 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianle Zhang
Towards Fairness-Aware Adversarial Learning
Feb 27, 2024
Although adversarial training (AT) has proven effective in enhancing the model's robustness, the recently revealed issue of fairness in robustness has not been well addressed, i.e. the robust accuracy varies significantly among different categories. In this paper, instead of uniformly evaluating the model's average class performance, we delve into the issue of robust fairness, by considering the worst-case distribution across various classes. We propose a novel learning paradigm, named Fairness-Aware Adversarial Learning (FAAL). As a generalization of conventional AT, we re-define the problem of adversarial training as a min-max-max framework, to ensure both robustness and fairness of the trained model. Specifically, by taking advantage of distributional robust optimization, our method aims to find the worst distribution among different categories, and the solution is guaranteed to obtain the upper bound performance with high probability. In particular, FAAL can fine-tune an unfair robust model to be fair within only two epochs, without compromising the overall clean and robust accuracies. Extensive experiments on various image datasets validate the superior performance and efficiency of the proposed FAAL compared to other state-of-the-art methods.
Two Trades is not Baffled: Condensing Graph via Crafting Rational Gradient Matching
Feb 08, 2024Training on large-scale graphs has achieved remarkable results in graph representation learning, but its cost and storage have raised growing concerns. As one of the most promising directions, graph condensation methods address these issues by employing gradient matching, aiming to condense the full graph into a more concise yet information-rich synthetic set. Though encouraging, these strategies primarily emphasize matching directions of the gradients, which leads to deviations in the training trajectories. Such deviations are further magnified by the differences between the condensation and evaluation phases, culminating in accumulated errors, which detrimentally affect the performance of the condensed graphs. In light of this, we propose a novel graph condensation method named \textbf{C}raf\textbf{T}ing \textbf{R}ationa\textbf{L} trajectory (\textbf{CTRL}), which offers an optimized starting point closer to the original dataset's feature distribution and a more refined strategy for gradient matching. Theoretically, CTRL can effectively neutralize the impact of accumulated errors on the performance of condensed graphs. We provide extensive experiments on various graph datasets and downstream tasks to support the effectiveness of CTRL. Code is released at https://github.com/NUS-HPC-AI-Lab/CTRL.
Navigating Complexity: Toward Lossless Graph Condensation via Expanding Window Matching
Feb 07, 2024Graph condensation aims to reduce the size of a large-scale graph dataset by synthesizing a compact counterpart without sacrificing the performance of Graph Neural Networks (GNNs) trained on it, which has shed light on reducing the computational cost for training GNNs. Nevertheless, existing methods often fall short of accurately replicating the original graph for certain datasets, thereby failing to achieve the objective of lossless condensation. To understand this phenomenon, we investigate the potential reasons and reveal that the previous state-of-the-art trajectory matching method provides biased and restricted supervision signals from the original graph when optimizing the condensed one. This significantly limits both the scale and efficacy of the condensed graph. In this paper, we make the first attempt toward \textit{lossless graph condensation} by bridging the previously neglected supervision signals. Specifically, we employ a curriculum learning strategy to train expert trajectories with more diverse supervision signals from the original graph, and then effectively transfer the information into the condensed graph with expanding window matching. Moreover, we design a loss function to further extract knowledge from the expert trajectories. Theoretical analysis justifies the design of our method and extensive experiments verify its superiority across different datasets. Code is released at https://github.com/NUS-HPC-AI-Lab/GEOM.
Reward Certification for Policy Smoothed Reinforcement Learning
Dec 12, 2023Reinforcement Learning (RL) has achieved remarkable success in safety-critical areas, but it can be weakened by adversarial attacks. Recent studies have introduced "smoothed policies" in order to enhance its robustness. Yet, it is still challenging to establish a provable guarantee to certify the bound of its total reward. Prior methods relied primarily on computing bounds using Lipschitz continuity or calculating the probability of cumulative reward above specific thresholds. However, these techniques are only suited for continuous perturbations on the RL agent's observations and are restricted to perturbations bounded by the $l_2$-norm. To address these limitations, this paper proposes a general black-box certification method capable of directly certifying the cumulative reward of the smoothed policy under various $l_p$-norm bounded perturbations. Furthermore, we extend our methodology to certify perturbations on action spaces. Our approach leverages f-divergence to measure the distinction between the original distribution and the perturbed distribution, subsequently determining the certification bound by solving a convex optimisation problem. We provide a comprehensive theoretical analysis and run sufficient experiments in multiple environments. Our results show that our method not only improves the certified lower bound of mean cumulative reward but also demonstrates better efficiency than state-of-the-art techniques.
Can pre-trained models assist in dataset distillation?
