 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTillman Weyde
Improved Data Generation for Enhanced Asset Allocation: A Synthetic Dataset Approach for the Fixed Income Universe
Nov 27, 2023
We present a novel process for generating synthetic datasets tailored to assess asset allocation methods and construct portfolios within the fixed income universe. Our approach begins by enhancing the CorrGAN model to generate synthetic correlation matrices. Subsequently, we propose an Encoder-Decoder model that samples additional data conditioned on a given correlation matrix. The resulting synthetic dataset facilitates in-depth analyses of asset allocation methods across diverse asset universes. Additionally, we provide a case study that exemplifies the use of the synthetic dataset to improve portfolios constructed within a simulation-based asset allocation process.
NeSy4VRD: A Multifaceted Resource for Neurosymbolic AI Research using Knowledge Graphs in Visual Relationship Detection
May 22, 2023
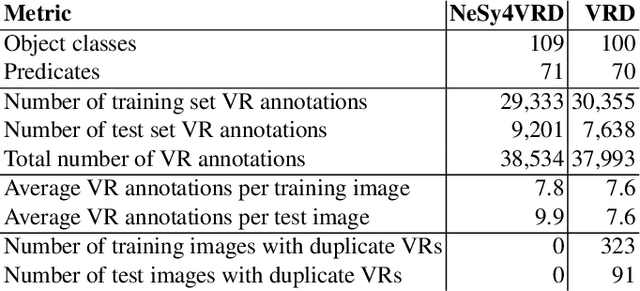
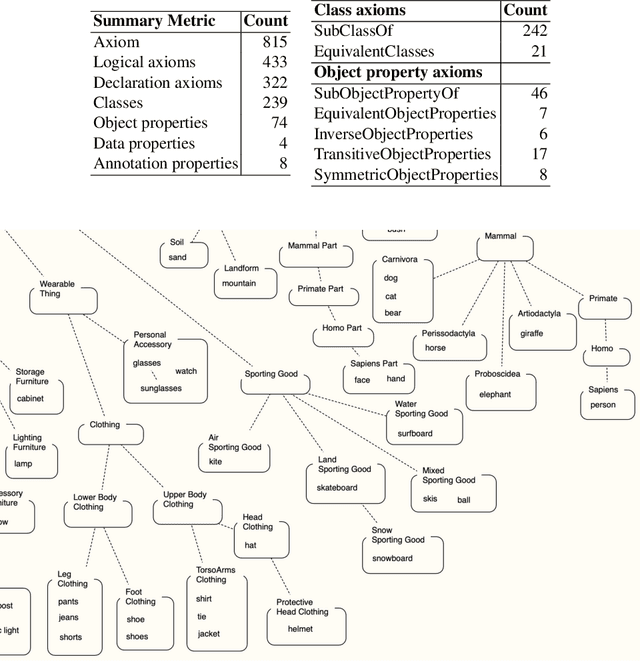
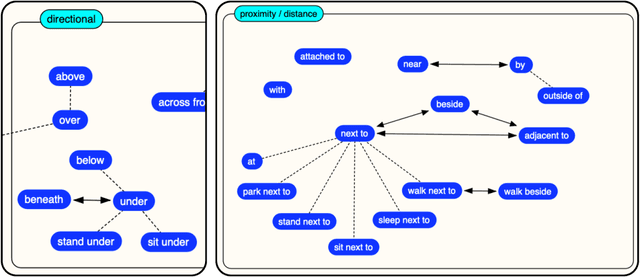
NeSy4VRD is a multifaceted resource designed to support the development of neurosymbolic AI (NeSy) research. NeSy4VRD re-establishes public access to the images of the VRD dataset and couples them with an extensively revised, quality-improved version of the VRD visual relationship annotations. Crucially, NeSy4VRD provides a well-aligned, companion OWL ontology that describes the dataset domain.It comes with open source infrastructure that provides comprehensive support for extensibility of the annotations (which, in turn, facilitates extensibility of the ontology), and open source code for loading the annotations to/from a knowledge graph. We are contributing NeSy4VRD to the computer vision, NeSy and Semantic Web communities to help foster more NeSy research using OWL-based knowledge graphs.
