 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSrijan Kumar
Mysterious Projections: Multimodal LLMs Gain Domain-Specific Visual Capabilities Without Richer Cross-Modal Projections
Feb 26, 2024
Multimodal large language models (MLLMs) like LLaVA and GPT-4(V) enable general-purpose conversations about images with the language modality. As off-the-shelf MLLMs may have limited capabilities on images from domains like dermatology and agriculture, they must be fine-tuned to unlock domain-specific applications. The prevalent architecture of current open-source MLLMs comprises two major modules: an image-language (cross-modal) projection network and a large language model. It is desirable to understand the roles of these two modules in modeling domain-specific visual attributes to inform the design of future models and streamline the interpretability efforts on the current models. To this end, via experiments on 4 datasets and under 2 fine-tuning settings, we find that as the MLLM is fine-tuned, it indeed gains domain-specific visual capabilities, but the updates do not lead to the projection extracting relevant domain-specific visual attributes. Our results indicate that the domain-specific visual attributes are modeled by the LLM, even when only the projection is fine-tuned. Through this study, we offer a potential reinterpretation of the role of cross-modal projections in MLLM architectures. Projection webpage: https://claws-lab.github.io/projection-in-MLLMs/
Towards Fair Graph Anomaly Detection: Problem, New Datasets, and Evaluation
Feb 25, 2024The Fair Graph Anomaly Detection (FairGAD) problem aims to accurately detect anomalous nodes in an input graph while ensuring fairness and avoiding biased predictions against individuals from sensitive subgroups such as gender or political leanings. Fairness in graphs is particularly crucial in anomaly detection areas such as misinformation detection in search/ranking systems, where decision outcomes can significantly affect individuals. However, the current literature does not comprehensively discuss this problem, nor does it provide realistic datasets that encompass actual graph structures, anomaly labels, and sensitive attributes for research in FairGAD. To bridge this gap, we introduce a formal definition of the FairGAD problem and present two novel graph datasets constructed from the globally prominent social media platforms Reddit and Twitter. These datasets comprise 1.2 million and 400,000 edges associated with 9,000 and 47,000 nodes, respectively, and leverage political leanings as sensitive attributes and misinformation spreaders as anomaly labels. We demonstrate that our FairGAD datasets significantly differ from the synthetic datasets used currently by the research community. These new datasets offer significant values for FairGAD by providing realistic data that captures the intricacies of social networks. Using our datasets, we investigate the performance-fairness trade-off in eleven existing GAD and non-graph AD methods on five state-of-the-art fairness methods, which sheds light on their effectiveness and limitations in addressing the FairGAD problem.
MM-Soc: Benchmarking Multimodal Large Language Models in Social Media Platforms
Feb 21, 2024Social media platforms are hubs for multimodal information exchange, encompassing text, images, and videos, making it challenging for machines to comprehend the information or emotions associated with interactions in online spaces. Multimodal Large Language Models (MLLMs) have emerged as a promising solution to address these challenges, yet struggle with accurately interpreting human emotions and complex contents like misinformation. This paper introduces MM-Soc, a comprehensive benchmark designed to evaluate MLLMs' understanding of multimodal social media content. MM-Soc compiles prominent multimodal datasets and incorporates a novel large-scale YouTube tagging dataset, targeting a range of tasks from misinformation detection, hate speech detection, and social context generation. Through our exhaustive evaluation on ten size-variants of four open-source MLLMs, we have identified significant performance disparities, highlighting the need for advancements in models' social understanding capabilities. Our analysis reveals that, in a zero-shot setting, various types of MLLMs generally exhibit difficulties in handling social media tasks. However, MLLMs demonstrate performance improvements post fine-tuning, suggesting potential pathways for improvement.
