 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTianyu Fu
A Survey on Efficient Inference for Large Language Models
Apr 22, 2024
Large Language Models (LLMs) have attracted extensive attention due to their remarkable performance across various tasks. However, the substantial computational and memory requirements of LLM inference pose challenges for deployment in resource-constrained scenarios. Efforts within the field have been directed towards developing techniques aimed at enhancing the efficiency of LLM inference. This paper presents a comprehensive survey of the existing literature on efficient LLM inference. We start by analyzing the primary causes of the inefficient LLM inference, i.e., the large model size, the quadratic-complexity attention operation, and the auto-regressive decoding approach. Then, we introduce a comprehensive taxonomy that organizes the current literature into data-level, model-level, and system-level optimization. Moreover, the paper includes comparative experiments on representative methods within critical sub-fields to provide quantitative insights. Last but not least, we provide some knowledge summary and discuss future research directions.
Representation Learning for Frequent Subgraph Mining
Feb 22, 2024Identifying frequent subgraphs, also called network motifs, is crucial in analyzing and predicting properties of real-world networks. However, finding large commonly-occurring motifs remains a challenging problem not only due to its NP-hard subroutine of subgraph counting, but also the exponential growth of the number of possible subgraphs patterns. Here we present Subgraph Pattern Miner (SPMiner), a novel neural approach for approximately finding frequent subgraphs in a large target graph. SPMiner combines graph neural networks, order embedding space, and an efficient search strategy to identify network subgraph patterns that appear most frequently in the target graph. SPMiner first decomposes the target graph into many overlapping subgraphs and then encodes each subgraph into an order embedding space. SPMiner then uses a monotonic walk in the order embedding space to identify frequent motifs. Compared to existing approaches and possible neural alternatives, SPMiner is more accurate, faster, and more scalable. For 5- and 6-node motifs, we show that SPMiner can almost perfectly identify the most frequent motifs while being 100x faster than exact enumeration methods. In addition, SPMiner can also reliably identify frequent 10-node motifs, which is well beyond the size limit of exact enumeration approaches. And last, we show that SPMiner can find large up to 20 node motifs with 10-100x higher frequency than those found by current approximate methods.
FlightLLM: Efficient Large Language Model Inference with a Complete Mapping Flow on FPGAs
Jan 09, 2024Transformer-based Large Language Models (LLMs) have made a significant impact on various domains. However, LLMs' efficiency suffers from both heavy computation and memory overheads. Compression techniques like sparsification and quantization are commonly used to mitigate the gap between LLM's computation/memory overheads and hardware capacity. However, existing GPU and transformer-based accelerators cannot efficiently process compressed LLMs, due to the following unresolved challenges: low computational efficiency, underutilized memory bandwidth, and large compilation overheads. This paper proposes FlightLLM, enabling efficient LLMs inference with a complete mapping flow on FPGAs. In FlightLLM, we highlight an innovative solution that the computation and memory overhead of LLMs can be solved by utilizing FPGA-specific resources (e.g., DSP48 and heterogeneous memory hierarchy). We propose a configurable sparse DSP chain to support different sparsity patterns with high computation efficiency. Second, we propose an always-on-chip decode scheme to boost memory bandwidth with mixed-precision support. Finally, to make FlightLLM available for real-world LLMs, we propose a length adaptive compilation method to reduce the compilation overhead. Implemented on the Xilinx Alveo U280 FPGA, FlightLLM achieves 6.0$\times$ higher energy efficiency and 1.8$\times$ better cost efficiency against commercial GPUs (e.g., NVIDIA V100S) on modern LLMs (e.g., LLaMA2-7B) using vLLM and SmoothQuant under the batch size of one. FlightLLM beats NVIDIA A100 GPU with 1.2$\times$ higher throughput using the latest Versal VHK158 FPGA.