Oct 05, 2023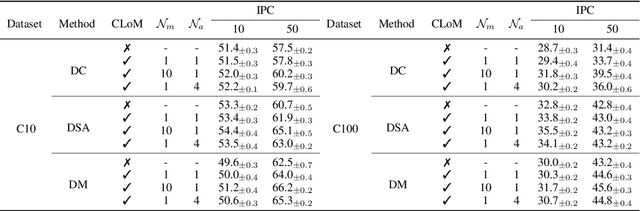
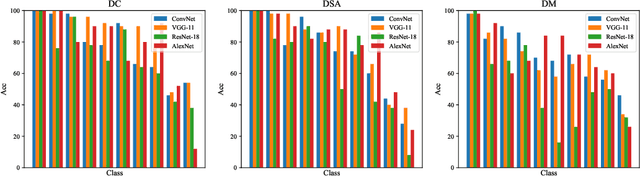


Dataset Distillation (DD) is a prominent technique that encapsulates knowledge from a large-scale original dataset into a small synthetic dataset for efficient training. Meanwhile, Pre-trained Models (PTMs) function as knowledge repositories, containing extensive information from the original dataset. This naturally raises a question: Can PTMs effectively transfer knowledge to synthetic datasets, guiding DD accurately? To this end, we conduct preliminary experiments, confirming the contribution of PTMs to DD. Afterwards, we systematically study different options in PTMs, including initialization parameters, model architecture, training epoch and domain knowledge, revealing that: 1) Increasing model diversity enhances the performance of synthetic datasets; 2) Sub-optimal models can also assist in DD and outperform well-trained ones in certain cases; 3) Domain-specific PTMs are not mandatory for DD, but a reasonable domain match is crucial. Finally, by selecting optimal options, we significantly improve the cross-architecture generalization over baseline DD methods. We hope our work will facilitate researchers to develop better DD techniques. Our code is available at https://github.com/yaolu-zjut/DDInterpreter.
Symplectic Structure-Aware Hamiltonian (Graph) Embeddings
Sep 09, 2023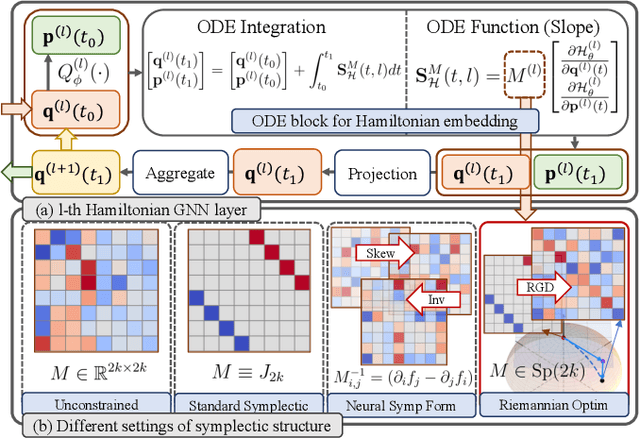
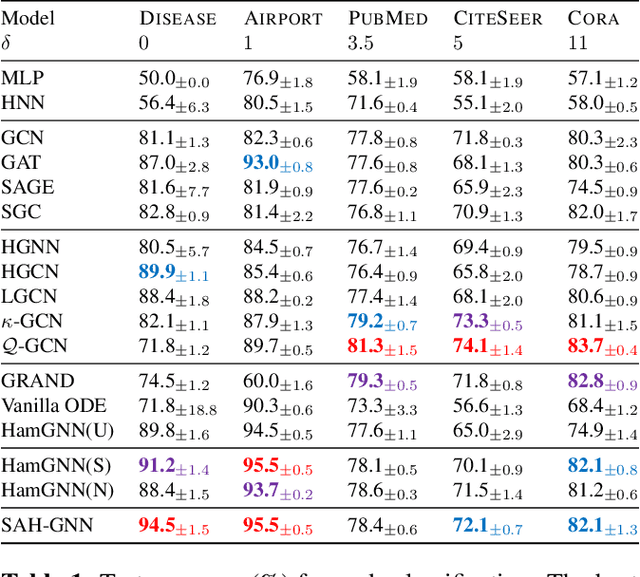
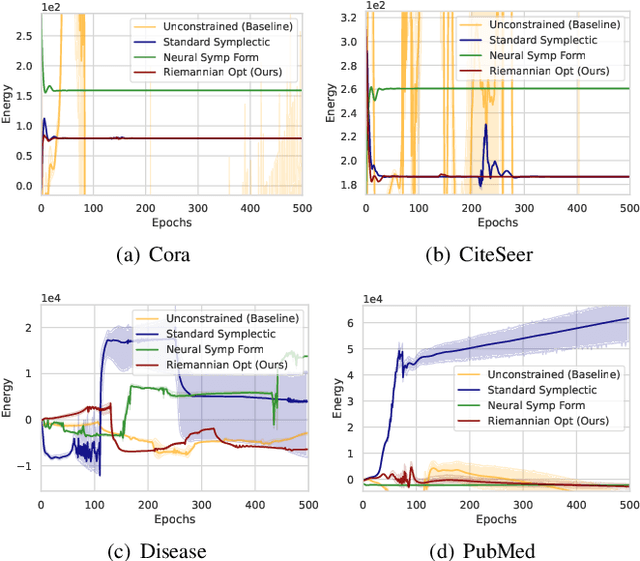
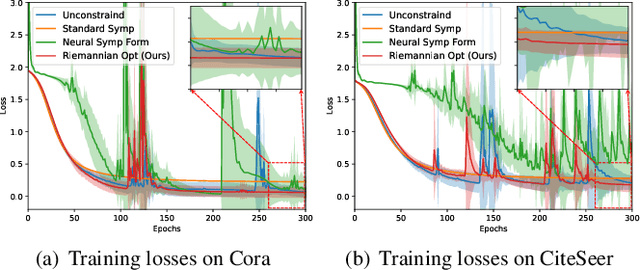
In traditional Graph Neural Networks (GNNs), the assumption of a fixed embedding manifold often limits their adaptability to diverse graph geometries. Recently, Hamiltonian system-inspired GNNs are proposed to address the dynamic nature of such embeddings by incorporating physical laws into node feature updates. In this work, we present SAH-GNN, a