 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSiyuan Ma
JailBreakV-28K: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks
Apr 03, 2024
With the rapid advancements in Multimodal Large Language Models (MLLMs), securing these models against malicious inputs while aligning them with human values has emerged as a critical challenge. In this paper, we investigate an important and unexplored question of whether techniques that successfully jailbreak Large Language Models (LLMs) can be equally effective in jailbreaking MLLMs. To explore this issue, we introduce JailBreakV-28K, a pioneering benchmark designed to assess the transferability of LLM jailbreak techniques to MLLMs, thereby evaluating the robustness of MLLMs against diverse jailbreak attacks. Utilizing a dataset of 2, 000 malicious queries that is also proposed in this paper, we generate 20, 000 text-based jailbreak prompts using advanced jailbreak attacks on LLMs, alongside 8, 000 image-based jailbreak inputs from recent MLLMs jailbreak attacks, our comprehensive dataset includes 28, 000 test cases across a spectrum of adversarial scenarios. Our evaluation of 10 open-source MLLMs reveals a notably high Attack Success Rate (ASR) for attacks transferred from LLMs, highlighting a critical vulnerability in MLLMs that stems from their text-processing capabilities. Our findings underscore the urgent need for future research to address alignment vulnerabilities in MLLMs from both textual and visual inputs.
Understanding News Creation Intents: Frame, Dataset, and Method
Dec 27, 2023As the disruptive changes in the media economy and the proliferation of alternative news media outlets, news intent has progressively deviated from ethical standards that serve the public interest. News intent refers to the purpose or intention behind the creation of a news article. While the significance of research on news intent has been widely acknowledged, the absence of a systematic news intent understanding framework hinders further exploration of news intent and its downstream applications. To bridge this gap, we propose News INTent (NINT) frame, the first component-aware formalism for understanding the news creation intent based on research in philosophy, psychology, and cognitive science. Within this frame, we define the news intent identification task and provide a benchmark dataset with fine-grained labels along with an efficient benchmark method. Experiments demonstrate that NINT is beneficial in both the intent identification task and downstream tasks that demand a profound understanding of news. This work marks a foundational step towards a more systematic exploration of news creation intents.
Summary of ChatGPT/GPT-4 Research and Perspective Towards the Future of Large Language Models
Apr 08, 2023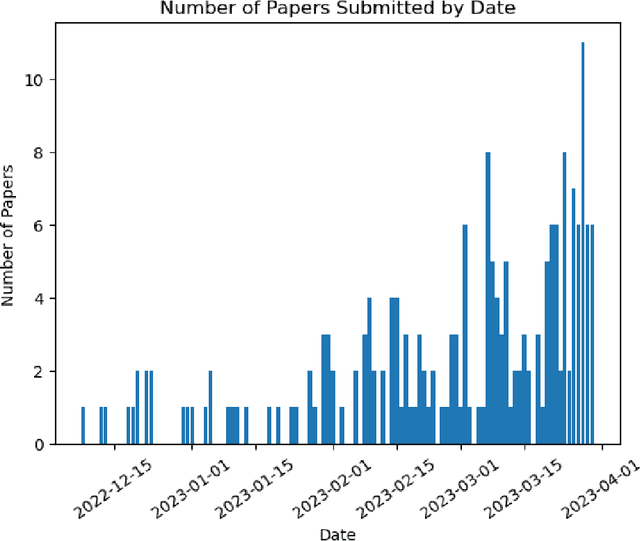

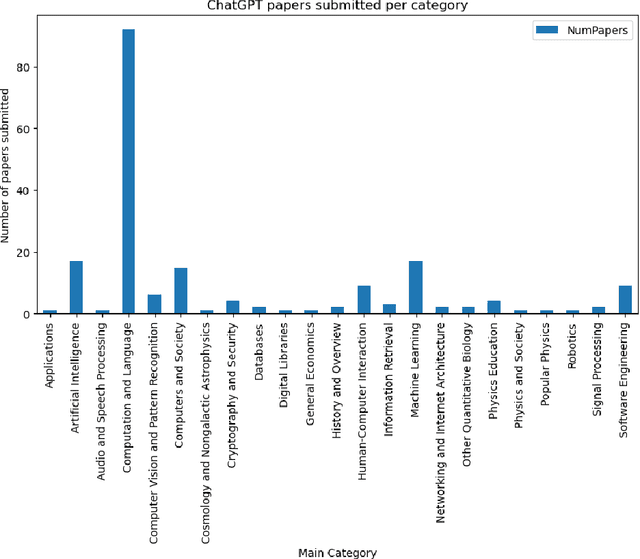
This paper presents a comprehensive survey of ChatGPT and GPT-4, state-of-the-art large language models (LLM) from the GPT series, and their prospective applications across diverse domains. Indeed, key innovations such as large-scale pre-training that captures knowledge across the entire world wide web, instruction fine-tuning and Reinforcement Learning from Human Feedback (RLHF) have played significant roles in enhancing LLMs' adaptability and performance. We performed an in-depth analysis of 194 relevant papers on arXiv, encompassing trend analysis, word cloud representation, and distribution analysis across various application domains. The findings reveal a significant and increasing interest in ChatGPT/GPT-4 research, predominantly centered on direct natural language processing applications, while also demonstrating considerable potential in areas ranging from education and history to mathematics, medicine, and physics. This study endeavors to furnish insights into ChatGPT's capabilities, potential implications, ethical concerns, and offer direction for future advancements in this field.
