 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSundong Kim
Reasoning Abilities of Large Language Models: In-Depth Analysis on the Abstraction and Reasoning Corpus
Mar 18, 2024

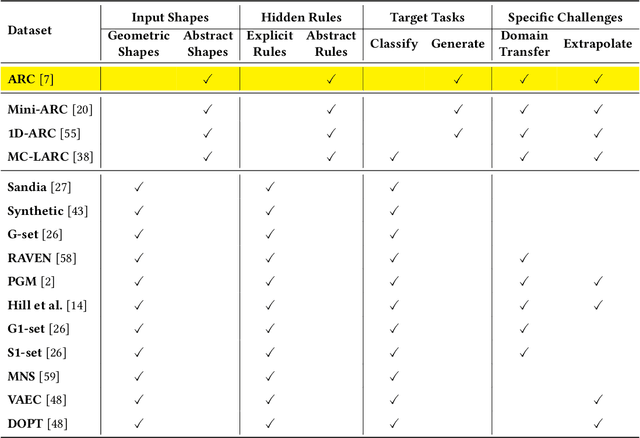
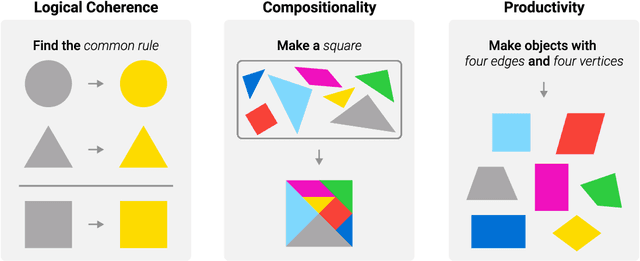
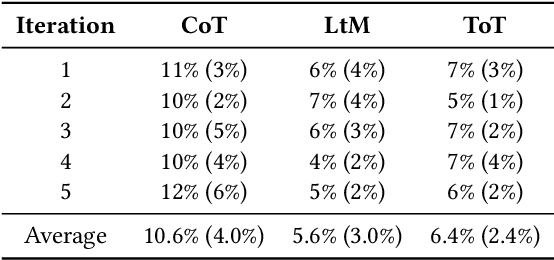
The existing methods for evaluating the inference abilities of Large Language Models (LLMs) have been results-centric, making it difficult to assess the inference process. We introduce a new approach using the Abstract and Reasoning Corpus (ARC) dataset to evaluate the inference and contextual understanding abilities of large language models in a process-centric manner. ARC demands rigorous logical structures for problem-solving, making it a benchmark that facilitates the comparison of model inference abilities with humans. Experimental results confirm that while large language models possess weak inference abilities, they still lag in terms of logical coherence, compositionality, and productivity. Our experiments highlight the reasoning capabilities of LLMs, proposing development paths for achieving human-level reasoning.
Explainable Product Classification for Customs
Nov 18, 2023The task of assigning internationally accepted commodity codes (aka HS codes) to traded goods is a critical function of customs offices. Like court decisions made by judges, this task follows the doctrine of precedent and can be nontrivial even for experienced officers. Together with the Korea Customs Service (KCS), we propose a first-ever explainable decision supporting model that suggests the most likely subheadings (i.e., the first six digits) of the HS code. The model also provides reasoning for its suggestion in the form of a document that is interpretable by customs officers. We evaluated the model using 5,000 cases that recently received a classification request. The results showed that the top-3 suggestions made by our model had an accuracy of 93.9\% when classifying 925 challenging subheadings. A user study with 32 customs experts further confirmed that our algorithmic suggestions accompanied by explainable reasonings, can substantially reduce the time and effort taken by customs officers for classification reviews.
