 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTaian Guo
Unified and Dynamic Graph for Temporal Character Grouping in Long Videos
Aug 29, 2023
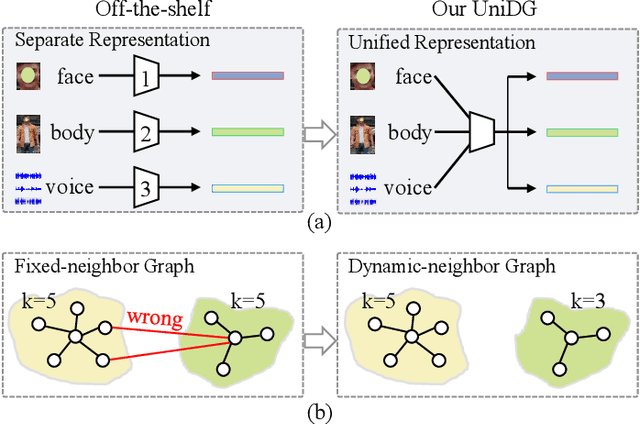
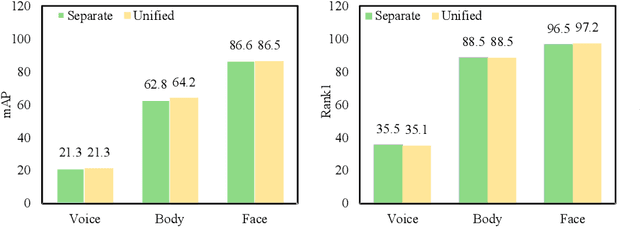
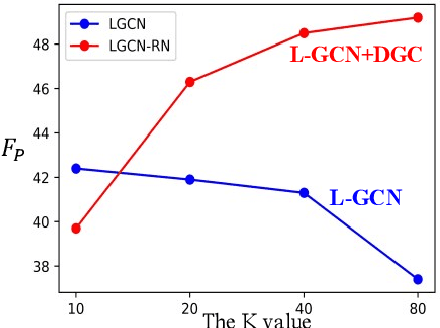
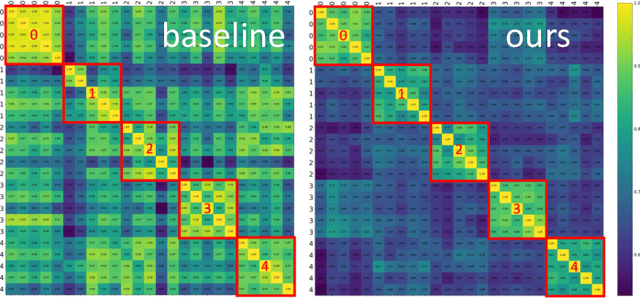
Video temporal character grouping locates appearing moments of major characters within a video according to their identities. To this end, recent works have evolved from unsupervised clustering to graph-based supervised clustering. However, graph methods are built upon the premise of fixed affinity graphs, bringing many inexact connections. Besides, they extract multi-modal features with kinds of models, which are unfriendly to deployment. In this paper, we present a unified and dynamic graph (UniDG) framework for temporal character grouping. This is accomplished firstly by a unified representation network that learns representations of multiple modalities within the same space and still preserves the modality's uniqueness simultaneously. Secondly, we present a dynamic graph clustering where the neighbors of different quantities are dynamically constructed for each node via a cyclic matching strategy, leading to a more reliable affinity graph. Thirdly, a progressive association method is introduced to exploit spatial and temporal contexts among different modalities, allowing multi-modal clustering results to be well fused. As current datasets only provide pre-extracted features, we evaluate our UniDG method on a collected dataset named MTCG, which contains each character's appearing clips of face and body and speaking voice tracks. We also evaluate our key components on existing clustering and retrieval datasets to verify the generalization ability. Experimental results manifest that our method can achieve promising results and outperform several state-of-the-art approaches.