Theoretical Conditions and Empirical Failure of Bracket Counting on Long Sequences with Linear Recurrent Networks
Apr 07, 2023
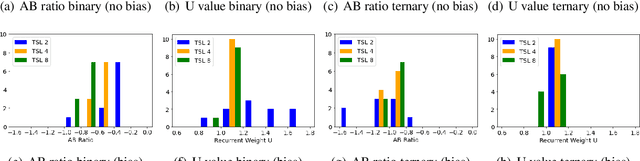
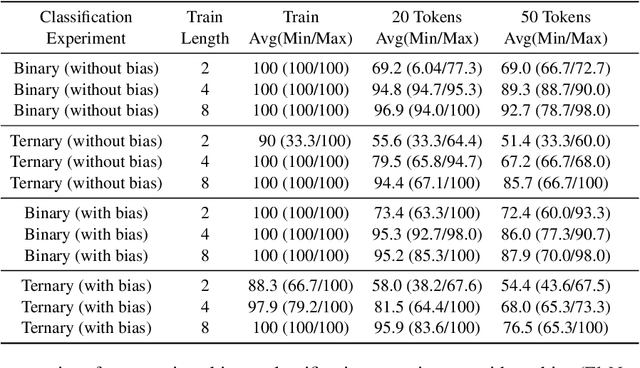
Previous work has established that RNNs with an unbounded activation function have the capacity to count exactly. However, it has also been shown that RNNs are challenging to train effectively and generally do not learn exact counting behaviour. In this paper, we focus on this problem by studying the simplest possible RNN, a linear single-cell network. We conduct a theoretical analysis of linear RNNs and identify conditions for the models to exhibit exact counting behaviour. We provide a formal proof that these conditions are necessary and sufficient. We also conduct an empirical analysis using tasks involving a Dyck-1-like Balanced Bracket language under two different settings. We observe that linear RNNs generally do not meet the necessary and sufficient conditions for counting behaviour when trained with the standard approach. We investigate how varying the length of training sequences and utilising different target classes impacts model behaviour during training and the ability of linear RNN models to effectively approximate the indicator conditions.
Towards a Unified Model for Generating Answers and Explanations in Visual Question Answering
Jan 25, 2023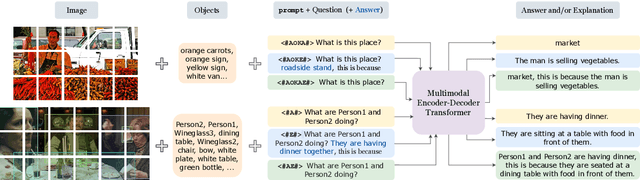
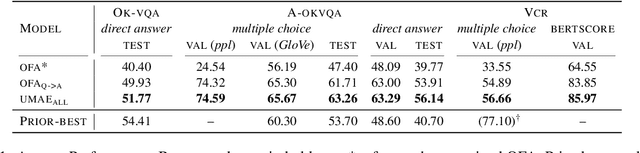
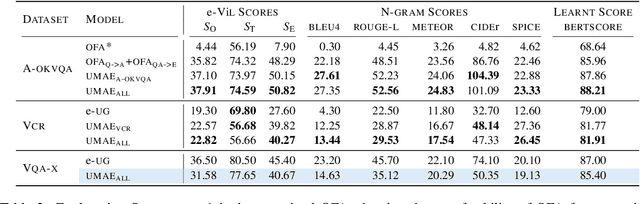

Providing explanations for visual question answering (VQA) has gained much attention in research. However, most existing systems use separate models for predicting answers and providing explanations. We argue that training explanation models independently of the QA model makes the explanations less grounded and limits performance. To address this, we propose a multitask learning approach towards a Unified Model for more grounded and consistent generation of both Answers and Explanations (UMAE). To achieve this, we add artificial prompt tokens to training instances and finetune a multimodal encoder-decoder model on various VQA tasks. In our experiments, UMAE models surpass the prior SOTA answer accuracy on A-OKVQA by 10~15%, show competitive results on OK-VQA, achieve new SOTA explanation scores on A-OKVQA and VCR, and demonstrate promising out-of-domain performance on VQA-X.