Learning the joint distribution of two sequences using little or no paired data
Dec 06, 2022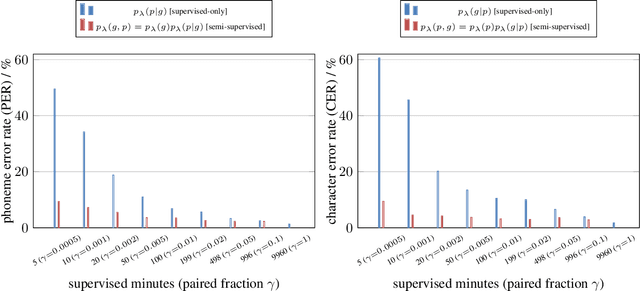
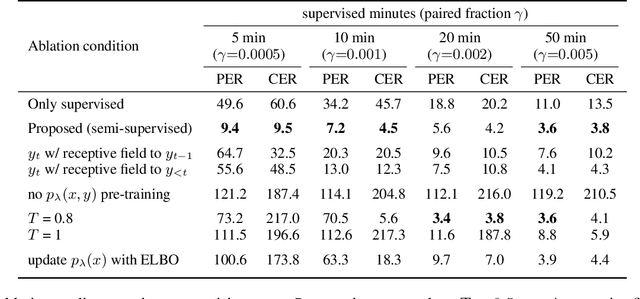

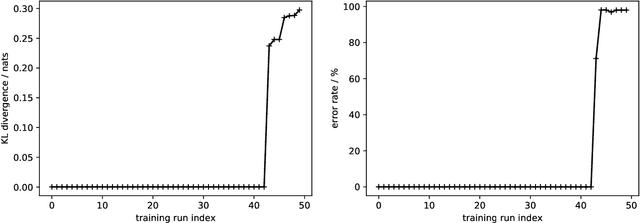
We present a noisy channel generative model of two sequences, for example text and speech, which enables uncovering the association between the two modalities when limited paired data is available. To address the intractability of the exact model under a realistic data setup, we propose a variational inference approximation. To train this variational model with categorical data, we propose a KL encoder loss approach which has connections to the wake-sleep algorithm. Identifying the joint or conditional distributions by only observing unpaired samples from the marginals is only possible under certain conditions in the data distribution and we discuss under what type of conditional independence assumptions that might be achieved, which guides the architecture designs. Experimental results show that even tiny amount of paired data (5 minutes) is sufficient to learn to relate the two modalities (graphemes and phonemes here) when a massive amount of unpaired data is available, paving the path to adopting this principled approach for all seq2seq models in low data resource regimes.