novel approach that generalizes Hamiltonian dynamics for more flexible node feature updates. Unlike existing Hamiltonian-inspired GNNs, SAH-GNN employs Riemannian optimization on the symplectic Stiefel manifold to adaptively learn the underlying symplectic structure during training, circumventing the limitations of existing Hamiltonian GNNs that rely on a pre-defined form of standard symplectic structure. This innovation allows SAH-GNN to automatically adapt to various graph datasets without extensive hyperparameter tuning. Moreover, it conserves energy during training such that the implicit Hamiltonian system is physically meaningful. To this end, we empirically validate SAH-GNN's superior performance and adaptability in node classification tasks across multiple types of graph datasets.
PTDE: Personalized Training with Distillated Execution for Multi-Agent Reinforcement Learning
Oct 17, 2022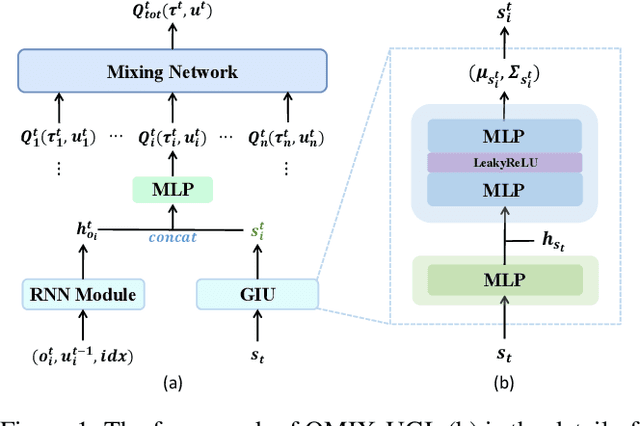
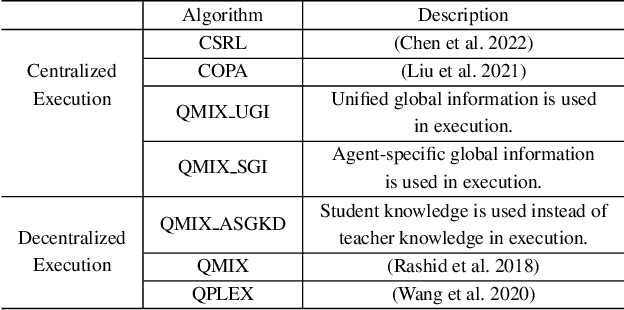
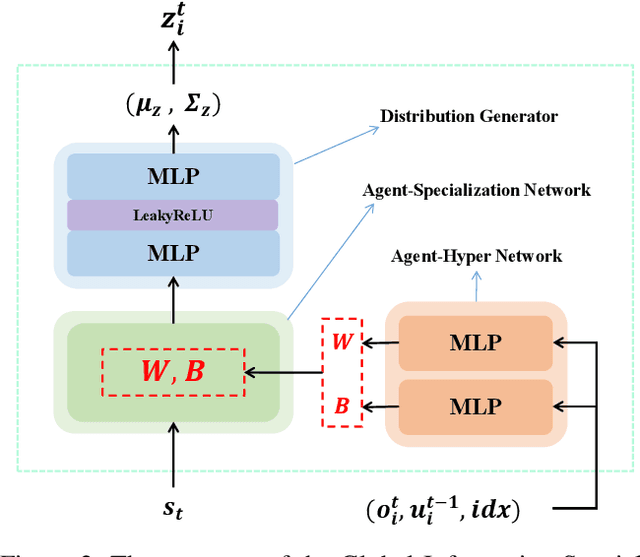
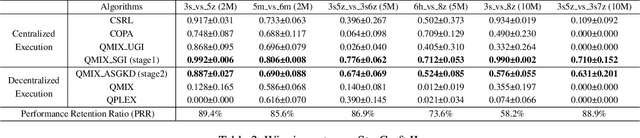
Centralized Training with Decentralized Execution (CTDE) has been a very popular paradigm for multi-agent reinforcement learning. One of its main features is making full use of the global information to learn a better joint $Q$-function or centralized critic. In this paper, we in turn explore how to leverage the global information to directly learn a better individual $Q$-function or individual actor. We find that applying the same global information to all agents indiscriminately is not enough for good performance, and thus propose to specify the global information for each agent to obtain agent-specific global information for better performance. Furthermore, we distill such agent-specific global information into the agent's local information, which is used during decentralized execution without too much performance degradation. We call this new paradigm Personalized Training with Distillated Execution (PTDE). PTDE can be easily combined with many state-of-the-art algorithms to further improve their performance, which is verified in both SMAC and Google Research Football scenarios.
