 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToshiaki Koike-Akino
TI2V-Zero: Zero-Shot Image Conditioning for Text-to-Video Diffusion Models
Apr 25, 2024
Text-conditioned image-to-video generation (TI2V) aims to synthesize a realistic video starting from a given image (e.g., a woman's photo) and a text description (e.g., "a woman is drinking water."). Existing TI2V frameworks often require costly training on video-text datasets and specific model designs for text and image conditioning. In this paper, we propose TI2V-Zero, a zero-shot, tuning-free method that empowers a pretrained text-to-video (T2V) diffusion model to be conditioned on a provided image, enabling TI2V generation without any optimization, fine-tuning, or introducing external modules. Our approach leverages a pretrained T2V diffusion foundation model as the generative prior. To guide video generation with the additional image input, we propose a "repeat-and-slide" strategy that modulates the reverse denoising process, allowing the frozen diffusion model to synthesize a video frame-by-frame starting from the provided image. To ensure temporal continuity, we employ a DDPM inversion strategy to initialize Gaussian noise for each newly synthesized frame and a resampling technique to help preserve visual details. We conduct comprehensive experiments on both domain-specific and open-domain datasets, where TI2V-Zero consistently outperforms a recent open-domain TI2V model. Furthermore, we show that TI2V-Zero can seamlessly extend to other tasks such as video infilling and prediction when provided with more images. Its autoregressive design also supports long video generation.
SuperLoRA: Parameter-Efficient Unified Adaptation of Multi-Layer Attention Modules
Mar 18, 2024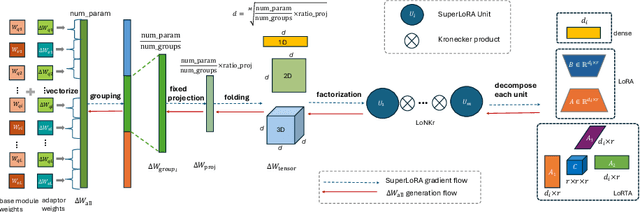
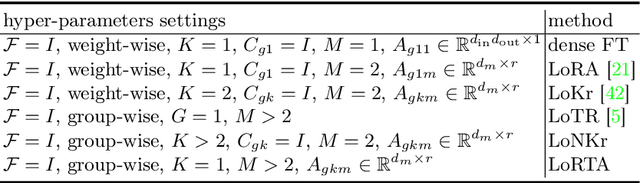
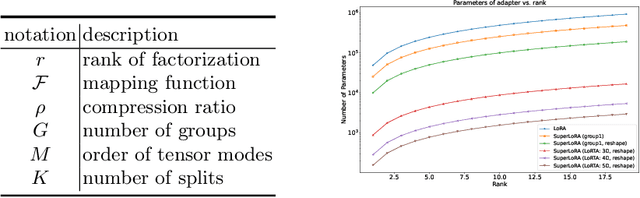
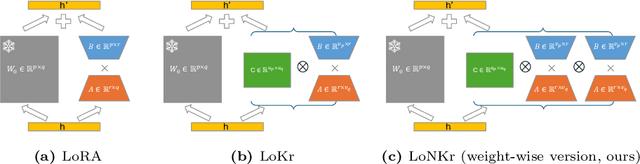
Low-rank adaptation (LoRA) and its variants are widely employed in fine-tuning large models, including large language models for natural language processing and diffusion models for computer vision. This paper proposes a generalized framework called SuperLoRA that unifies and extends different LoRA variants, which can be realized under different hyper-parameter settings. Introducing grouping, folding, shuffling, projecting, and tensor factoring, SuperLoRA offers high flexibility compared with other LoRA variants and demonstrates superior performance for transfer learning tasks especially in the extremely few-parameter regimes.