Gated Transformer Networks for Multivariate Time Series Classification
Mar 26, 2021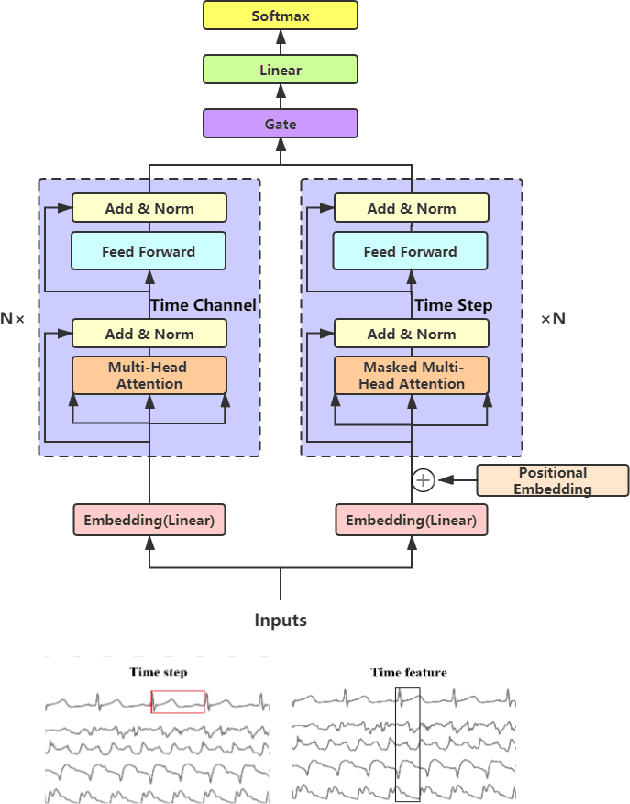
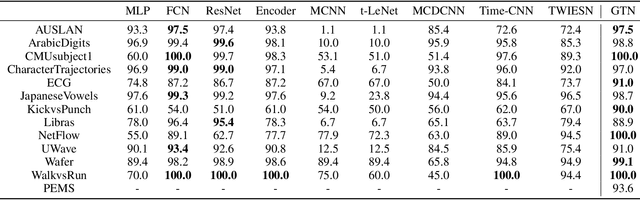
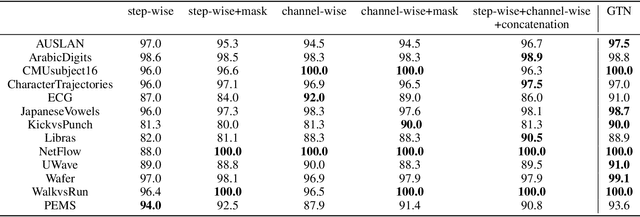
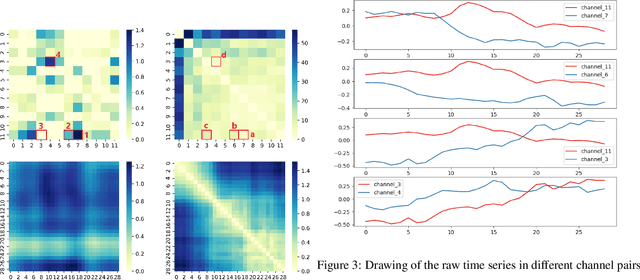
Deep learning model (primarily convolutional networks and LSTM) for time series classification has been studied broadly by the community with the wide applications in different domains like healthcare, finance, industrial engineering and IoT. Meanwhile, Transformer Networks recently achieved frontier performance on various natural language processing and computer vision tasks. In this work, we explored a simple extension of the current Transformer Networks with gating, named Gated Transformer Networks (GTN) for the multivariate time series classification problem. With the gating that merges two towers of Transformer which model the channel-wise and step-wise correlations respectively, we show how GTN is naturally and effectively suitable for the multivariate time series classification task. We conduct comprehensive experiments on thirteen dataset with full ablation study. Our results show that GTN is able to achieve competing results with current state-of-the-art deep learning models. We also explored the attention map for the natural interpretability of GTN on time series modeling. Our preliminary results provide a strong baseline for the Transformer Networks on multivariate time series classification task and grounds the foundation for future research.