DeSCo: Towards Generalizable and Scalable Deep Subgraph Counting
Aug 16, 2023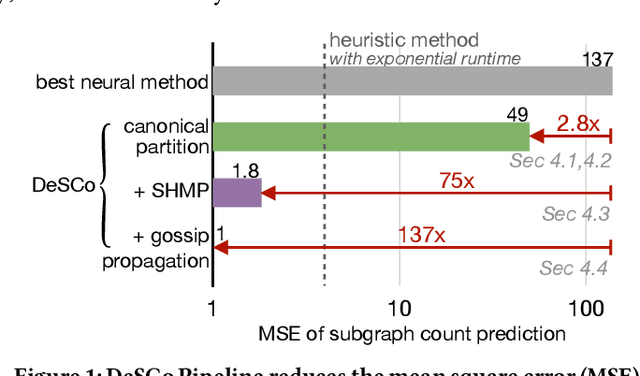
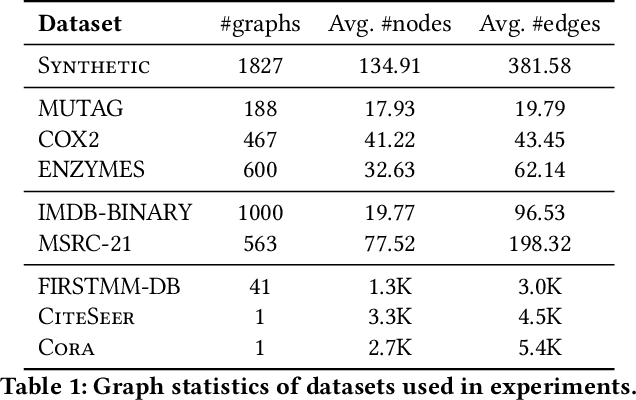

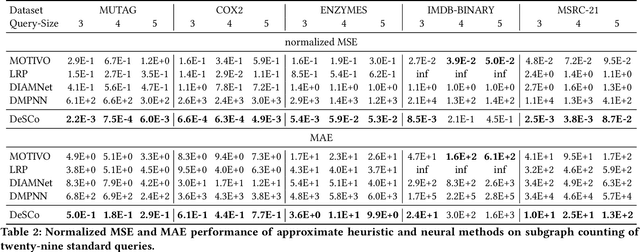
Subgraph counting is the problem of counting the occurrences of a given query graph in a large target graph. Large-scale subgraph counting is useful in various domains, such as motif counting for social network analysis and loop counting for money laundering detection on transaction networks. Recently, to address the exponential runtime complexity of scalable subgraph counting, neural methods are proposed. However, existing neural counting approaches fall short in three aspects. Firstly, the counts of the same query can vary from zero to millions on different target graphs, posing a much larger challenge than most graph regression tasks. Secondly, current scalable graph neural networks have limited expressive power and fail to efficiently distinguish graphs in count prediction. Furthermore, existing neural approaches cannot predict the occurrence position of queries in the target graph. Here we design DeSCo, a scalable neural deep subgraph counting pipeline, which aims to accurately predict the query count and occurrence position on any target graph after one-time training. Firstly, DeSCo uses a novel canonical partition and divides the large target graph into small neighborhood graphs. The technique greatly reduces the count variation while guaranteeing no missing or double-counting. Secondly, neighborhood counting uses an expressive subgraph-based heterogeneous graph neural network to accurately perform counting in each neighborhood. Finally, gossip propagation propagates neighborhood counts with learnable gates to harness the inductive biases of motif counts. DeSCo is evaluated on eight real-world datasets from various domains. It outperforms state-of-the-art neural methods with 137x improvement in the mean squared error of count prediction, while maintaining the polynomial runtime complexity.