Towards Attack-tolerant Federated Learning via Critical Parameter Analysis
Aug 18, 2023
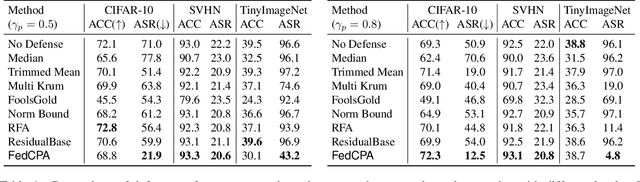
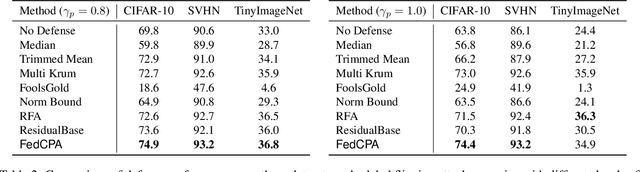
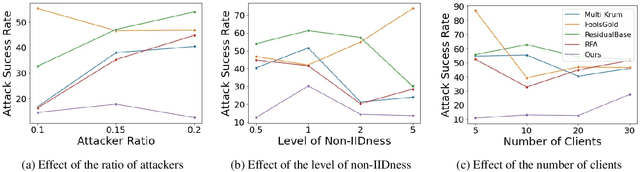
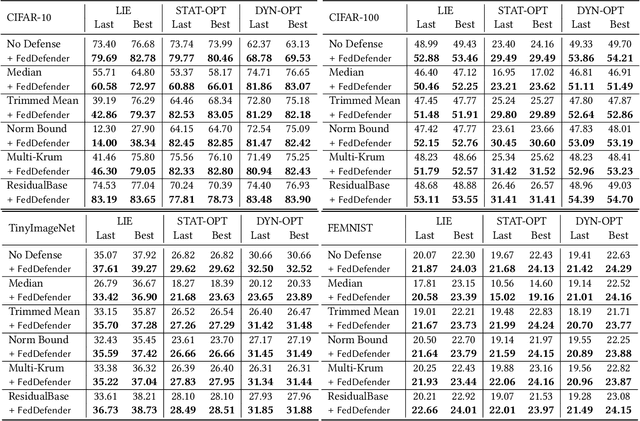
Federated learning is used to train a shared model in a decentralized way without clients sharing private data with each other. Federated learning systems are susceptible to poisoning attacks when malicious clients send false updates to the central server. Existing defense strategies are ineffective under non-IID data settings. This paper proposes a new defense strategy, FedCPA (Federated learning with Critical Parameter Analysis). Our attack-tolerant aggregation method is based on the observation that benign local models have similar sets of top-k and bottom-k critical parameters, whereas poisoned local models do not. Experiments with different attack scenarios on multiple datasets demonstrate that our model outperforms existing defense strategies in defending against poisoning attacks.
FedDefender: Client-Side Attack-Tolerant Federated Learning
Jul 18, 2023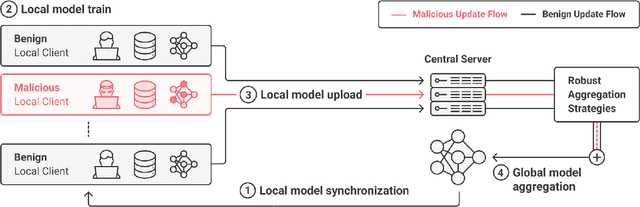
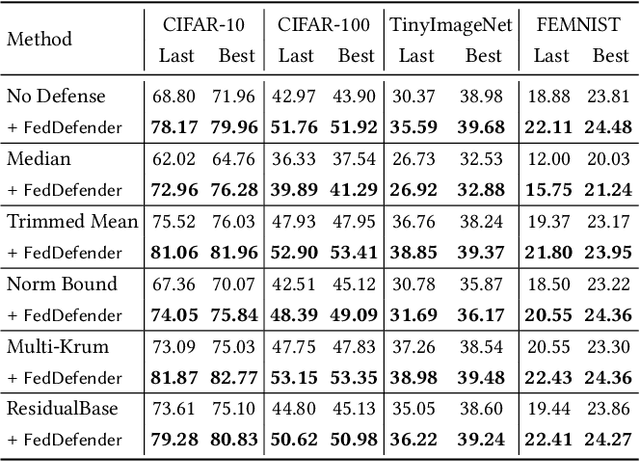
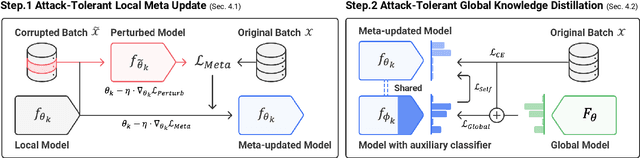
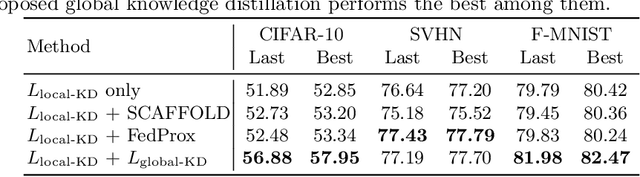
Federated learning enables learning from decentralized data sources without compromising privacy, which makes it a crucial technique. However, it is vulnerable to model poisoning attacks, where malicious clients interfere with the training process. Previous defense mechanisms have focused on the server-side by using careful model aggregation, but this may not be effective when the data is not identically distributed or when attackers can access the information