 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXiaoyu Guo
JailBreakV-28K: A Benchmark for Assessing the Robustness of MultiModal Large Language Models against Jailbreak Attacks
Apr 03, 2024
With the rapid advancements in Multimodal Large Language Models (MLLMs), securing these models against malicious inputs while aligning them with human values has emerged as a critical challenge. In this paper, we investigate an important and unexplored question of whether techniques that successfully jailbreak Large Language Models (LLMs) can be equally effective in jailbreaking MLLMs. To explore this issue, we introduce JailBreakV-28K, a pioneering benchmark designed to assess the transferability of LLM jailbreak techniques to MLLMs, thereby evaluating the robustness of MLLMs against diverse jailbreak attacks. Utilizing a dataset of 2, 000 malicious queries that is also proposed in this paper, we generate 20, 000 text-based jailbreak prompts using advanced jailbreak attacks on LLMs, alongside 8, 000 image-based jailbreak inputs from recent MLLMs jailbreak attacks, our comprehensive dataset includes 28, 000 test cases across a spectrum of adversarial scenarios. Our evaluation of 10 open-source MLLMs reveals a notably high Attack Success Rate (ASR) for attacks transferred from LLMs, highlighting a critical vulnerability in MLLMs that stems from their text-processing capabilities. Our findings underscore the urgent need for future research to address alignment vulnerabilities in MLLMs from both textual and visual inputs.
Deep Learning Applications Based on WISE Infrared Data: Classification of Stars, Galaxies and Quasars
May 17, 2023

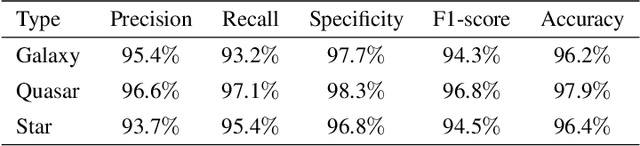
The Wide-field Infrared Survey Explorer (WISE) has detected hundreds of millions of sources over the entire sky. However, classifying them reliably is a great challenge due to degeneracies in WISE multicolor space and low detection levels in its two longest-wavelength bandpasses. In this paper, the deep learning classification network, IICnet (Infrared Image Classification network), is designed to classify sources from WISE images to achieve a more accurate classification goal. IICnet shows good ability on the feature extraction of the WISE sources. Experiments demonstrates that the classification results of IICnet are superior to some other methods; it has obtained 96.2% accuracy for galaxies, 97.9% accuracy for quasars, and 96.4% accuracy for stars, and the Area Under Curve (AUC) of the IICnet classifier can reach more than 99%. In addition, the superiority of IICnet in processing infrared images has been demonstrated in the comparisons with VGG16, GoogleNet, ResNet34, MobileNet, EfficientNetV2, and RepVGG-fewer parameters and faster inference. The above proves that IICnet is an effective method to classify infrared sources.
Prompt What You Need: Enhancing Segmentation in Rainy Scenes with Anchor-based Prompting
May 12, 2023
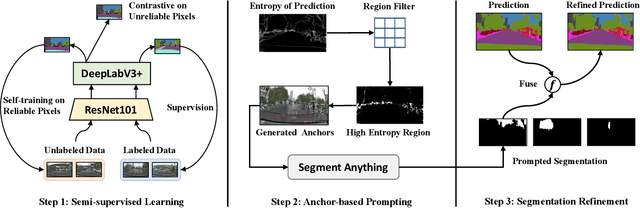


Semantic segmentation in rainy scenes is a challenging task due to the complex environment, class distribution imbalance, and limited annotated data. To address these challenges, we propose a novel framework that utilizes semi-supervised learning and pre-trained segmentation foundation model to achieve superior performance. Specifically, our framework leverages the semi-supervised model as the basis for generating raw semantic segmentation results, while also serving as a guiding force to prompt pre-trained foundation model to compensate for knowledge gaps with entropy-based anchors. In addition, to minimize the impact of irrelevant segmentation masks generated by the pre-trained foundation model, we also propose a mask filtering and fusion mechanism that optimizes raw semantic segmentation results based on the principle of minimum risk. The proposed framework achieves superior segmentation performance on the Rainy WCity dataset and is awarded the first prize in the sub-track of STRAIN in ICME 2023 Grand Challenges.
