small-scale proxy model. Our experiments on the RedPajama-1B dataset demonstrate a consistent improvement on validation perplexity across all 7 domains compared to random uniform baseline and the anti-curriculum strategy. Our method also reduces the sharpness of the network and illustrates a better 5-shot accuracy on MMLU benchmarks.
Towards Process-Oriented, Modular, and Versatile Question Generation that Meets Educational Needs
Apr 30, 2022
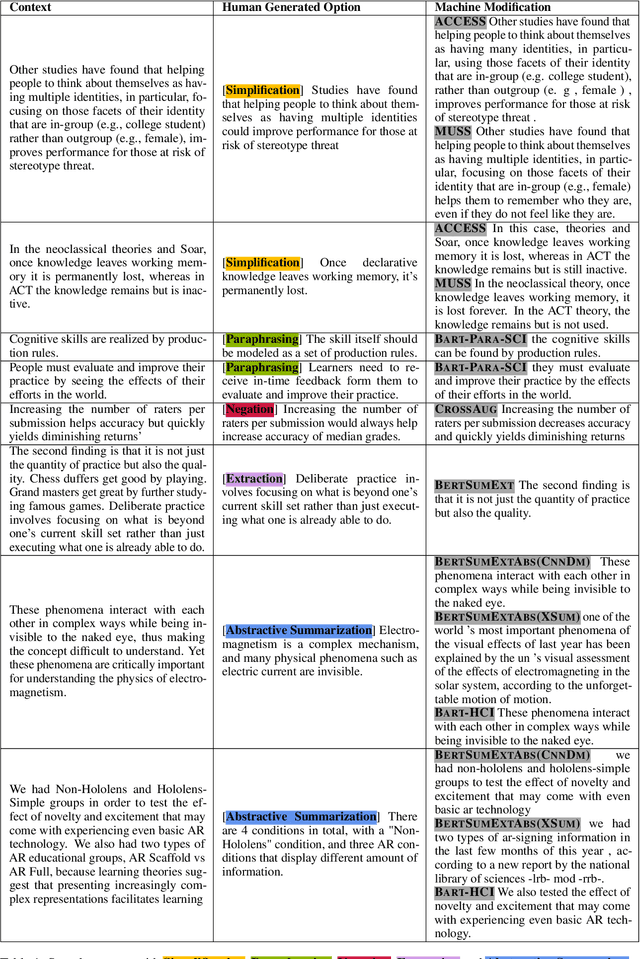

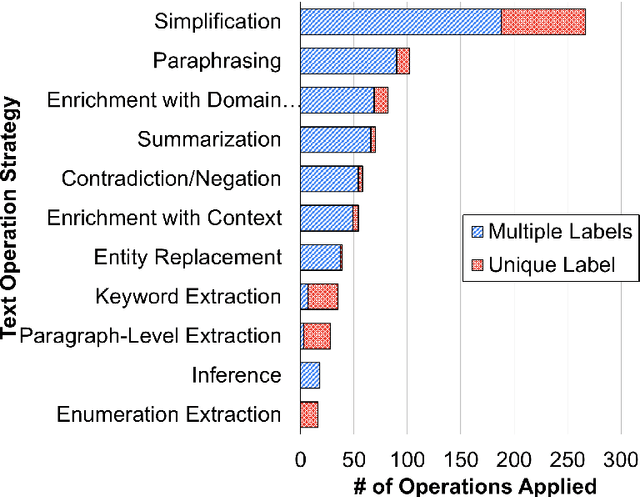
NLP-powered automatic question generation (QG) techniques carry great pedagogical potential of saving educators' time and benefiting student learning. Yet, QG systems have not been widely adopted in classrooms to date. In this work, we aim to pinpoint key impediments and investigate how to improve the usability of automatic QG techniques for educational purposes by understanding how instructors construct questions and identifying touch points to enhance the underlying NLP models. We perform an in-depth need finding study with 11 instructors across 7 different universities, and summarize their thought processes and needs when creating questions. While instructors show great interests in using NLP systems to support question design, none of them has used such tools in practice. They resort to multiple sources of information, ranging from domain knowledge to students' misconceptions, all of which missing from today's QG systems. We argue that building effective human-NLP collaborative QG systems that emphasize instructor control and explainability is imperative for real-world adoption. We call for QG systems to provide process-oriented support, use modular design, and handle diverse sources of input.