of benign clients. In this paper, we propose a new defense mechanism that focuses on the client-side, called FedDefender, to help benign clients train robust local models and avoid the adverse impact of malicious model updates from attackers, even when a server-side defense cannot identify or remove adversaries. Our method consists of two main components: (1) attack-tolerant local meta update and (2) attack-tolerant global knowledge distillation. These components are used to find noise-resilient model parameters while accurately extracting knowledge from a potentially corrupted global model. Our client-side defense strategy has a flexible structure and can work in conjunction with any existing server-side strategies. Evaluations of real-world scenarios across multiple datasets show that the proposed method enhances the robustness of federated learning against model poisoning attacks.
Unraveling the ARC Puzzle: Mimicking Human Solutions with Object-Centric Decision Transformer
Jun 14, 2023

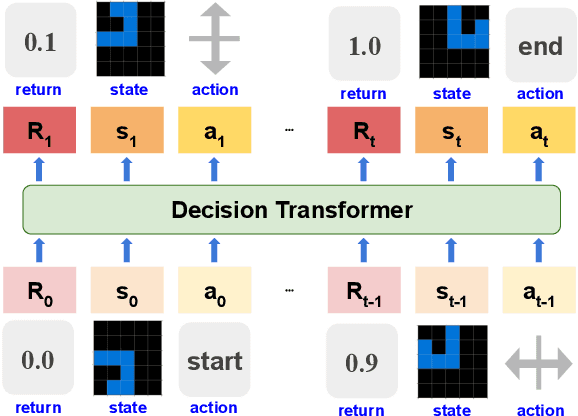
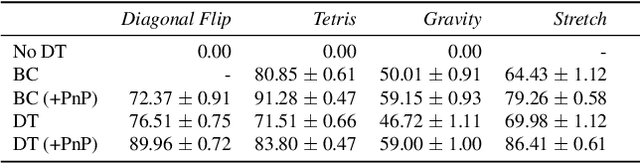
In the pursuit of artificial general intelligence (AGI), we tackle Abstraction and Reasoning Corpus (ARC) tasks using a novel two-pronged approach. We employ the Decision Transformer in an imitation learning paradigm to model human problem-solving, and introduce an object detection algorithm, the Push and Pull clustering method. This dual strategy enhances AI's ARC problem-solving skills and provides insights for AGI progression. Yet, our work reveals the need for advanced data collection tools, robust training datasets, and refined model structures. This study highlights potential improvements for Decision Transformers and propels future AGI research.