Cluster-based Deep Ensemble Learning for Emotion Classification in Internet Memes
Feb 16, 2023
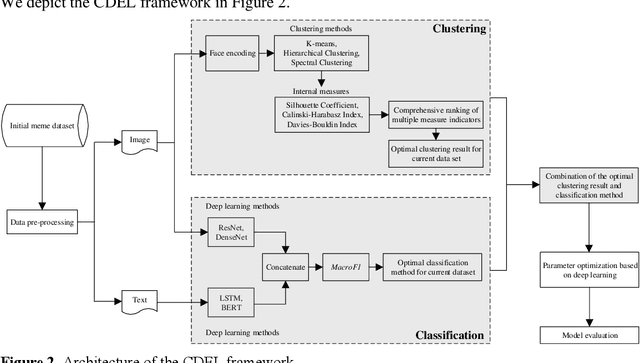

Memes have gained popularity as a means to share visual ideas through the Internet and social media by mixing text, images and videos, often for humorous purposes. Research enabling automated analysis of memes has gained attention in recent years, including among others the task of classifying the emotion expressed in memes. In this paper, we propose a novel model, cluster-based deep ensemble learning (CDEL), for emotion classification in memes. CDEL is a hybrid model that leverages the benefits of a deep learning model in combination with a clustering algorithm, which enhances the model with additional information after clustering memes with similar facial features. We evaluate the performance of CDEL on a benchmark dataset for emotion classification, proving its effectiveness by outperforming a wide range of baseline models and achieving state-of-the-art performance. Further evaluation through ablated models demonstrates the effectiveness of the different components of CDEL.
NUAA-QMUL-AIIT at Memotion 3: Multi-modal Fusion with Squeeze-and-Excitation for Internet Meme Emotion Analysis
Feb 16, 2023
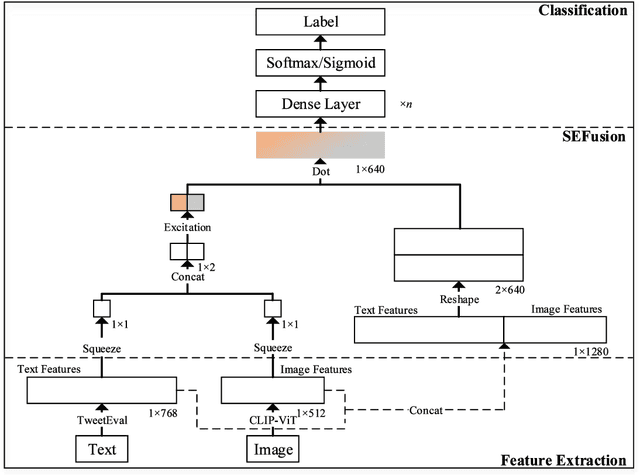
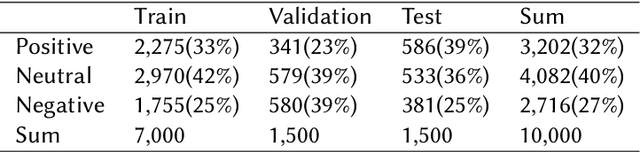
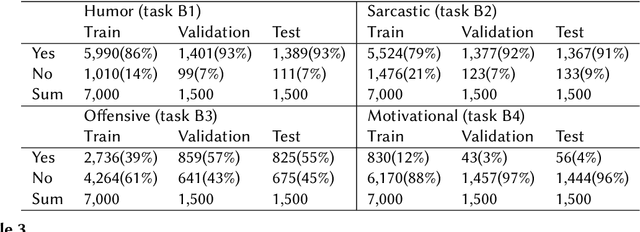
This paper describes the participation of our NUAA-QMUL-AIIT team in the Memotion 3 shared task on meme emotion analysis. We propose a novel multi-modal fusion method, Squeeze-and-Excitation Fusion (SEFusion), and embed it into our system for emotion classification in memes. SEFusion is a simple fusion method that employs fully connected layers, reshaping, and matrix multiplication. SEFusion learns a weight for each modality and then applies it to its own modality feature. We evaluate the performance of our system on the three Memotion 3 sub-tasks. Among all participating systems in this Memotion 3 shared task, our system ranked first on task A, fifth on task B, and second on task C. Our proposed SEFusion provides the flexibility to fuse any features from different modalities. The source code for our method is published on https://github.com/xxxxxxxxy/memotion3-SEFusion.