D3G: Exploring Gaussian Prior for Temporal Sentence Grounding with Glance Annotation
Aug 08, 2023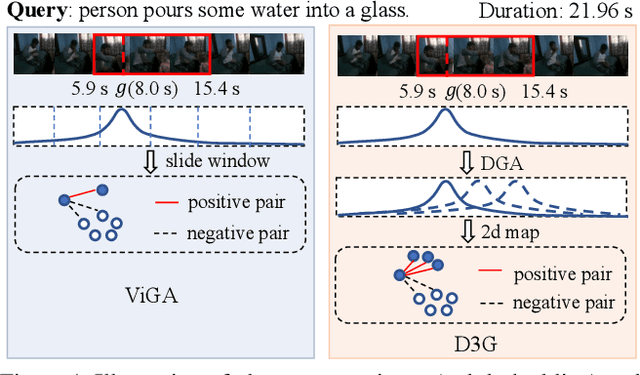
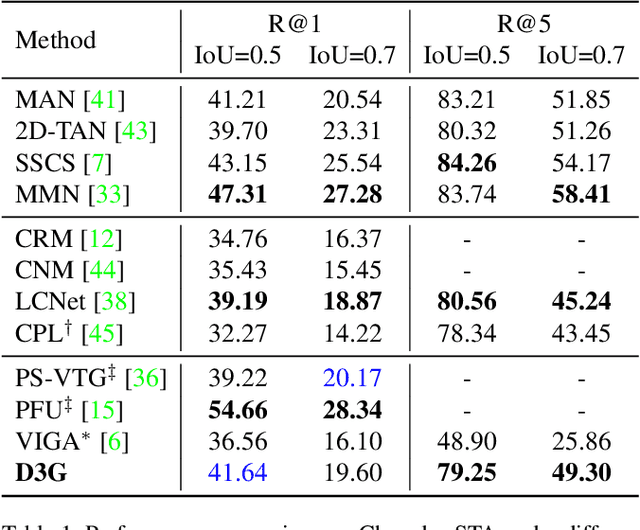

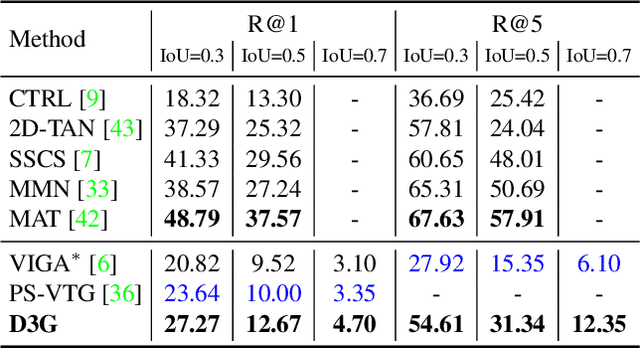
Temporal sentence grounding (TSG) aims to locate a specific moment from an untrimmed video with a given natural language query. Recently, weakly supervised methods still have a large performance gap compared to fully supervised ones, while the latter requires laborious timestamp annotations. In this study, we aim to reduce the annotation cost yet keep competitive performance for TSG task compared to fully supervised ones. To achieve this goal, we investigate a recently proposed glance-supervised temporal sentence grounding task, which requires only single frame annotation (referred to as glance annotation) for each query. Under this setup, we propose a Dynamic Gaussian prior based Grounding framework with Glance annotation (D3G), which consists of a Semantic Alignment Group Contrastive Learning module (SA-GCL) and a Dynamic Gaussian prior Adjustment module (DGA). Specifically, SA-GCL samples reliable positive moments from a 2D temporal map via jointly leveraging Gaussian prior and semantic consistency, which contributes to aligning the positive sentence-moment pairs in the joint embedding space. Moreover, to alleviate the annotation bias resulting from glance annotation and model complex queries consisting of multiple events, we propose the DGA module, which adjusts the distribution dynamically to approximate the ground truth of target moments. Extensive experiments on three challenging benchmarks verify the effectiveness of the proposed D3G. It outperforms the state-of-the-art weakly supervised methods by a large margin and narrows the performance gap compared to fully supervised methods. Code is available at https://github.com/solicucu/D3G.
VLMAE: Vision-Language Masked Autoencoder
Aug 19, 2022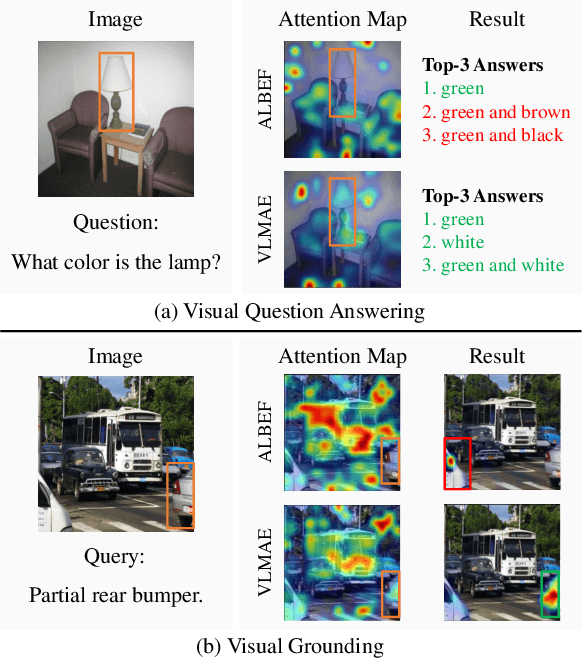
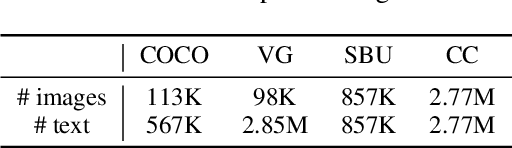