Reconciling modern machine learning and the bias-variance trade-off
Dec 28, 2018
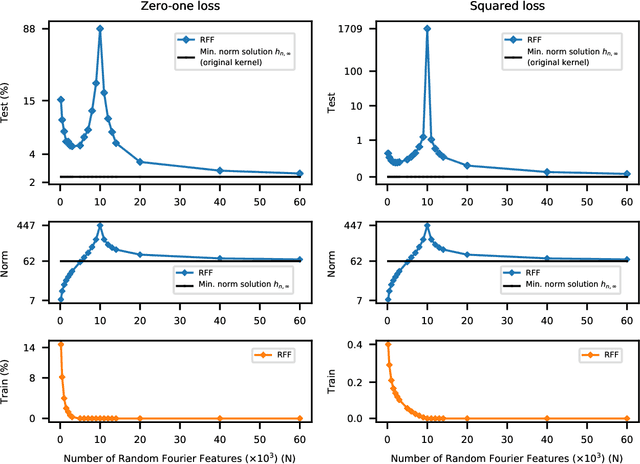
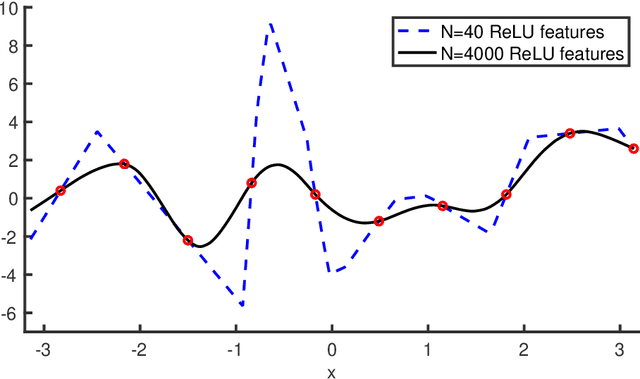
The question of generalization in machine learning---how algorithms are able to learn predictors from a training sample to make accurate predictions out-of-sample---is revisited in light of the recent breakthroughs in modern machine learning technology. The classical approach to understanding generalization is based on bias-variance trade-offs, where model complexity is carefully calibrated so that the fit on the training sample reflects performance out-of-sample. However, it is now common practice to fit highly complex models like deep neural networks to data with (nearly) zero training error, and yet these interpolating predictors are observed to have good out-of-sample accuracy even for noisy data. How can the classical understanding of generalization be reconciled with these observations from modern machine learning practice? In this paper, we bridge the two regimes by exhibiting a new "double descent" risk curve that extends the traditional U-shaped bias-variance curve beyond the point of interpolation. Specifically, the curve shows that as soon as the model complexity is high enough to achieve interpolation on the training sample---a point that we call the "interpolation threshold"---the risk of suitably chosen interpolating predictors from these models can, in fact, be decreasing as the model complexity increases, often below the risk achieved using non-interpolating models. The double descent risk curve is demonstrated for a broad range of models, including neural networks and random forests, and a mechanism for producing this behavior is posited.
On exponential convergence of SGD in non-convex over-parametrized learning
Nov 06, 2018Large over-parametrized models learned via stochastic gradient descent (SGD) methods have become a key element in modern machine learning. Although SGD methods are very effective in practice, most theoretical analyses of SGD suggest slower convergence than what is empirically observed. In our recent work [8] we analyzed how interpolation, common in modern over-parametrized learning, results in exponential convergence of SGD with constant step size for convex loss functions. In this note, we extend those results to a much broader non-convex function class satisfying the Polyak-Lojasiewicz (PL) condition. A number of important non-convex problems in machine learning, including some classes of neural networks, have been recently shown to satisfy the PL condition. We argue that the PL condition provides a relevant and attractive setting for many machine learning problems, particularly in the over-parametrized regime.
Kernel Machines Beat Deep Neural Networks on Mask-based Single-channel Speech Enhancement
Nov 06, 2018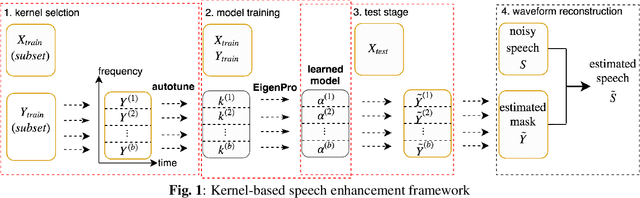

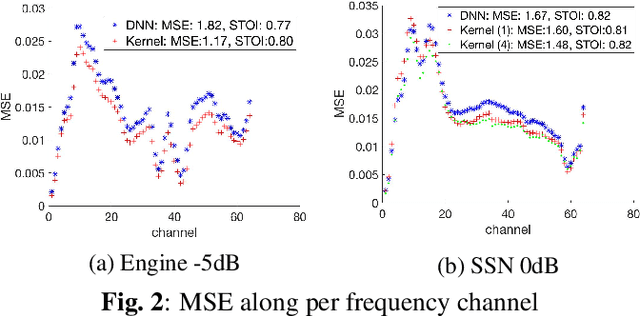
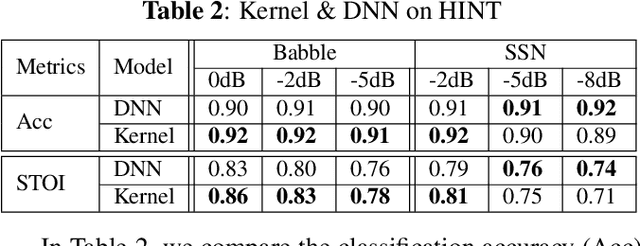
We apply a fast kernel method for mask-based single-channel speech enhancement. Specifically, our method solves a kernel regression problem associated to a non-smooth kernel function (exponential power kernel) with a highly efficient iterative method (EigenPro). Due to the simplicity of this method, its hyper-parameters such as kernel bandwidth can be automatically and efficiently selected using line search with subsamples of training data. We observe an empirical correlation between the regression loss (mean square error) and regular metrics for speech enhancement. This observation justifies our training target and motivates us to achieve lower regression loss by training separate kernel model per frequency subband. We compare our method with the state-of-the-art deep neural networks on mask-based HINT and TIMIT. Experimental results show that our kernel method consistently outperforms deep neural networks while requiring less training time.