Exploring the Long-Term Generalization of Counting Behavior in RNNs
Nov 29, 2022
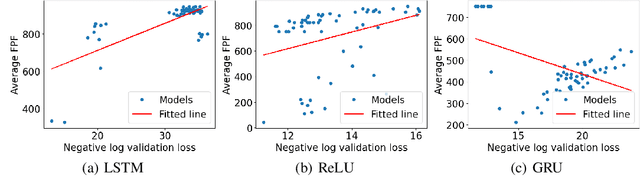

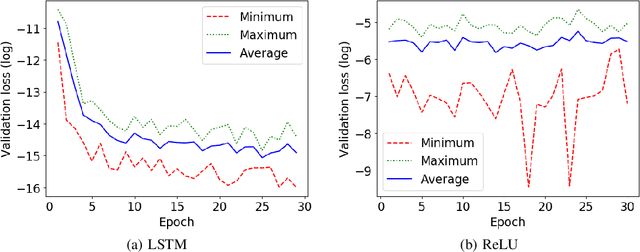
In this study, we investigate the generalization of LSTM, ReLU and GRU models on counting tasks over long sequences. Previous theoretical work has established that RNNs with ReLU activation and LSTMs have the capacity for counting with suitable configuration, while GRUs have limitations that prevent correct counting over longer sequences. Despite this and some positive empirical results for LSTMs on Dyck-1 languages, our experimental results show that LSTMs fail to learn correct counting behavior for sequences that are significantly longer than in the training data. ReLUs show much larger variance in behavior and in most cases worse generalization. The long sequence generalization is empirically related to validation loss, but reliable long sequence generalization seems not practically achievable through backpropagation with current techniques. We demonstrate different failure modes for LSTMs, GRUs and ReLUs. In particular, we observe that the saturation of activation functions in LSTMs and the correct weight setting for ReLUs to generalize counting behavior are not achieved in standard training regimens. In summary, learning generalizable counting behavior is still an open problem and we discuss potential approaches for further research.
Learning Speech Emotion Representations in the Quaternion Domain
Apr 05, 2022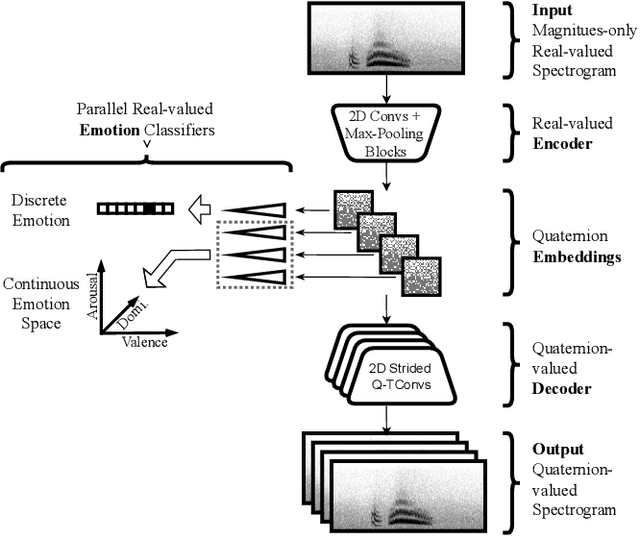
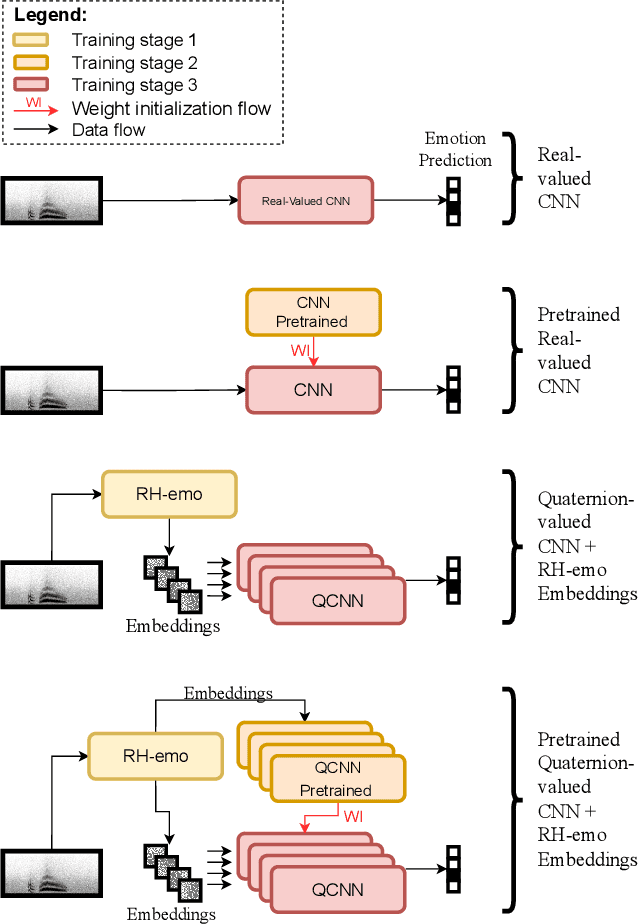
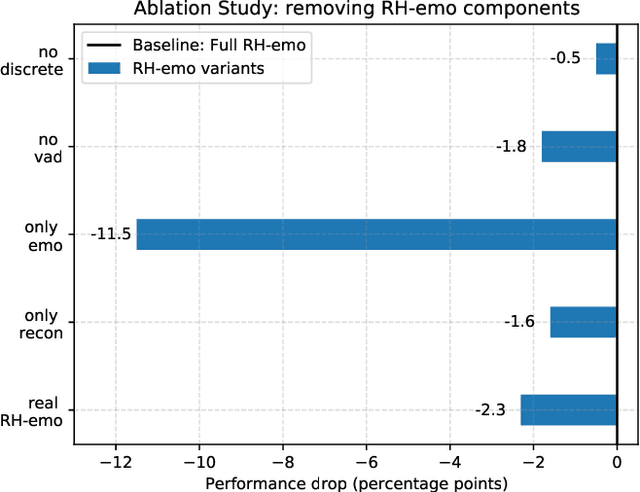
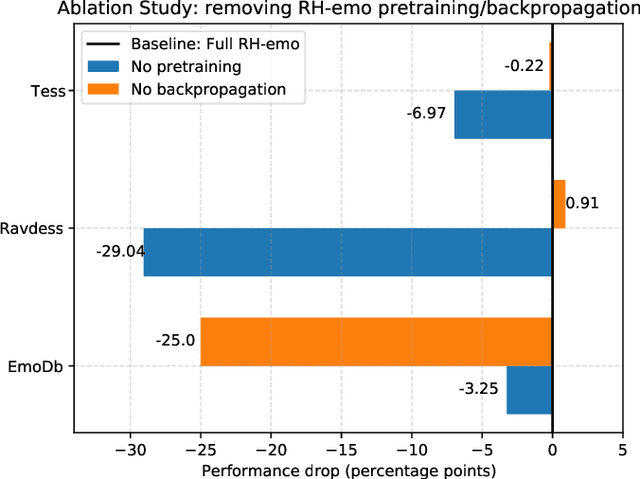