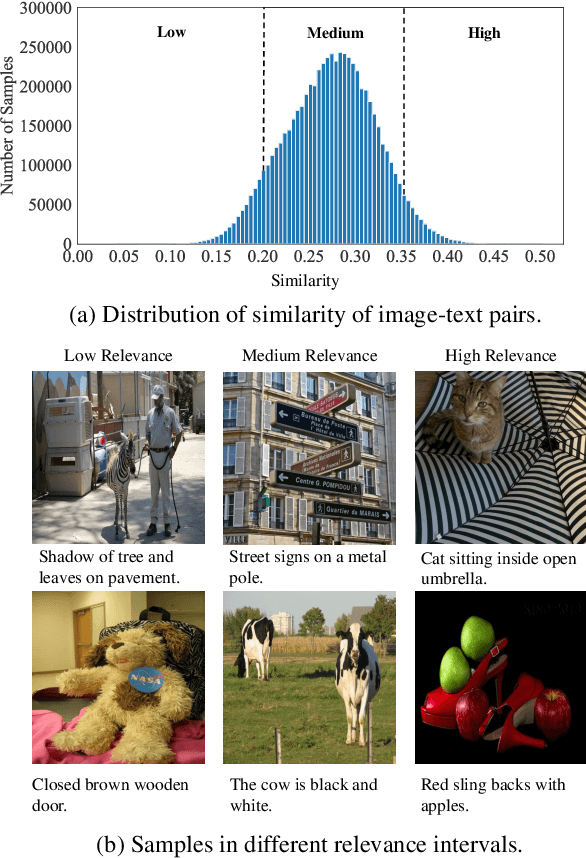
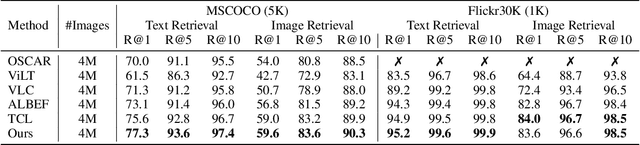
Image and language modeling is of crucial importance for vision-language pre-training (VLP), which aims to learn multi-modal representations from large-scale paired image-text data. However, we observe that most existing VLP methods focus on modeling the interactions between image and text features while neglecting the information disparity between image and text, thus suffering from focal bias. To address this problem, we propose a vision-language masked autoencoder framework (VLMAE). VLMAE employs visual generative learning, facilitating the model to acquire fine-grained and unbiased features. Unlike the previous works, VLMAE pays attention to almost all critical patches in an image, providing more comprehensive understanding. Extensive experiments demonstrate that VLMAE achieves better performance in various vision-language downstream tasks, including visual question answering, image-text retrieval and visual grounding, even with up to 20% pre-training speedup.
Exploiting Feature Diversity for Make-up Temporal Video Grounding
Aug 12, 2022
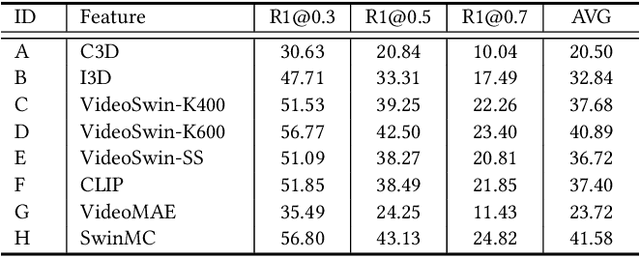

This technical report presents the 3rd winning solution for MTVG, a new task introduced in the 4-th Person in Context (PIC) Challenge at ACM MM 2022. MTVG aims at localizing the temporal boundary of the step in an untrimmed video based on a textual description. The biggest challenge of this task is the fi ne-grained video-text semantics of make-up steps. However, current methods mainly extract video features using action-based pre-trained models. As actions are more coarse-grained than make-up steps, action-based features are not sufficient to provide fi ne-grained cues. To address this issue,we propose to achieve fi ne-grained representation via exploiting feature diversities. Specifically, we proposed a series of methods from feature extraction, network optimization, to model ensemble. As a result, we achieved 3rd place in the MTVG competition.