High-Resolution Boundary Detection for Medical Image Segmentation with Piece-Wise Two-Sample T-Test Augmented Loss
Nov 04, 2022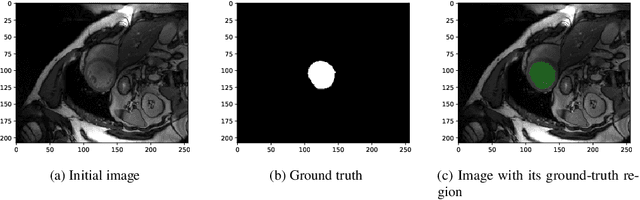
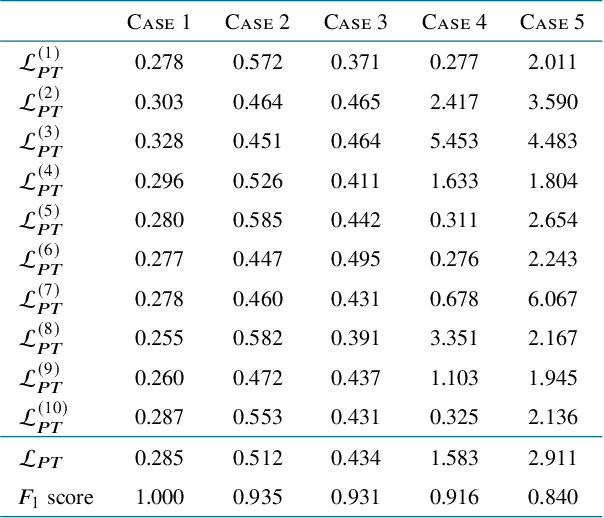
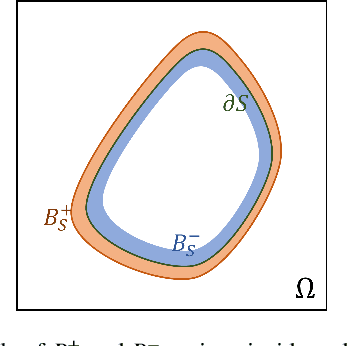
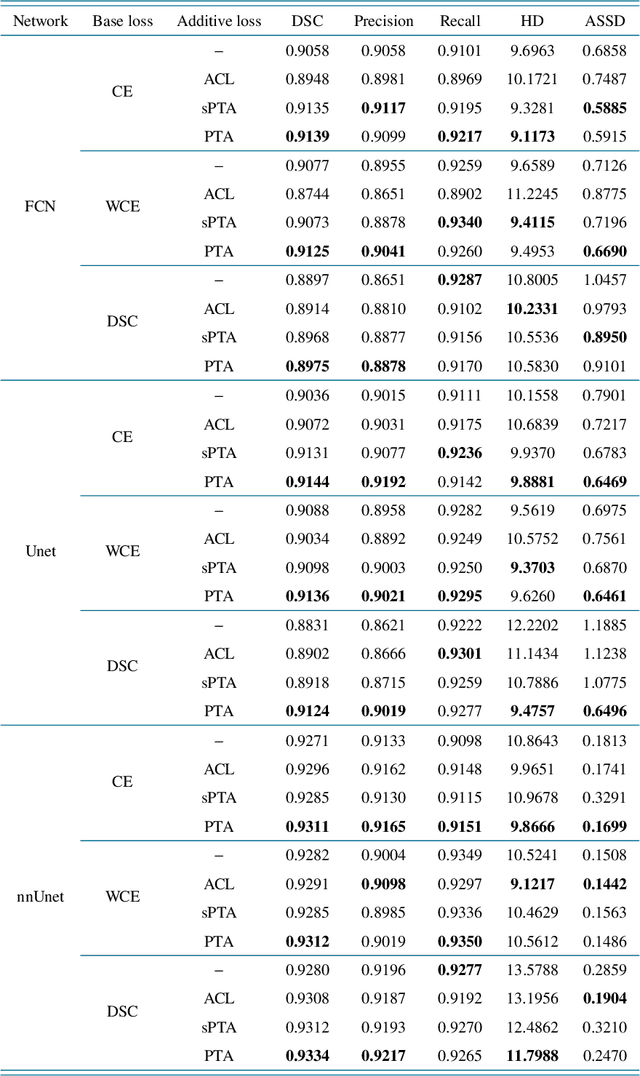
Deep learning methods have contributed substantially to the rapid advancement of medical image segmentation, the quality of which relies on the suitable design of loss functions. Popular loss functions, including the cross-entropy and dice losses, often fall short of boundary detection, thereby limiting high-resolution downstream applications such as automated diagnoses and procedures. We developed a novel loss function that is tailored to reflect the boundary information to enhance the boundary detection. As the contrast between segmentation and background regions along the classification boundary naturally induces heterogeneity over the pixels, we propose the piece-wise two-sample t-test augmented (PTA) loss that is infused with the statistical test for such heterogeneity. We demonstrate the improved boundary detection power of the PTA loss compared to benchmark losses without a t-test component.