The modeling of human emotion expression in speech signals is an important, yet challenging task. The high resource demand of speech emotion recognition models, combined with the the general scarcity of emotion-labelled data are obstacles to the development and application of effective solutions in this field. In this paper, we present an approach to jointly circumvent these difficulties. Our method, named RH-emo, is a novel semi-supervised architecture aimed at extracting quaternion embeddings from real-valued monoaural spectrograms, enabling the use of quaternion-valued networks for speech emotion recognition tasks. RH-emo is a hybrid real/quaternion autoencoder network that consists of a real-valued encoder in parallel to a real-valued emotion classifier and a quaternion-valued decoder. On the one hand, the classifier permits to optimize each latent axis of the embeddings for the classification of a specific emotion-related characteristic: valence, arousal, dominance and overall emotion. On the other hand, the quaternion reconstruction enables the latent dimension to develop intra-channel correlations that are required for an effective representation as a quaternion entity. We test our approach on speech emotion recognition tasks using four popular datasets: Iemocap, Ravdess, EmoDb and Tess, comparing the performance of three well-established real-valued CNN architectures (AlexNet, ResNet-50, VGG) and their quaternion-valued equivalent fed with the embeddings created with RH-emo. We obtain a consistent improvement in the test accuracy for all datasets, while drastically reducing the resources' demand of models. Moreover, we performed additional experiments and ablation studies that confirm the effectiveness of our approach. The RH-emo repository is available at: https://github.com/ispamm/rhemo.