DualFair: Fair Representation Learning at Both Group and Individual Levels via Contrastive Self-supervision
Mar 15, 2023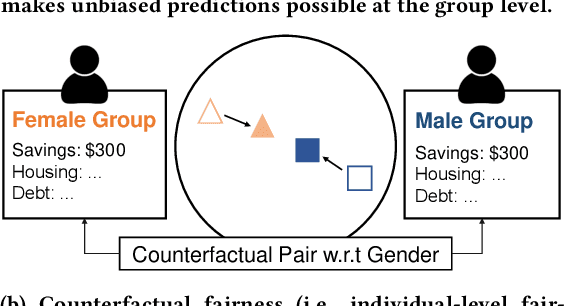
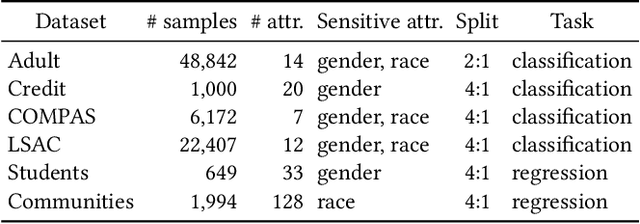
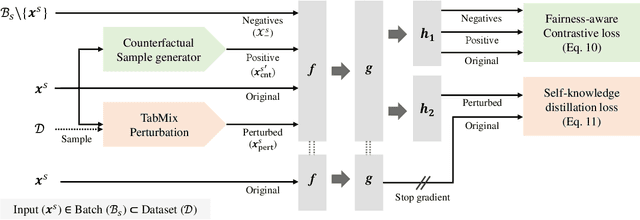
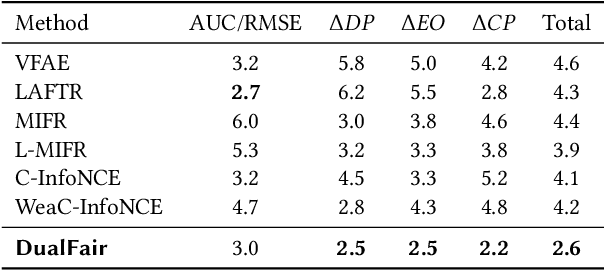
Algorithmic fairness has become an important machine learning problem, especially for mission-critical Web applications. This work presents a self-supervised model, called DualFair, that can debias sensitive attributes like gender and race from learned representations. Unlike existing models that target a single type of fairness, our model jointly optimizes for two fairness criteria - group fairness and counterfactual fairness - and hence makes fairer predictions at both the group and individual levels. Our model uses contrastive loss to generate embeddings that are indistinguishable for each protected group, while forcing the embeddings of counterfactual pairs to be similar. It then uses a self-knowledge distillation method to maintain the quality of representation for the downstream tasks. Extensive analysis over multiple datasets confirms the model's validity and further shows the synergy of jointly addressing two fairness criteria, suggesting the model's potential value in fair intelligent Web applications.
Customs Import Declaration Datasets
Aug 04, 2022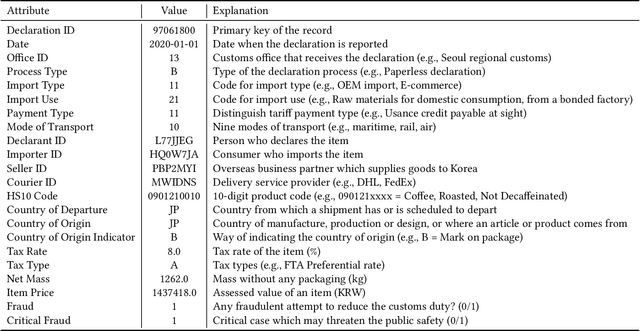

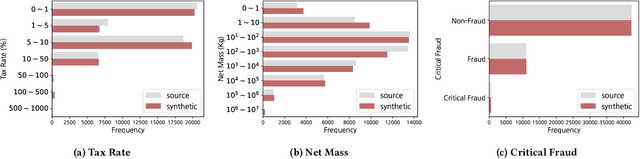
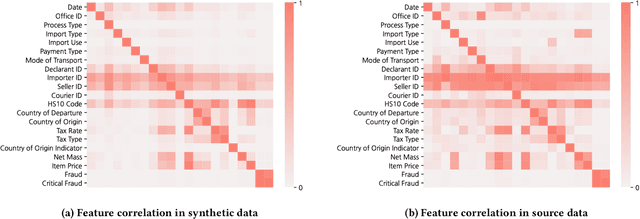
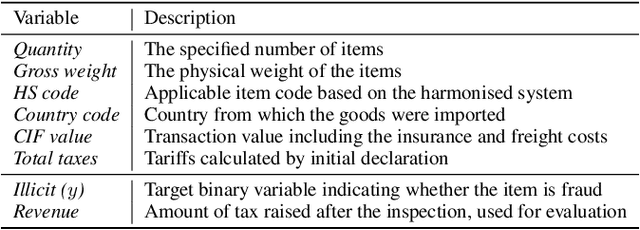
Given the huge volume of cross-border flows, effective and efficient control of trades becomes more crucial in protecting people and society from illicit trades while facilitating legitimate trades. However, limited accessibility of the transaction-level trade datasets hinders the progress of open research, and lots of customs administrations have not benefited from the recent progress in data-based risk management. In this paper, we introduce an import declarations dataset to facilitate the collaboration between the domain experts in customs administrations and data science researchers. The dataset contains 54,000 artificially generated trades with 22 key attributes, and it is synthesized with CTGAN while maintaining correlated features. Synthetic data has several advantages. First, releasing the dataset is free from restrictions that do not allow disclosing the original import data. Second, the fabrication step minimizes the possible identity risk which may exist in trade statistics. Lastly, the published data follow a similar distribution to the source data so that it can be used in various downstream tasks. With the provision of data and its generation process, we open baseline codes for fraud detection tasks, as we empirically show that more advanced algorithms can better detect frauds.