Mis-classified Vector Guided Softmax Loss for Face Recognition
Nov 26, 2019
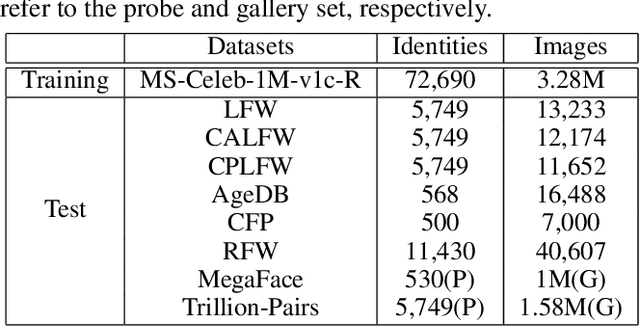
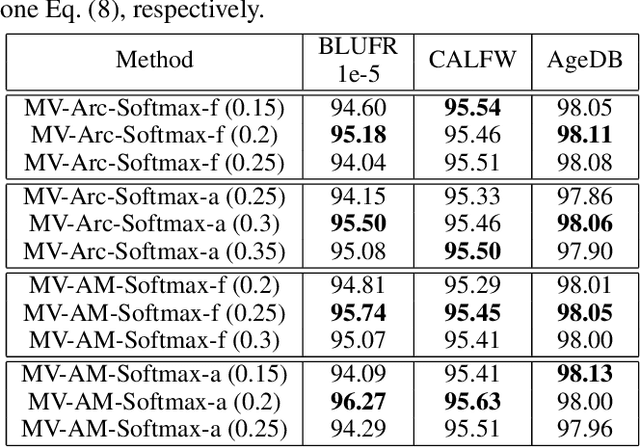
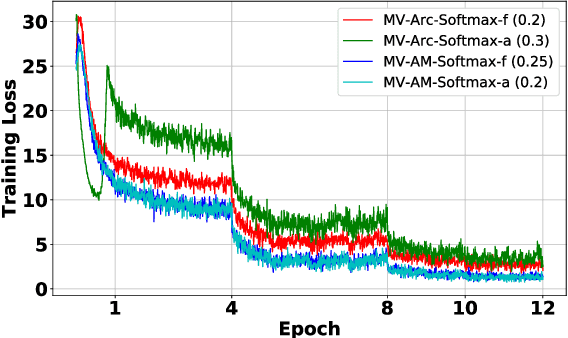
Face recognition has witnessed significant progress due to the advances of deep convolutional neural networks (CNNs), the central task of which is how to improve the feature discrimination. To this end, several margin-based (\textit{e.g.}, angular, additive and additive angular margins) softmax loss functions have been proposed to increase the feature margin between different classes. However, despite great achievements have been made, they mainly suffer from three issues: 1) Obviously, they ignore the importance of informative features mining for discriminative learning; 2) They encourage the feature margin only from the ground truth class, without realizing the discriminability from other non-ground truth classes; 3) The feature margin between different classes is set to be same and fixed, which may not adapt the situations very well. To cope with these issues, this paper develops a novel loss function, which adaptively emphasizes the mis-classified feature vectors to guide the discriminative feature learning. Thus we can address all the above issues and achieve more discriminative face features. To the best of our knowledge, this is the first attempt to inherit the advantages of feature margin and feature mining into a unified loss function. Experimental results on several benchmarks have demonstrated the effectiveness of our method over state-of-the-art alternatives.