NUAA-QMUL at SemEval-2020 Task 8: Utilizing BERT and DenseNet for Internet Meme Emotion Analysis
Nov 09, 2020
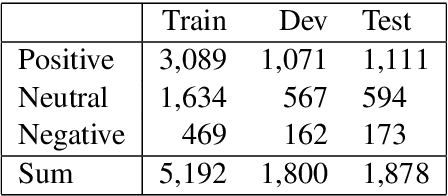


This paper describes our contribution to SemEval 2020 Task 8: Memotion Analysis. Our system learns multi-modal embeddings from text and images in order to classify Internet memes by sentiment. Our model learns text embeddings using BERT and extracts features from images with DenseNet, subsequently combining both features through concatenation. We also compare our results with those produced by DenseNet, ResNet, BERT, and BERT-ResNet. Our results show that image classification models have the potential to help classifying memes, with DenseNet outperforming ResNet. Adding text features is however not always helpful for Memotion Analysis.
Compose Like Humans: Jointly Improving the Coherence and Novelty for Modern Chinese Poetry Generation
May 04, 2020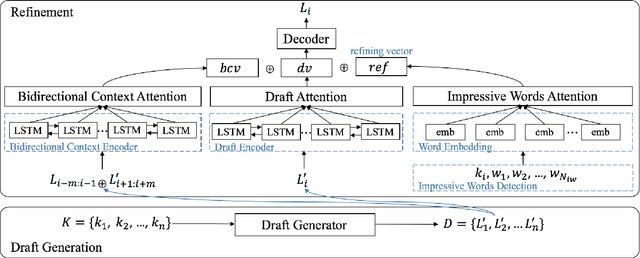
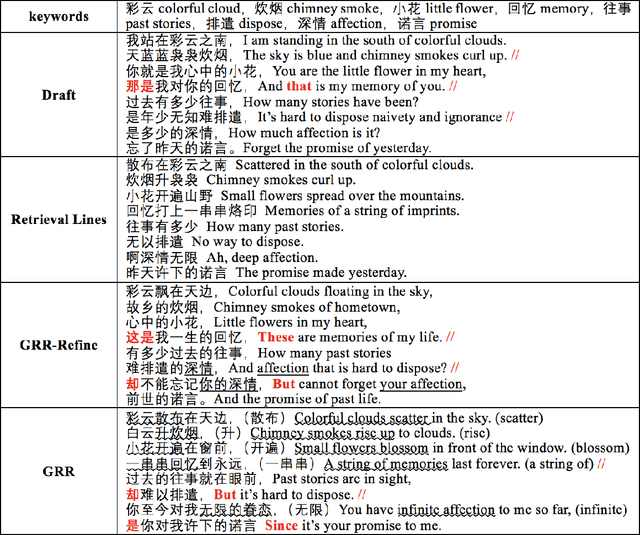

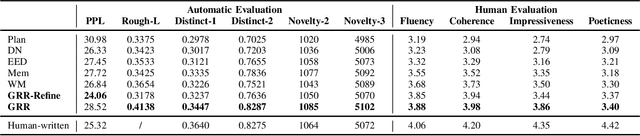
Chinese poetry is an important part of worldwide culture, and classical and modern sub-branches are quite different. The former is a unique genre and has strict constraints, while the latter is very flexible in length, optional to have rhymes, and similar to modern poetry in other languages. Thus, it requires more to control the coherence and improve the novelty. In this paper, we propose a generate-retrieve-then-refine paradigm to jointly improve the coherence and novelty. In the first stage, a draft is generated given keywords (i.e., topics) only. The second stage produces a "refining vector" from retrieval lines. At last, we take into consideration both the draft and the "refining vector" to generate a new poem. The draft provides future sentence-level information for a line to be generated. Meanwhile, the "refining vector" points out the direction of refinement based on impressive words detection mechanism which can learn good patterns from references and then create new ones via insertion operation. Experimental results on a collected large-scale modern Chinese poetry dataset show that our proposed approach can not only generate more coherent poems, but also improve the diversity and novelty.