AutoHLS: Learning to Accelerate Design Space Exploration for HLS Designs
Mar 15, 2024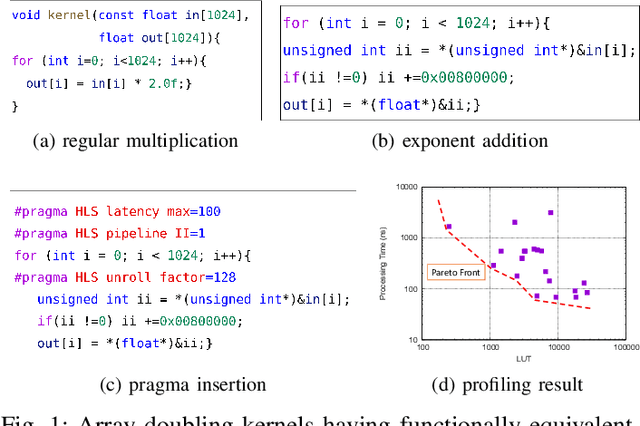

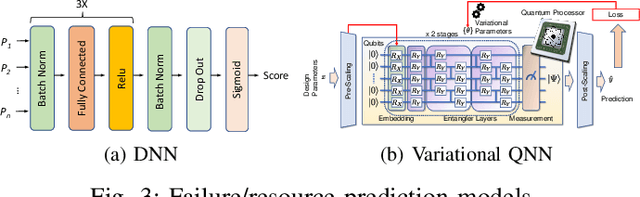
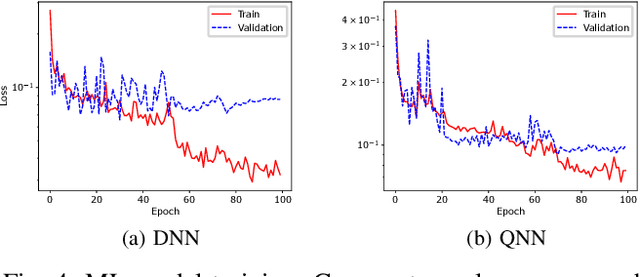
High-level synthesis (HLS) is a design flow that leverages modern language features and flexibility, such as complex data structures, inheritance, templates, etc., to prototype hardware designs rapidly. However, exploring various design space parameters can take much time and effort for hardware engineers to meet specific design specifications. This paper proposes a novel framework called AutoHLS, which integrates a deep neural network (DNN) with Bayesian optimization (BO) to accelerate HLS hardware design optimization. Our tool focuses on HLS pragma exploration and operation transformation. It utilizes integrated DNNs to predict synthesizability within a given FPGA resource budget. We also investigate the potential of emerging quantum neural networks (QNNs) instead of classical DNNs for the AutoHLS pipeline. Our experimental results demonstrate up to a 70-fold speedup in exploration time.
Why Does Differential Privacy with Large Epsilon Defend Against Practical Membership Inference Attacks?
Feb 14, 2024For small privacy parameter $\epsilon$, $\epsilon$-differential privacy (DP) provides a strong worst-case guarantee that no membership inference attack (MIA) can succeed at determining whether a person's data was used to train a machine learning model. The guarantee of DP is worst-case because: a) it holds even if the attacker already knows the records of all but one person in the data set; and b) it holds uniformly over all data sets. In practical applications, such a worst-case guarantee may be overkill: practical attackers may lack exact knowledge of (nearly all of) the private data, and our data set might be easier to defend, in some sense, than the worst-case data set. Such considerations have motivated the industrial deployment of DP models with large privacy parameter (e.g. $\epsilon \geq 7$), and it has been observed empirically that DP with large $\epsilon$ can successfully defend against state-of-the-art MIAs. Existing DP theory cannot explain these empirical findings: e.g., the theoretical privacy guarantees of $\epsilon \geq 7$ are essentially vacuous. In this paper, we aim to close this gap between theory and practice and understand why a large DP parameter can prevent practical MIAs. To tackle this problem, we propose a new privacy notion called practical membership privacy (PMP). PMP models a practical attacker's uncertainty about the contents of the private data. The PMP parameter has a natural interpretation in terms of the success rate of a practical MIA on a given data set. We quantitatively analyze the PMP parameter of two fundamental DP mechanisms: the exponential mechanism and Gaussian mechanism. Our analysis reveals that a large DP parameter often translates into a much smaller PMP parameter, which guarantees strong privacy against practical MIAs. Using our findings, we offer principled guidance for practitioners in choosing the DP parameter.