Meta Anti-spoofing: Learning to Learn in Face Anti-spoofing
Apr 29, 2019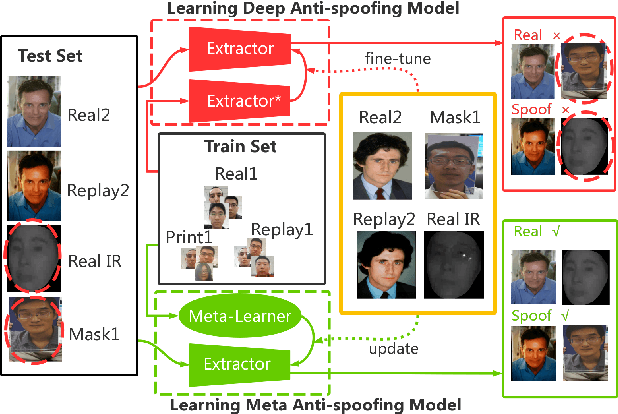
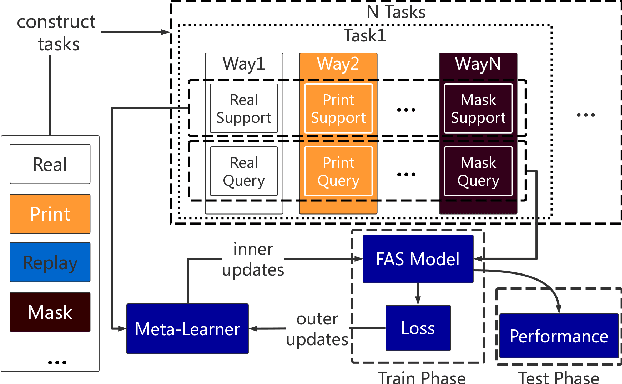
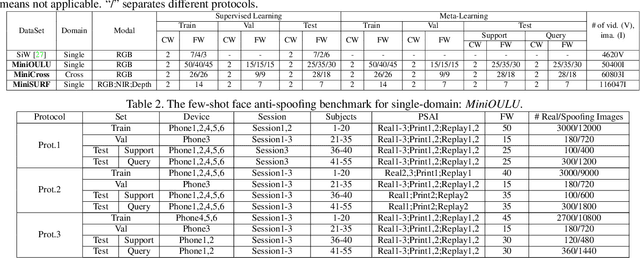

Face anti-spoofing is crucial to the security of face recognition systems. Previously, most methods formulate face anti-spoofing as a supervised learning problem to detect various predefined presentation attacks (PA). However, new attack methods keep evolving that produce new forms of spoofing faces to compromise the existing detectors. This requires researchers to collect a large number of samples to train classifiers for detecting new attacks, which is often costly and leads the later newly evolved attack samples to remain in small scales. Alternatively, we define face anti-spoofing as a few-shot learning problem with evolving new attacks and propose a novel face anti-spoofing approach via meta-learning named Meta Face Anti-spoofing (Meta-FAS). Meta-FAS addresses the above-mentioned problems by training the classifiers how to learn to detect the spoofing faces with few examples. To assess the effectiveness of the proposed approach, we propose a series of evaluation benchmarks based on public datasets (\textit{e.g.}, OULU-NPU, SiW, CASIA-MFSD, Replay-Attack, MSU-MFSD, 3D-MAD, and CASIA-SURF), and the proposed approach shows its superior performances to compared methods.