From Knowledge Map to Mind Map: Artificial Imagination
Mar 06, 2019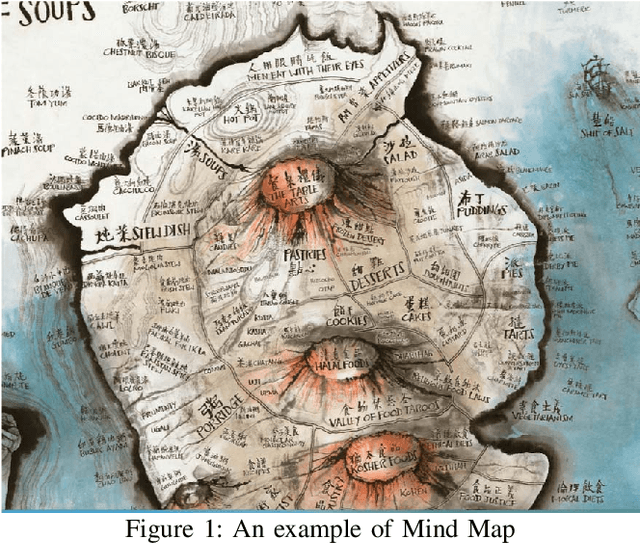

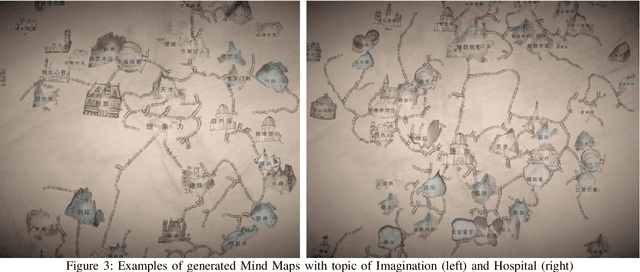
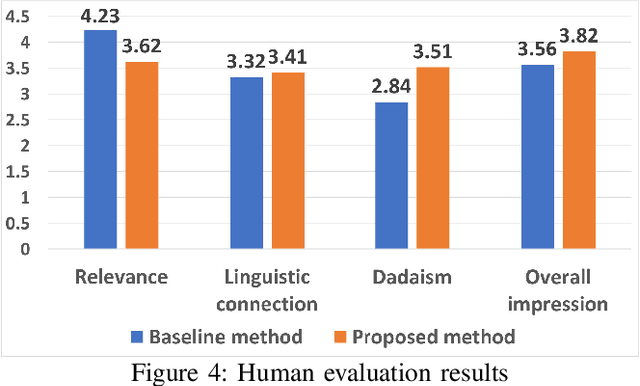
Imagination is one of the most important factors which makes an artistic painting unique and impressive. With the rapid development of Artificial Intelligence, more and more researchers try to create painting with AI technology automatically. However, lacking of imagination is still a main problem for AI painting. In this paper, we propose a novel approach to inject rich imagination into a special painting art Mind Map creation. We firstly consider lexical and phonological similarities of seed word, then learn and inherit original painting style of the author, and finally apply Dadaism and impossibility of improvisation principles into painting process. We also design several metrics for imagination evaluation. Experimental results show that our proposed method can increase imagination of painting and also improve its overall quality.