FedX: Unsupervised Federated Learning with Cross Knowledge Distillation
Jul 19, 2022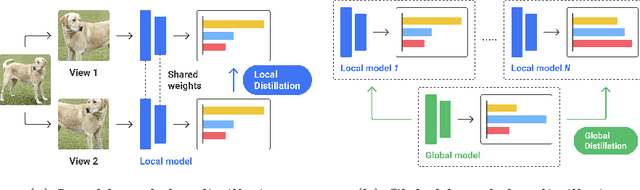
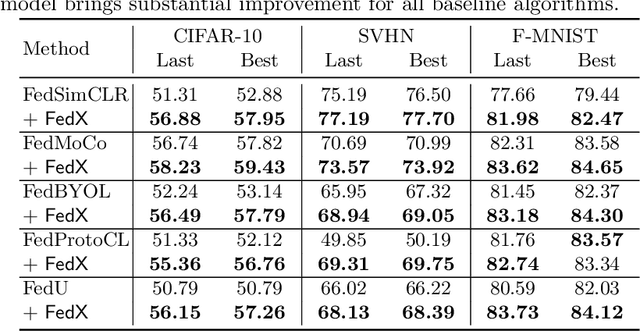
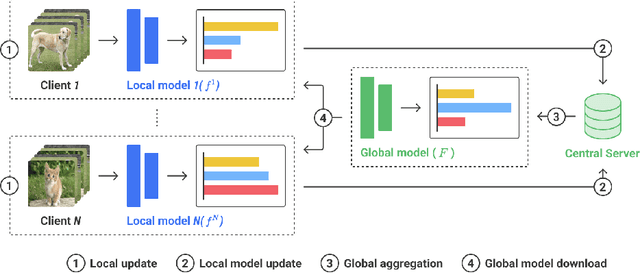
This paper presents FedX, an unsupervised federated learning framework. Our model learns unbiased representation from decentralized and heterogeneous local data. It employs a two-sided knowledge distillation with contrastive learning as a core component, allowing the federated system to function without requiring clients to share any data features. Furthermore, its adaptable architecture can be used as an add-on module for existing unsupervised algorithms in federated settings. Experiments show that our model improves performance significantly (1.58--5.52pp) on five unsupervised algorithms.
Knowledge Sharing via Domain Adaptation in Customs Fraud Detection
Jan 18, 2022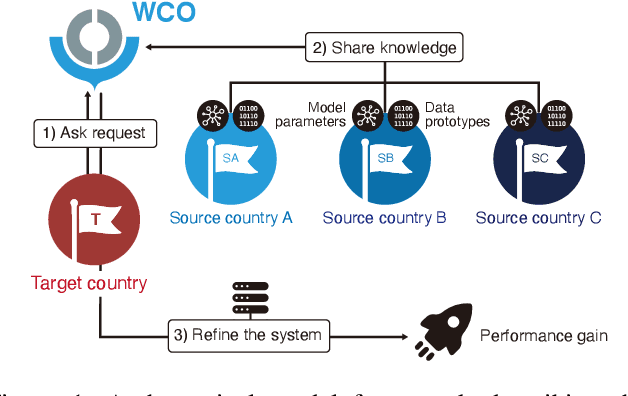

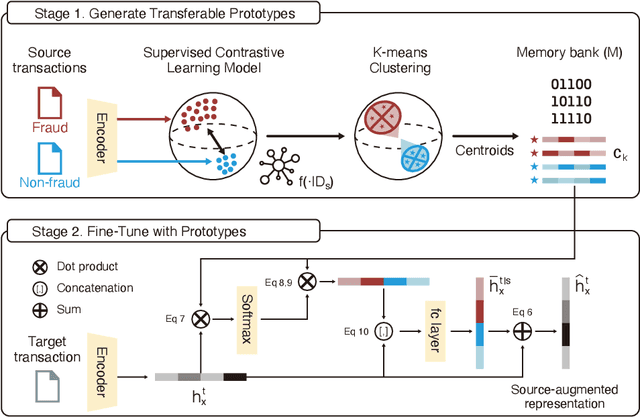
Knowledge of the changing traffic is critical in risk management. Customs offices worldwide have traditionally relied on local resources to accumulate knowledge and detect tax fraud. This naturally poses countries with weak infrastructure to become tax havens of potentially illicit trades. The current paper proposes DAS, a memory bank platform to facilitate knowledge sharing across multi-national customs administrations to support each other. We propose a domain adaptation method to share transferable knowledge of frauds as prototypes while safeguarding the local trade information. Data encompassing over 8 million import declarations have been used to test the feasibility of this new system, which shows that participating countries may benefit up to 2-11 times in fraud detection with the help of shared knowledge. We discuss implications for substantial tax revenue potential and strengthened policy against illicit trades.