Stabilizing Subject Transfer in EEG Classification with Divergence Estimation
Oct 12, 2023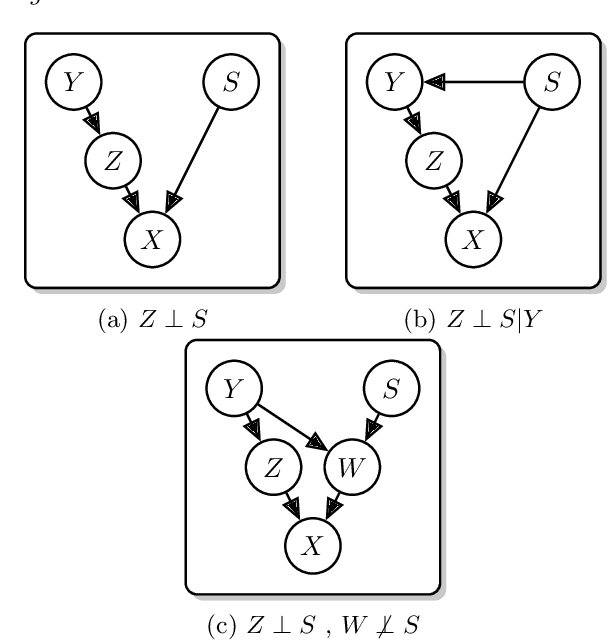

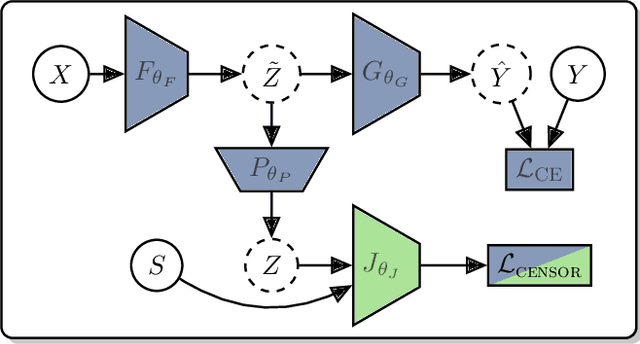
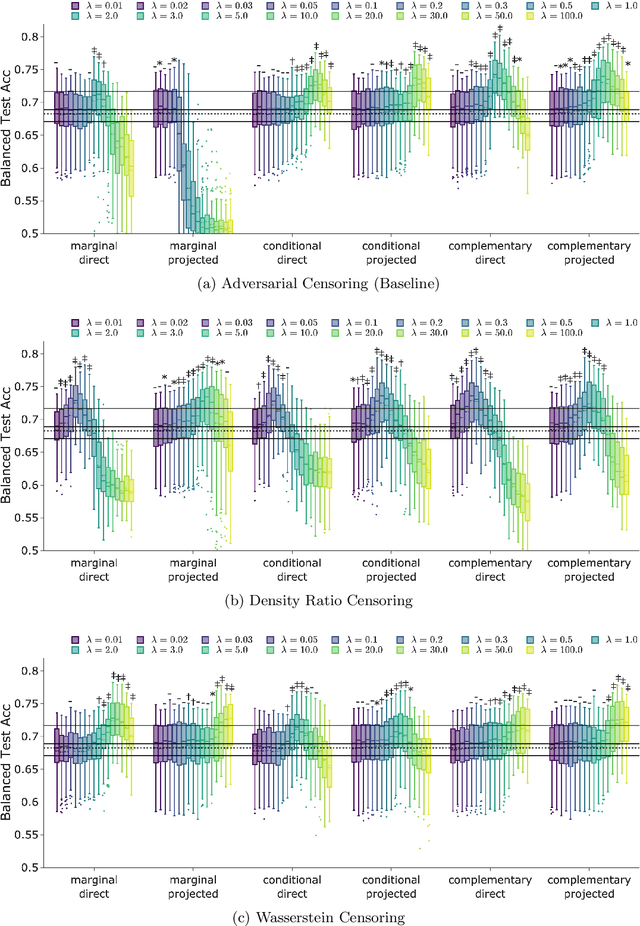
Classification models for electroencephalogram (EEG) data show a large decrease in performance when evaluated on unseen test sub jects. We reduce this performance decrease using new regularization techniques during model training. We propose several graphical models to describe an EEG classification task. From each model, we identify statistical relationships that should hold true in an idealized training scenario (with infinite data and a globally-optimal model) but that may not hold in practice. We design regularization penalties to enforce these relationships in two stages. First, we identify suitable proxy quantities (divergences such as Mutual Information and Wasserstein-1) that can be used to measure statistical independence and dependence relationships. Second, we provide algorithms to efficiently estimate these quantities during training using secondary neural network models. We conduct extensive computational experiments using a large benchmark EEG dataset, comparing our proposed techniques with a baseline method that uses an adversarial classifier. We find our proposed methods significantly