Evaluation of Fake News Detection with Knowledge-Enhanced Language Models
Apr 01, 2022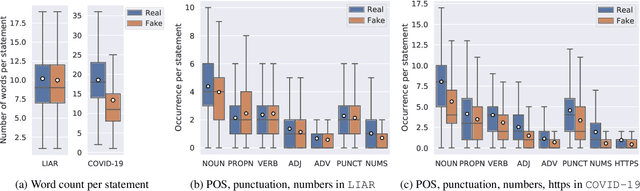
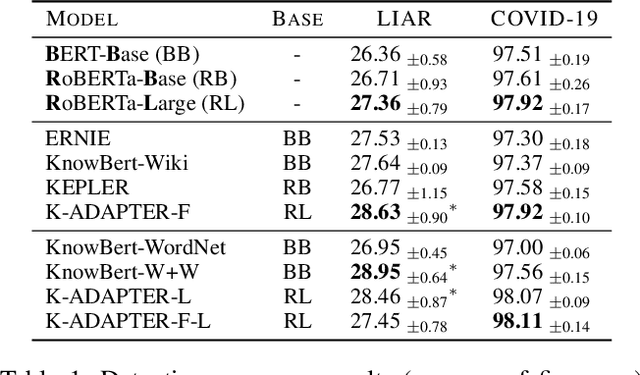
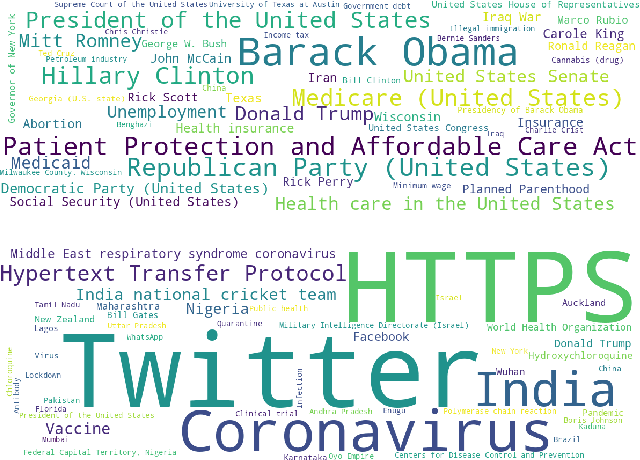
Recent advances in fake news detection have exploited the success of large-scale pre-trained language models (PLMs). The predominant state-of-the-art approaches are based on fine-tuning PLMs on labelled fake news datasets. However, large-scale PLMs are generally not trained on structured factual data and hence may not possess priors that are grounded in factually accurate knowledge. The use of existing knowledge bases (KBs) with rich human-curated factual information has thus the potential to make fake news detection more effective and robust. In this paper, we investigate the impact of knowledge integration into PLMs for fake news detection. We study several state-of-the-art approaches for knowledge integration, mostly using Wikidata as KB, on two popular fake news datasets - LIAR, a politics-based dataset, and COVID-19, a dataset of messages posted on social media relating to the COVID-19 pandemic. Our experiments show that knowledge-enhanced models can significantly improve fake news detection on LIAR where the KB is relevant and up-to-date. The mixed results on COVID-19 highlight the reliance on stylistic features and the importance of domain specific and current KBs.