Improved Selective Refinement Network for Face Detection
Jan 23, 2019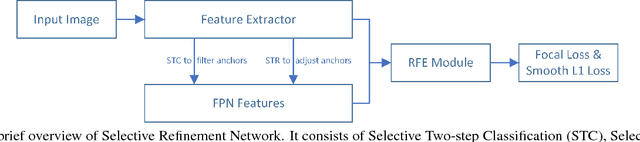
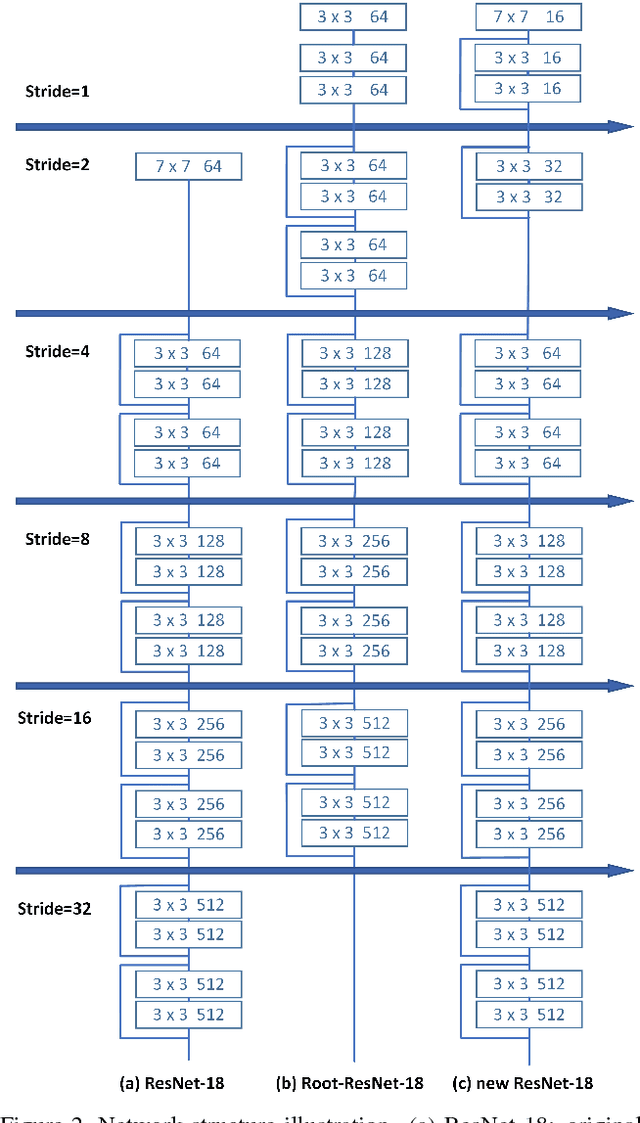

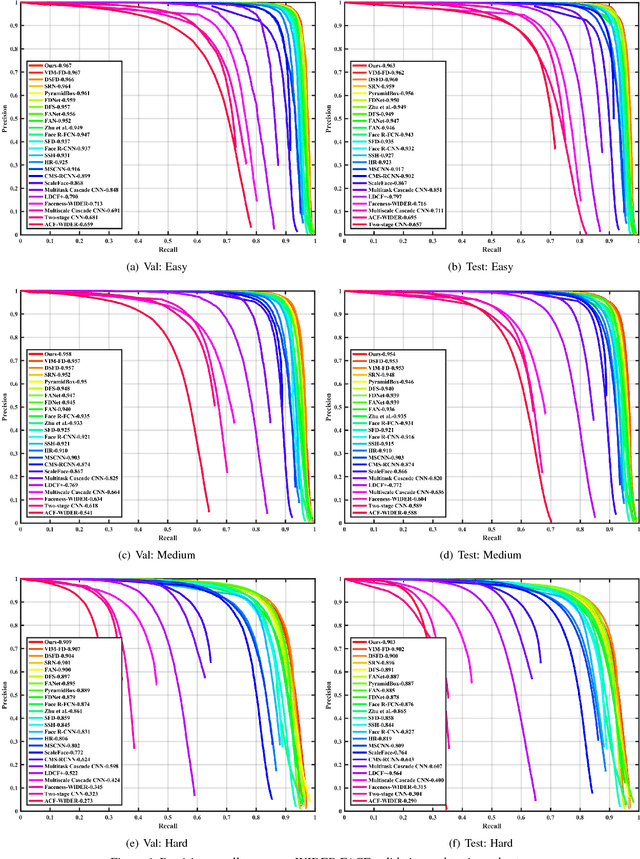
As a long-standing problem in computer vision, face detection has attracted much attention in recent decades for its practical applications. With the availability of face detection benchmark WIDER FACE dataset, much of the progresses have been made by various algorithms in recent years. Among them, the Selective Refinement Network (SRN) face detector introduces the two-step classification and regression operations selectively into an anchor-based face detector to reduce false positives and improve location accuracy simultaneously. Moreover, it designs a receptive field enhancement block to provide more diverse receptive field. In this report, to further improve the performance of SRN, we exploit some existing techniques via extensive experiments, including new data augmentation strategy, improved backbone network, MS COCO pretraining, decoupled classification module, segmentation branch and Squeeze-and-Excitation block. Some of these techniques bring performance improvements, while few of them do not well adapt to our baseline. As a consequence, we present an improved SRN face detector by combining these useful techniques together and obtain the best performance on widely used face detection benchmark WIDER FACE dataset.
Support Vector Guided Softmax Loss for Face Recognition