FINEST: Stabilizing Recommendations by Rank-Preserving Fine-Tuning
Feb 05, 2024Modern recommender systems may output considerably different recommendations due to small perturbations in the training data. Changes in the data from a single user will alter the recommendations as well as the recommendations of other users. In applications like healthcare, housing, and finance, this sensitivity can have adverse effects on user experience. We propose a method to stabilize a given recommender system against such perturbations. This is a challenging task due to (1) the lack of a ``reference'' rank list that can be used to anchor the outputs; and (2) the computational challenges in ensuring the stability of rank lists with respect to all possible perturbations of training data. Our method, FINEST, overcomes these challenges by obtaining reference rank lists from a given recommendation model and then fine-tuning the model under simulated perturbation scenarios with rank-preserving regularization on sampled items. Our experiments on real-world datasets demonstrate that FINEST can ensure that recommender models output stable recommendations under a wide range of different perturbations without compromising next-item prediction accuracy.
Better to Ask in English: Cross-Lingual Evaluation of Large Language Models for Healthcare Queries
Oct 23, 2023Large language models (LLMs) are transforming the ways the general public accesses and consumes information. Their influence is particularly pronounced in pivotal sectors like healthcare, where lay individuals are increasingly appropriating LLMs as conversational agents for everyday queries. While LLMs demonstrate impressive language understanding and generation proficiencies, concerns regarding their safety remain paramount in these high-stake domains. Moreover, the development of LLMs is disproportionately focused on English. It remains unclear how these LLMs perform in the context of non-English languages, a gap that is critical for ensuring equity in the real-world use of these systems.This paper provides a framework to investigate the effectiveness of LLMs as multi-lingual dialogue systems for healthcare queries. Our empirically-derived framework XlingEval focuses on three fundamental criteria for evaluating LLM responses to naturalistic human-authored health-related questions: correctness, consistency, and verifiability. Through extensive experiments on four major global languages, including English, Spanish, Chinese, and Hindi, spanning three expert-annotated large health Q&A datasets, and through an amalgamation of algorithmic and human-evaluation strategies, we found a pronounced disparity in LLM responses across these languages, indicating a need for enhanced cross-lingual capabilities. We further propose XlingHealth, a cross-lingual benchmark for examining the multilingual capabilities of LLMs in the healthcare context. Our findings underscore the pressing need to bolster the cross-lingual capacities of these models, and to provide an equitable information ecosystem accessible to all.
Overview of Memotion 3: Sentiment and Emotion Analysis of Codemixed Hinglish Memes
Sep 12, 2023
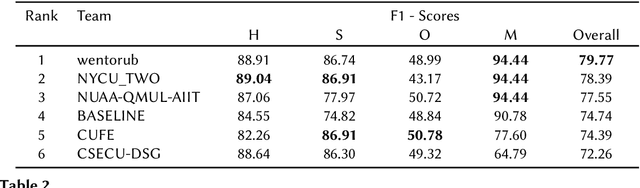

Analyzing memes on the internet has emerged as a crucial endeavor due to the impact this multi-modal form of content wields in shaping online discourse. Memes have become a powerful tool for expressing emotions and sentiments, possibly even spreading hate and misinformation, through humor and sarcasm. In this paper, we present the overview of the Memotion 3 shared task, as part of the DeFactify 2 workshop at AAAI-23. The task released an annotated dataset of Hindi-English code-mixed memes based on their Sentiment (Task A), Emotion (Task B), and Emotion intensity (Task C). Each of these is defined as an individual task and the participants are ranked separately for each task. Over 50 teams registered for the shared task and 5 made final submissions to the test set of the Memotion 3 dataset. CLIP, BERT modifications, ViT etc. were the most popular models among the participants along with approaches such as Student-Teacher model, Fusion, and Ensembling. The best final F1 score for Task A is 34.41, Task B is 79.77 and Task C is 59.82.