Learned complex masks for multi-instrument source separation
Mar 23, 2021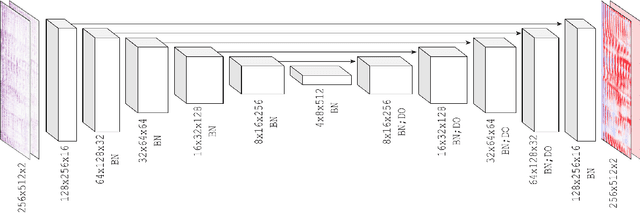
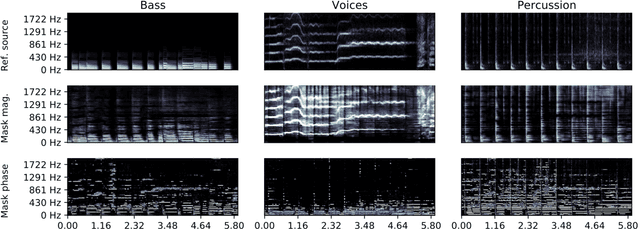
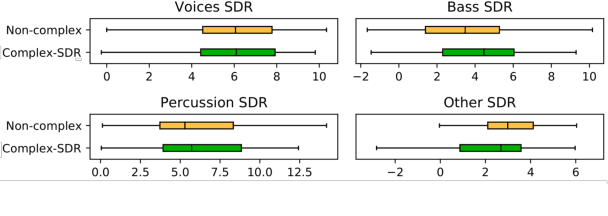
Music source separation in the time-frequency domain is commonly achieved by applying a soft or binary mask to the magnitude component of (complex) spectrograms. The phase component is usually not estimated, but instead copied from the mixture and applied to the magnitudes of the estimated isolated sources. While this method has several practical advantages, it imposes an upper bound on the performance of the system, where the estimated isolated sources inherently exhibit audible "phase artifacts". In this paper we address these shortcomings by directly estimating masks in the complex domain, extending recent work from the speech enhancement literature. The method is particularly well suited for multi-instrument musical source separation since residual phase artifacts are more pronounced for spectrally overlapping instrument sources, a common scenario in music. We show that complex masks result in better separation than masks that operate solely on the magnitude component.
Relational Weight Priors in Neural Networks for Abstract Pattern Learning and Language Modelling
Mar 10, 2021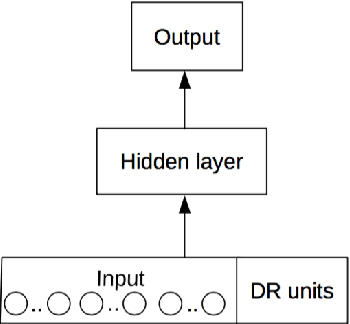
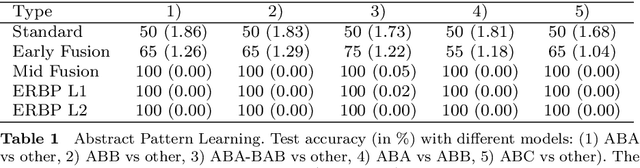
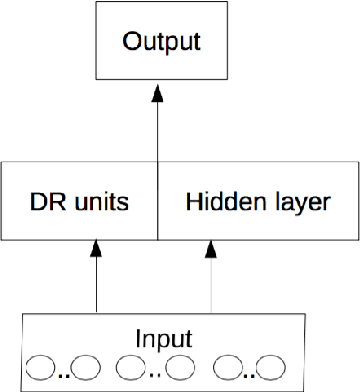
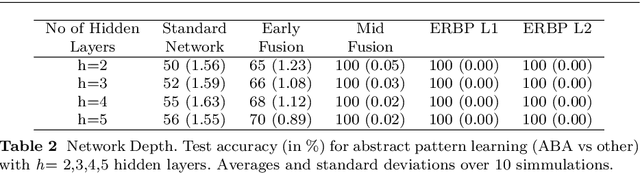
Deep neural networks have become the dominant approach in natural language processing (NLP). However, in recent years, it has become apparent that there are shortcomings in systematicity that limit the performance and data efficiency of deep learning in NLP. These shortcomings can be clearly shown in lower-level artificial tasks, mostly on synthetic data. Abstract patterns are the best known examples of a hard problem for neural networks in terms of generalisation to unseen data. They are defined by relations between items, such as equality, rather than their values. It has been argued that these low-level problems demonstrate the inability of neural networks to learn systematically. In this study, we propose Embedded Relation Based Patterns (ERBP) as a novel way to create a relational inductive bias that