Dec 29, 2018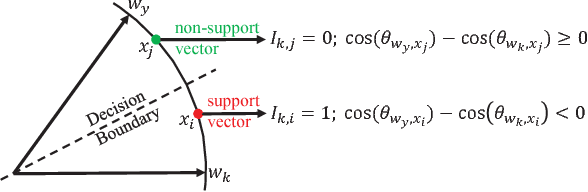
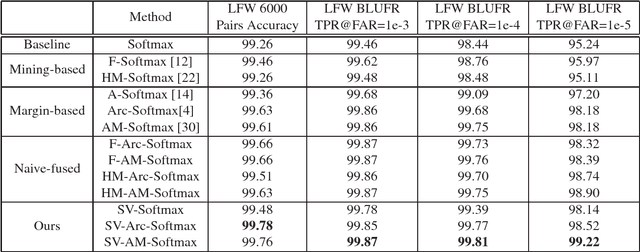
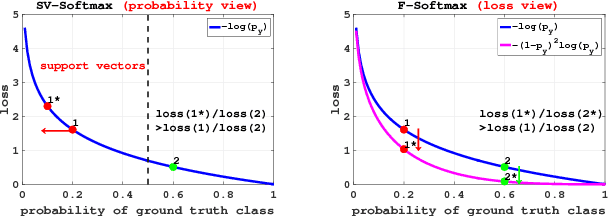

Face recognition has witnessed significant progresses due to the advances of deep convolutional neural networks (CNNs), the central challenge of which, is feature discrimination. To address it, one group tries to exploit mining-based strategies (\textit{e.g.}, hard example mining and focal loss) to focus on the informative examples. The other group devotes to designing margin-based loss functions (\textit{e.g.}, angular, additive and additive angular margins) to increase the feature margin from the perspective of ground truth class. Both of them have been well-verified to learn discriminative features. However, they suffer from either the ambiguity of hard examples or the lack of discriminative power of other classes. In this paper, we design a novel loss function, namely support vector guided softmax loss (SV-Softmax), which adaptively emphasizes the mis-classified points (support vectors) to guide the discriminative features learning. So the developed SV-Softmax loss is able to eliminate the ambiguity of hard examples as well as absorb the discriminative power of other classes, and thus results in more discrimiantive features. To the best of our knowledge, this is the first attempt to inherit the advantages of mining-based and margin-based losses into one framework. Experimental results on several benchmarks have demonstrated the effectiveness of our approach over state-of-the-arts.