PRoA: A Probabilistic Robustness Assessment against Functional Perturbations
Jul 05, 2022

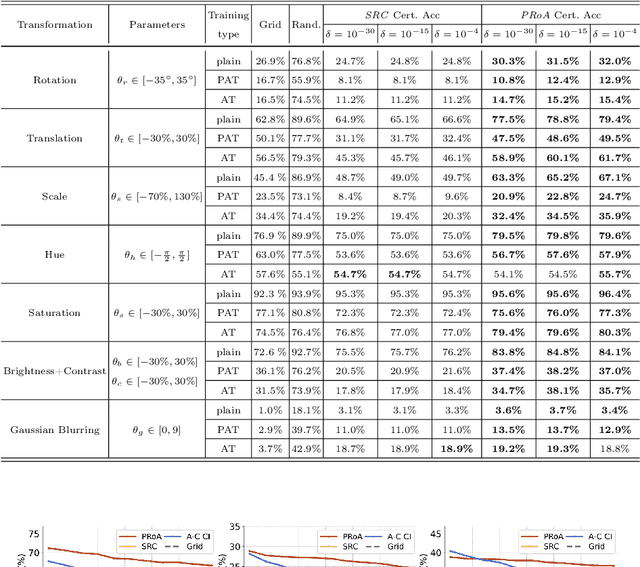
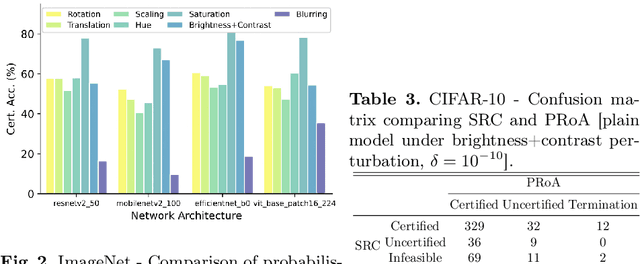
In safety-critical deep learning applications robustness measurement is a vital pre-deployment phase. However, existing robustness verification methods are not sufficiently practical for deploying machine learning systems in the real world. On the one hand, these methods attempt to claim that no perturbations can ``fool'' deep neural networks (DNNs), which may be too stringent in practice. On the other hand, existing works rigorously consider $L_p$ bounded additive perturbations on the pixel space, although perturbations, such as colour shifting and geometric transformations, are more practically and frequently occurring in the real world. Thus, from the practical standpoint, we present a novel and general {\it probabilistic robustness assessment method} (PRoA) based on the adaptive concentration, and it can measure the robustness of deep learning models against functional perturbations. PRoA can provide statistical guarantees on the probabilistic robustness of a model, \textit{i.e.}, the probability of failure encountered by the trained model after deployment. Our experiments demonstrate the effectiveness and flexibility of PRoA in terms of evaluating the probabilistic robustness against a broad range of functional perturbations, and PRoA can scale well to various large-scale deep neural networks compared to existing state-of-the-art baselines. For the purpose of reproducibility, we release our tool on GitHub: \url{ https://github.com/TrustAI/PRoA}.