increase balanced accuracy on test subjects and decrease overfitting. The proposed methods exhibit a larger benefit over a greater range of hyperparameters than the baseline method, with only a small computational cost at training time. These benefits are largest when used for a fixed training period, though there is still a significant benefit for a subset of hyperparameters when our techniques are used in conjunction with early stopping regularization.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
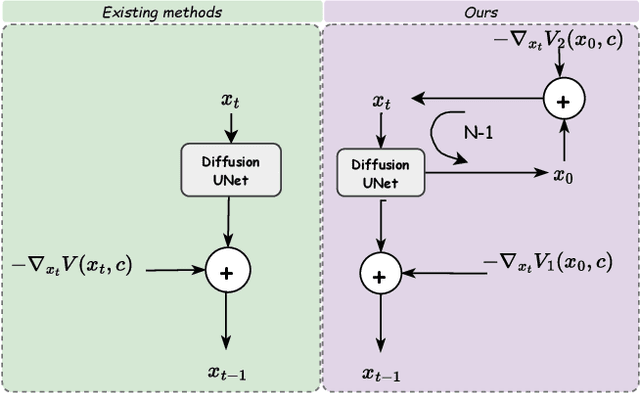
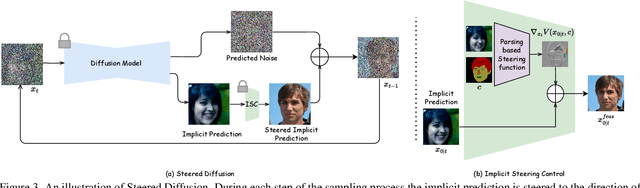
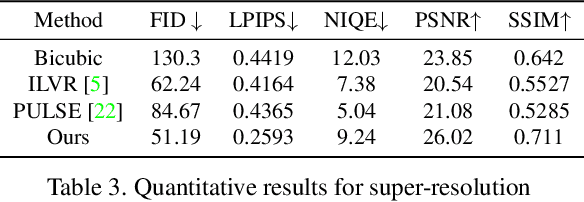
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
quEEGNet: Quantum AI for Biosignal Processing
Sep 29, 2022



In this paper, we introduce an emerging quantum machine learning (QML) framework to assist classical deep learning methods for biosignal processing applications. Specifically, we propose a hybrid quantum-classical neural network model that integrates a variational quantum circuit (VQC) into a deep neural network (DNN) for electroencephalogram (EEG), electromyogram (EMG), and electrocorticogram (ECoG) analysis. We demonstrate that the proposed quantum neural network (QNN) achieves state-of-the-art performance while the number of trainable parameters is kept small for VQC.