encourages learning equality and distance-based relations for abstract patterns. ERBP is based on Relation Based Patterns (RBP), but modelled as a Bayesian prior on network weights and implemented as a regularisation term in otherwise standard network learning. ERBP is is easy to integrate into standard neural networks and does not affect their learning capacity. In our experiments, ERBP priors lead to almost perfect generalisation when learning abstract patterns from synthetic noise-free sequences. ERBP also improves natural language models on the word and character level and pitch prediction in melodies with RNN, GRU and LSTM networks. We also find improvements in in the more complex tasks of learning of graph edit distance and compositional sentence entailment. ERBP consistently improves over RBP and over standard networks, showing that it enables abstract pattern learning which contributes to performance in natural language tasks.
Blissful Ignorance: Anti-Transfer Learning for Task Invariance
Jun 11, 2020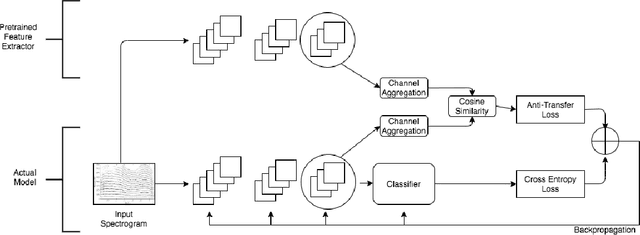

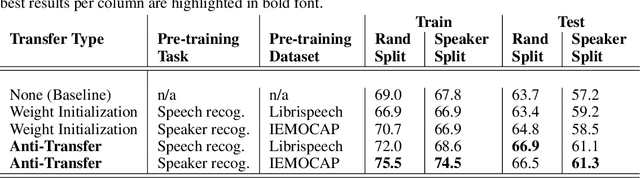
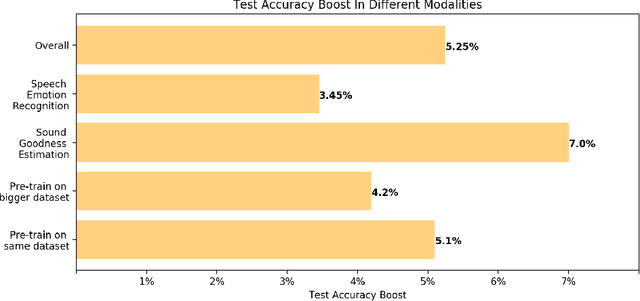
We introduce the novel concept of anti-transfer learning for neural networks. While standard transfer learning assumes that the representations learned in one task will be useful for another task, anti-transfer learning avoids learning representations that have been learned for a different task, which is not relevant and potentially misleading for the new task and should be ignored. Examples of such tasks are style vs content recognition or pitch vs timbre from audio. By penalizing similarity between the second network and the previously learned features, co-incidental correlations between the target and the unrelated task can be avoided, yielding more reliable representations and better performance on the target task. We implemented anti-transfer learning with different similarity metrics and aggregation functions. We evaluate the approach in the audio domain with different tasks and setups, using four datasets in total. The results show that anti-transfer learning consistently improves accuracy in all test cases, proving that it can push the network to learn more representative features for the task at hand.