Learning kernels that adapt to GPU
Oct 19, 2018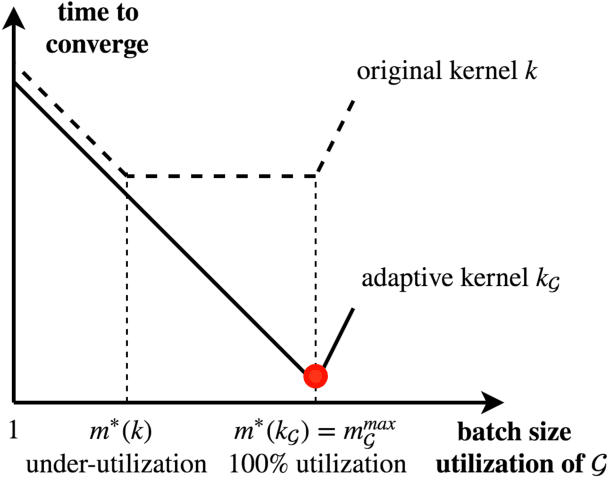
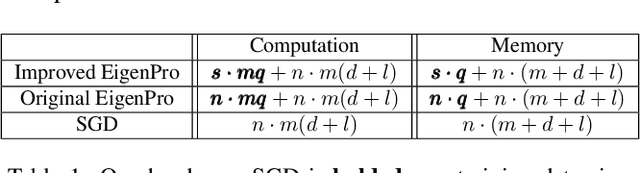

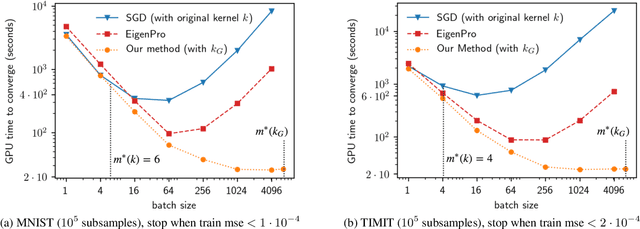
In this work we develop a framework for kernel machines that are efficient, accurate and are adaptive to modern parallel hardware, such as GPU. Our main innovation is in constructing kernel machines that output solutions mathematically equivalent to those obtained using standard kernels, yet capable of fully utilizing the available computing power of a parallel computational resource. Such utilization is key to strong performance as much of the computational resource capability is wasted by the standard iterative methods. Our approach is based on the idea of interpolation, using the significant empirical evidence that methods achieving near-zero training error show excellent test results. In this work we show how the mathematical and conceptual simplicity of optimization in the interpolation regime can be harnessed to design kernels and automatically choose parameters adaptive to computational resources. The resulting algorithm, which we call \textit{EigenPro 2.0}, is accurate, principled and very fast. For example, using a single Titan XP GPU, training on ImageNet with $1.3\times 10^6$ data points and $1000$ labels takes under an hour, while smaller datasets, such as MNIST, take seconds. As the parameters are chosen analytically, based on the theoretical bounds, little tuning beyond selecting the kernel and kernel parameter is needed, further facilitating the practical use of these methods.