Findings of Factify 2: Multimodal Fake News Detection
Jul 19, 2023
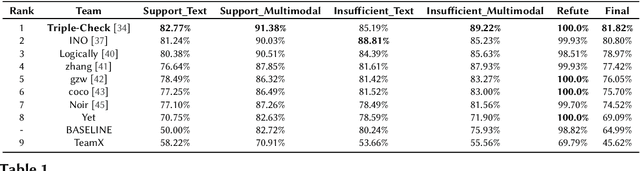
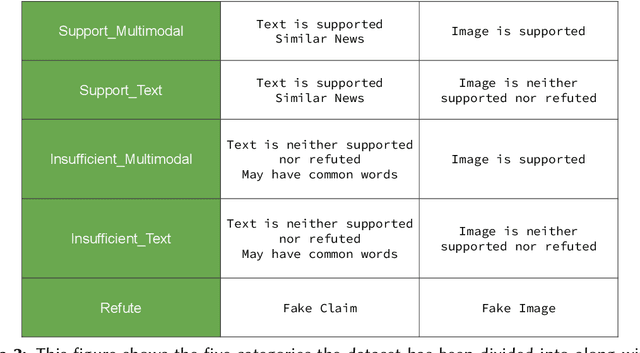
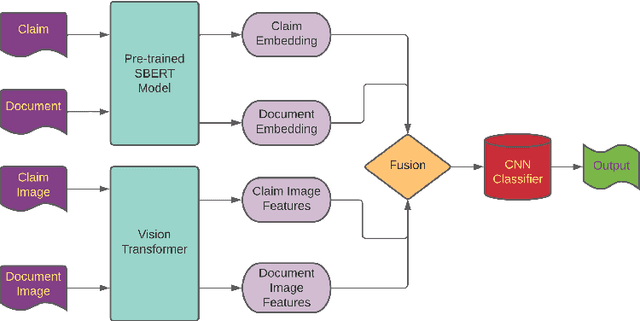
With social media usage growing exponentially in the past few years, fake news has also become extremely prevalent. The detrimental impact of fake news emphasizes the need for research focused on automating the detection of false information and verifying its accuracy. In this work, we present the outcome of the Factify 2 shared task, which provides a multi-modal fact verification and satire news dataset, as part of the DeFactify 2 workshop at AAAI'23. The data calls for a comparison based approach to the task by pairing social media claims with supporting documents, with both text and image, divided into 5 classes based on multi-modal relations. In the second iteration of this task we had over 60 participants and 9 final test-set submissions. The best performances came from the use of DeBERTa for text and Swinv2 and CLIP for image. The highest F1 score averaged for all five classes was 81.82%.
Adversarial Robustness of Prompt-based Few-Shot Learning for Natural Language Understanding
Jun 21, 2023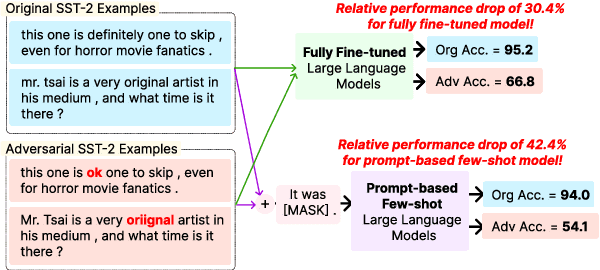

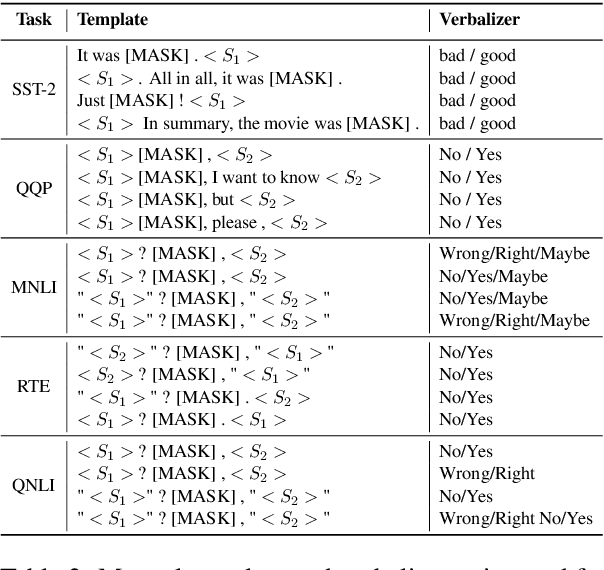
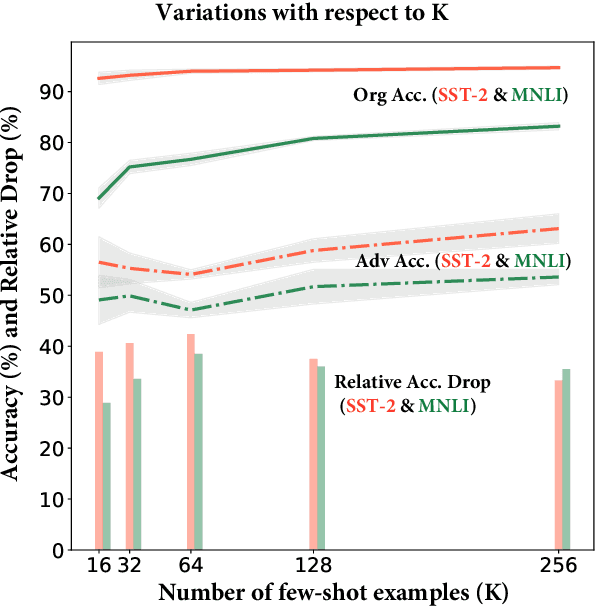
State-of-the-art few-shot learning (FSL) methods leverage prompt-based fine-tuning to obtain remarkable results for natural language understanding (NLU) tasks. While much of the prior FSL methods focus on improving downstream task performance, there is a limited understanding of the adversarial robustness of such methods. In this work, we conduct an extensive study of several state-of-the-art FSL methods to assess their robustness to adversarial perturbations. To better understand the impact of various factors towards robustness (or the lack of it), we evaluate prompt-based FSL methods against fully fine-tuned models for aspects such as the use of unlabeled data, multiple prompts, number of few-shot examples, model size and type. Our results on six GLUE tasks indicate that compared to fully fine-tuned models, vanilla FSL methods lead to a notable relative drop in task performance (i.e., are less robust) in the face of adversarial perturbations. However, using (i) unlabeled data for prompt-based FSL and (ii) multiple prompts flip the trend. We further demonstrate that increasing the number of few-shot examples and model size lead to increased adversarial robustness of vanilla FSL methods. Broadly, our work sheds light on the adversarial robustness evaluation of prompt-based FSL methods for NLU tasks.