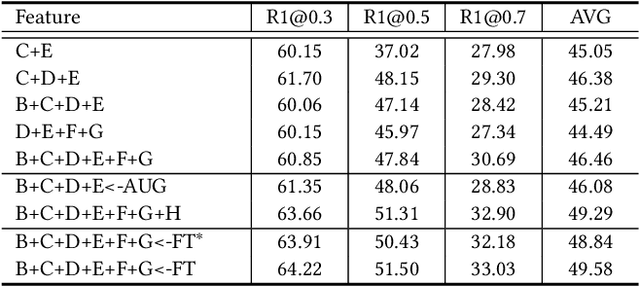
Open-Vocabulary Multi-Label Classification via Multi-modal Knowledge Transfer
Jul 05, 2022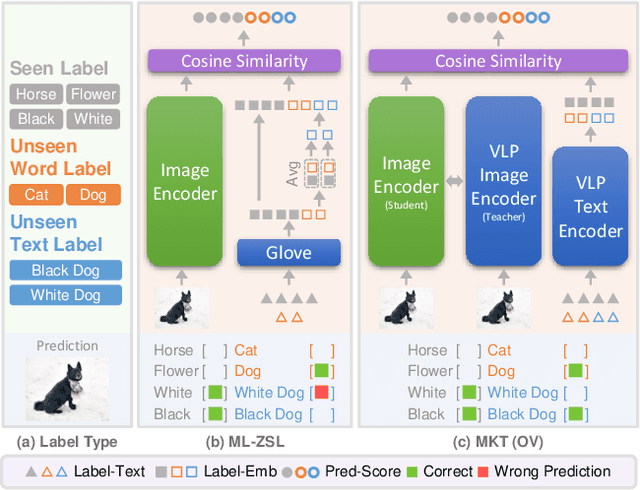

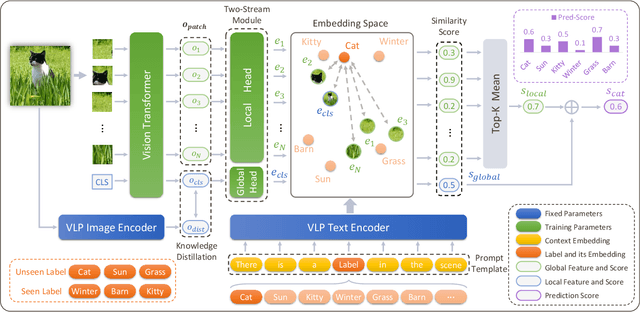
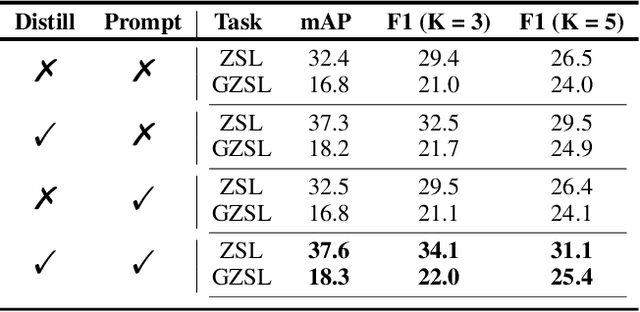
Real-world recognition system often encounters a plenty of unseen labels in practice. To identify such unseen labels, multi-label zero-shot learning (ML-ZSL) focuses on transferring knowledge by a pre-trained textual label embedding (e.g., GloVe). However, such methods only exploit singlemodal knowledge from a language model, while ignoring the rich semantic information inherent in image-text pairs. Instead, recently developed open-vocabulary (OV) based methods succeed in exploiting such information of image-text pairs in object detection, and achieve impressive performance. Inspired by the success of OV-based methods, we propose a novel open-vocabulary framework, named multimodal knowledge transfer (MKT), for multi-label classification. Specifically, our method exploits multi-modal knowledge of image-text pairs based on a vision and language pretraining (VLP) model. To facilitate transferring the imagetext matching ability of VLP model, knowledge distillation is used to guarantee the consistency of image and label embeddings, along with prompt tuning to further update the label embeddings. To further recognize multiple objects, a simple but effective two-stream module is developed to capture both local and global features. Extensive experimental results show that our method significantly outperforms state-of-theart methods on public benchmark datasets. Code will be available at https://github.com/seanhe97/MKT.
MuCAN: Multi-Correspondence Aggregation Network for Video Super-Resolution
Jul 23, 2020



Video super-resolution (VSR) aims to utilize multiple low-resolution frames to generate a high-resolution prediction for each frame. In this process, inter- and intra-frames are the key sources for exploiting temporal and spatial information. However, there are a couple of limitations for existing VSR methods. First, optical flow is often used to establish temporal correspondence. But flow estimation itself is error-prone and affects recovery results. Second, similar patterns existing in natural images are rarely exploited for the VSR task. Motivated by these findings, we propose a temporal multi-correspondence aggregation strategy to leverage similar patches across frames, and a cross-scale nonlocal-correspondence aggregation scheme to explore self-similarity of images across scales. Based on these two new modules, we build an effective multi-correspondence aggregation network (MuCAN) for VSR. Our method achieves state-of-the-art results on multiple benchmark datasets. Extensive experiments justify the effectiveness of our method.