Classification of Goods Using Text Descriptions With Sentences Retrieval
Nov 02, 2021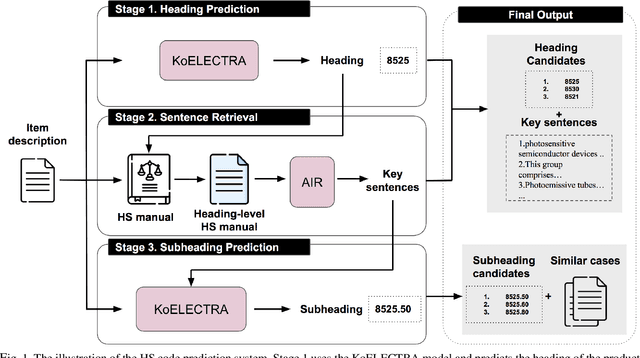
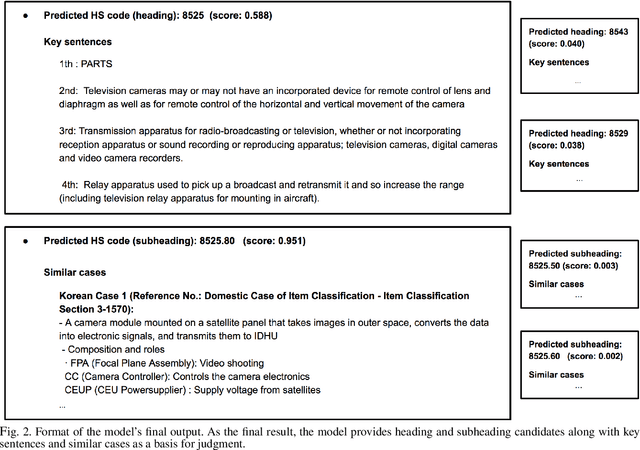
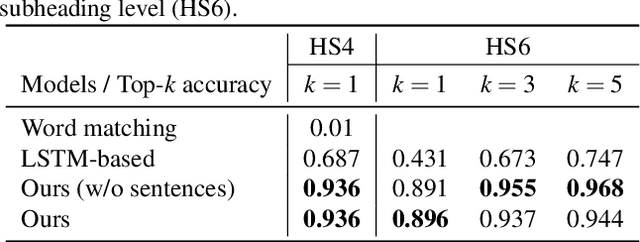

The task of assigning and validating internationally accepted commodity code (HS code) to traded goods is one of the critical functions at the customs office. This decision is crucial to importers and exporters, as it determines the tariff rate. However, similar to court decisions made by judges, the task can be non-trivial even for experienced customs officers. The current paper proposes a deep learning model to assist this seemingly challenging HS code classification. Together with Korea Customs Service, we built a decision model based on KoELECTRA that suggests the most likely heading and subheadings (i.e., the first four and six digits) of the HS code. Evaluation on 129,084 past cases shows that the top-3 suggestions made by our model have an accuracy of 95.5% in classifying 265 subheadings. This promising result implies algorithms may reduce the time and effort taken by customs officers substantially by assisting the HS code classification task.