Adversarial Bi-Regressor Network for Domain Adaptive Regression
Sep 20, 2022
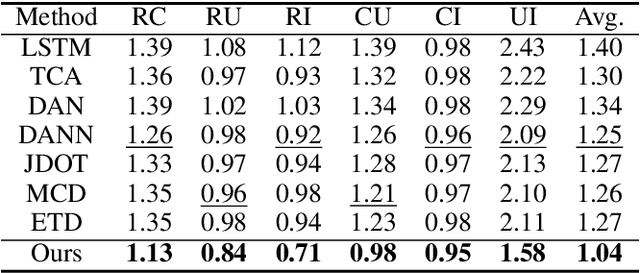
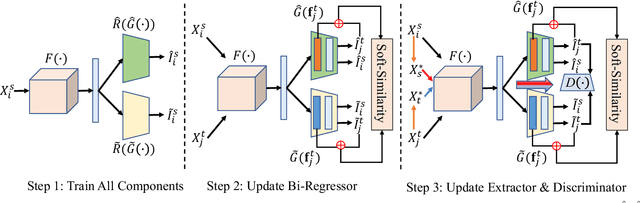
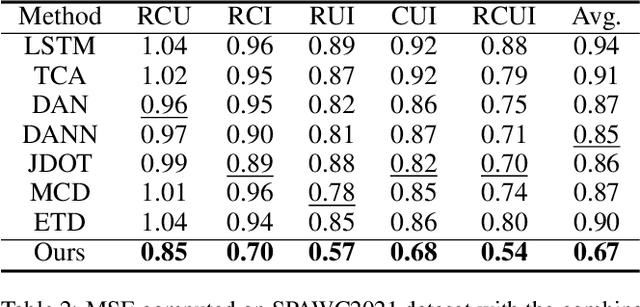
Domain adaptation (DA) aims to transfer the knowledge of a well-labeled source domain to facilitate unlabeled target learning. When turning to specific tasks such as indoor (Wi-Fi) localization, it is essential to learn a cross-domain regressor to mitigate the domain shift. This paper proposes a novel method Adversarial Bi-Regressor Network (ABRNet) to seek more effective cross-domain regression model. Specifically, a discrepant bi-regressor architecture is developed to maximize the difference of bi-regressor to discover uncertain target instances far from the source distribution, and then an adversarial training mechanism is adopted between feature extractor and dual regressors to produce domain-invariant representations. To further bridge the large domain gap, a domain-specific augmentation module is designed to synthesize two source-similar and target-similar intermediate domains to gradually eliminate the original domain mismatch. The empirical studies on two cross-domain regressive benchmarks illustrate the power of our method on solving the domain adaptive regression (DAR) problem.
Quantum Feature Extraction for THz Multi-Layer Imaging
Jul 18, 2022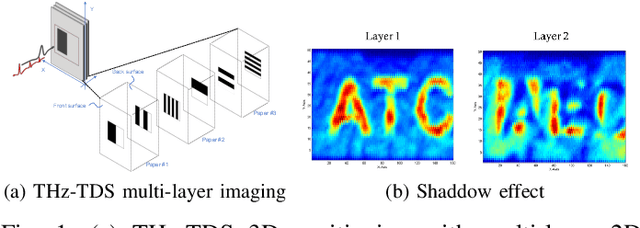
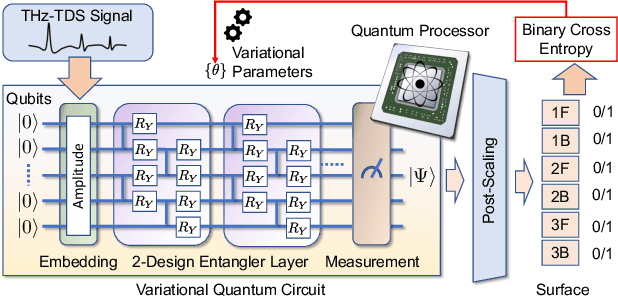

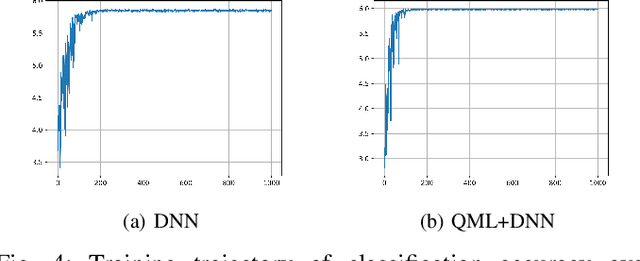
A learning-based THz multi-layer imaging has been recently used for contactless three-dimensional (3D) positioning and encoding. We show a proof-of-concept demonstration of an emerging quantum machine learning (QML) framework to deal with depth variation, shadow effect, and double-sided content recognition, through an experimental validation.
Learning to Learn Quantum Turbo Detection
May 17, 2022



This paper investigates a turbo receiver employing a variational quantum circuit (VQC). The VQC is configured with an ansatz of the quantum approximate optimization algorithm (QAOA). We propose a 'learning to learn' (L2L) framework to optimize the turbo VQC decoder such that high fidelity soft-decision output is generated. Besides demonstrating the proposed algorithm's computational complexity, we show that the L2L VQC turbo decoder can achieve an excellent performance close to the optimal maximum-likelihood performance in a multiple-input multiple-output system.