Cross-Modal Attribute Insertions for Assessing the Robustness of Vision-and-Language Learning
Jun 19, 2023
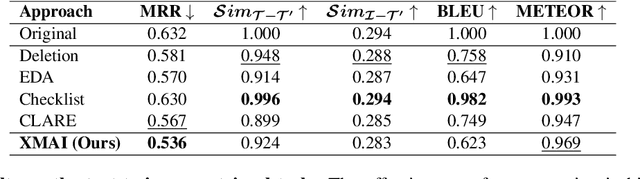
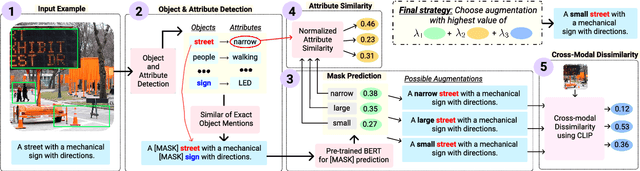
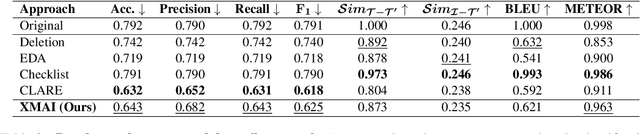
The robustness of multimodal deep learning models to realistic changes in the input text is critical for their applicability to important tasks such as text-to-image retrieval and cross-modal entailment. To measure robustness, several existing approaches edit the text data, but do so without leveraging the cross-modal information present in multimodal data. Information from the visual modality, such as color, size, and shape, provide additional attributes that users can include in their inputs. Thus, we propose cross-modal attribute insertions as a realistic perturbation strategy for vision-and-language data that inserts visual attributes of the objects in the image into the corresponding text (e.g., "girl on a chair" to "little girl on a wooden chair"). Our proposed approach for cross-modal attribute insertions is modular, controllable, and task-agnostic. We find that augmenting input text using cross-modal insertions causes state-of-the-art approaches for text-to-image retrieval and cross-modal entailment to perform poorly, resulting in relative drops of 15% in MRR and 20% in $F_1$ score, respectively. Crowd-sourced annotations demonstrate that cross-modal insertions lead to higher quality augmentations for multimodal data than augmentations using text-only data, and are equivalent in quality to original examples. We release the code to encourage robustness evaluations of deep vision-and-language models: https://github.com/claws-lab/multimodal-robustness-xmai.
Factify 2: A Multimodal Fake News and Satire News Dataset
Apr 08, 2023
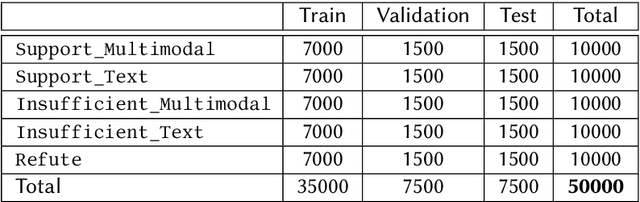
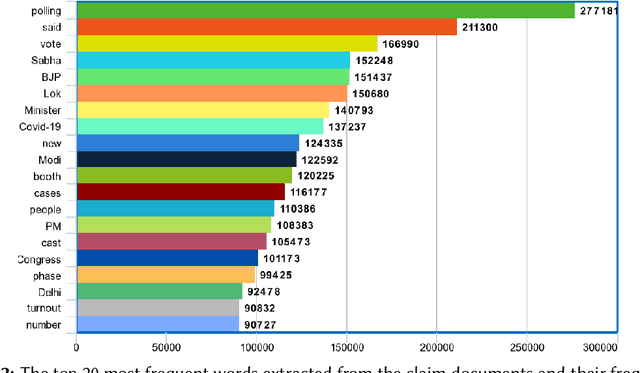
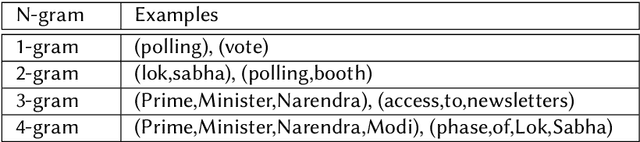
The internet gives the world an open platform to express their views and share their stories. While this is very valuable, it makes fake news one of our society's most pressing problems. Manual fact checking process is time consuming, which makes it challenging to disprove misleading assertions before they cause significant harm. This is he driving interest in automatic fact or claim verification. Some of the existing datasets aim to support development of automating fact-checking techniques, however, most of them are text based. Multi-modal fact verification has received relatively scant attention. In this paper, we provide a multi-modal fact-checking dataset called FACTIFY 2, improving Factify 1 by using new data sources and adding satire articles. Factify 2 has 50,000 new data instances. Similar to FACTIFY 1.0, we have three broad categories - support, no-evidence, and refute, with sub-categories based on the entailment of visual and textual data. We also provide a BERT and Vison Transformer based baseline, which acheives 65% F1 score in the test set. The baseline codes and the dataset will be made available at https://github.com/surya1701/Factify-2.0.