To understand deep learning we need to understand kernel learning
Jun 14, 2018
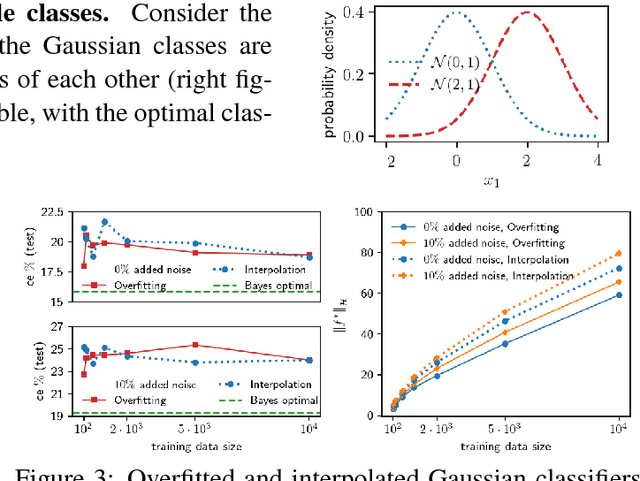
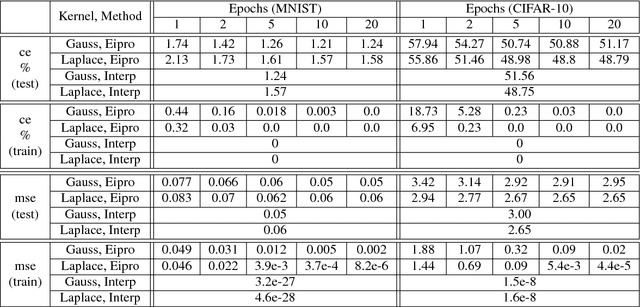
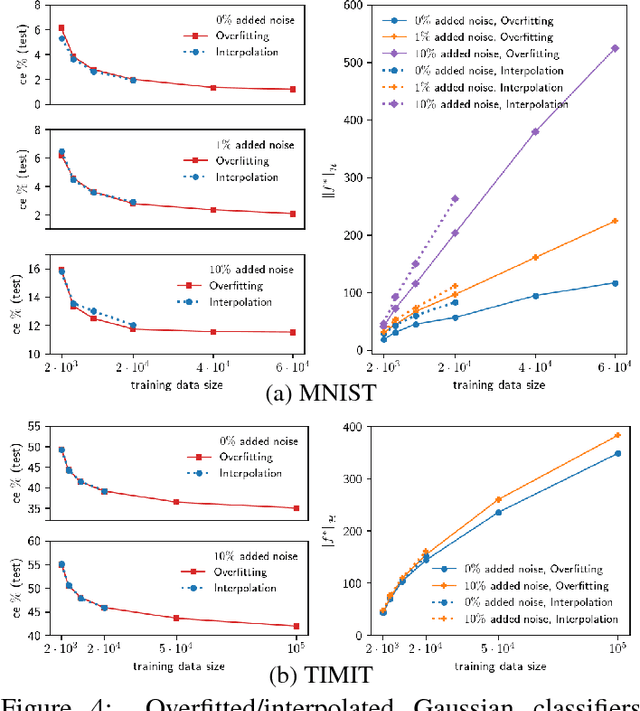
Generalization performance of classifiers in deep learning has recently become a subject of intense study. Deep models, typically over-parametrized, tend to fit the training data exactly. Despite this "overfitting", they perform well on test data, a phenomenon not yet fully understood. The first point of our paper is that strong performance of overfitted classifiers is not a unique feature of deep learning. Using six real-world and two synthetic datasets, we establish experimentally that kernel machines trained to have zero classification or near zero regression error perform very well on test data, even when the labels are corrupted with a high level of noise. We proceed to give a lower bound on the norm of zero loss solutions for smooth kernels, showing that they increase nearly exponentially with data size. We point out that this is difficult to reconcile with the existing generalization bounds. Moreover, none of the bounds produce non-trivial results for interpolating solutions. Second, we show experimentally that (non-smooth) Laplacian kernels easily fit random labels, a finding that parallels results for ReLU neural networks. In contrast, fitting noisy data requires many more epochs for smooth Gaussian kernels. Similar performance of overfitted Laplacian and Gaussian classifiers on test, suggests that generalization is tied to the properties of the kernel function rather than the optimization process. Certain key phenomena of deep learning are manifested similarly in kernel methods in the modern "overfitted" regime. The combination of the experimental and theoretical results presented in this paper indicates a need for new theoretical ideas for understanding properties of classical kernel methods. We argue that progress on understanding deep learning will be difficult until more tractable "shallow" kernel methods are better understood.