 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnoop Cherian
Multi-level Reasoning for Robotic Assembly: From Sequence Inference to Contact Selection
Dec 17, 2023
Automating the assembly of objects from their parts is a complex problem with innumerable applications in manufacturing, maintenance, and recycling. Unlike existing research, which is limited to target segmentation, pose regression, or using fixed target blueprints, our work presents a holistic multi-level framework for part assembly planning consisting of part assembly sequence inference, part motion planning, and robot contact optimization. We present the Part Assembly Sequence Transformer (PAST) -- a sequence-to-sequence neural network -- to infer assembly sequences recursively from a target blueprint. We then use a motion planner and optimization to generate part movements and contacts. To train PAST, we introduce D4PAS: a large-scale Dataset for Part Assembly Sequences (D4PAS) consisting of physically valid sequences for industrial objects. Experimental results show that our approach generalizes better than prior methods while needing significantly less computational time for inference.
Steered Diffusion: A Generalized Framework for Plug-and-Play Conditional Image Synthesis
Sep 30, 2023
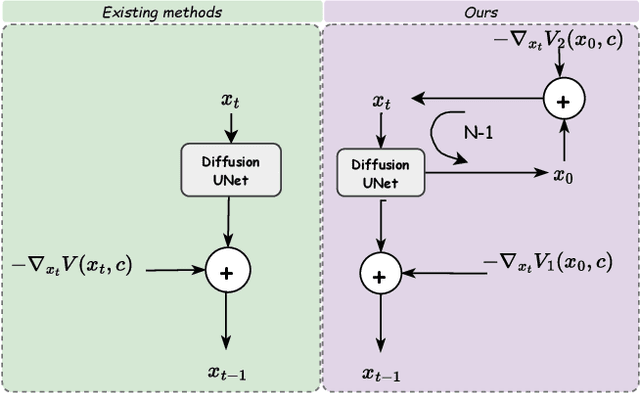
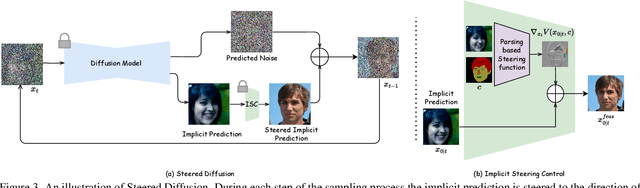
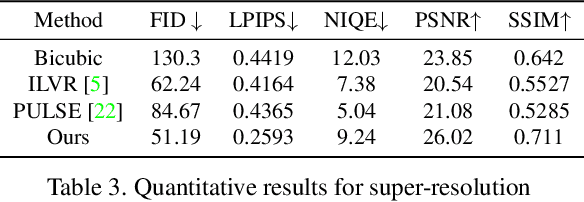
Conditional generative models typically demand large annotated training sets to achieve high-quality synthesis. As a result, there has been significant interest in designing models that perform plug-and-play generation, i.e., to use a predefined or pretrained model, which is not explicitly trained on the generative task, to guide the generative process (e.g., using language). However, such guidance is typically useful only towards synthesizing high-level semantics rather than editing fine-grained details as in image-to-image translation tasks. To this end, and capitalizing on the powerful fine-grained generative control offered by the recent diffusion-based generative models, we introduce Steered Diffusion, a generalized framework for photorealistic zero-shot conditional image generation using a diffusion model trained for unconditional generation. The key idea is to steer the image generation of the diffusion model at inference time via designing a loss using a pre-trained inverse model that characterizes the conditional task. This loss modulates the sampling trajectory of the diffusion process. Our framework allows for easy incorporation of multiple conditions during inference. We present experiments using steered diffusion on several tasks including inpainting, colorization, text-guided semantic editing, and image super-resolution. Our results demonstrate clear qualitative and quantitative improvements over state-of-the-art diffusion-based plug-and-play models while adding negligible additional computational cost.
Pixel-Grounded Prototypical Part Networks
Sep 25, 2023Prototypical part neural networks (ProtoPartNNs), namely PROTOPNET and its derivatives, are an intrinsically interpretable approach to machine learning. Their prototype learning scheme enables intuitive explanations of the form, this (prototype) looks like that (testing image patch). But, does this actually look like that? In this work, we delve into why object part localization and associated heat maps in past work are misleading. Rather than localizing to object parts, existing ProtoPartNNs localize to the entire image, contrary to generated explanatory visualizations. We argue that detraction from these underlying issues is due to the alluring nature of visualizations and an over-reliance on intuition. To alleviate these issues, we devise new receptive field-based architectural constraints for meaningful localization and a principled pixel space mapping for ProtoPartNNs. To improve interpretability, we propose additional architectural improvements, including a simplified classification head. We also make additional corrections to PROTOPNET and its derivatives, such as the use of a validation set, rather than a test set, to evaluate generalization during training. Our approach, PIXPNET (Pixel-grounded Prototypical part Network), is the only ProtoPartNN that truly learns and localizes to prototypical object parts. We demonstrate that PIXPNET achieves quantifiably improved interpretability without sacrificing accuracy.
Active Sparse Conversations for Improved Audio-Visual Embodied Navigation
Jun 06, 2023

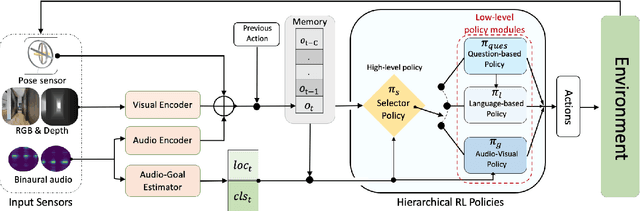
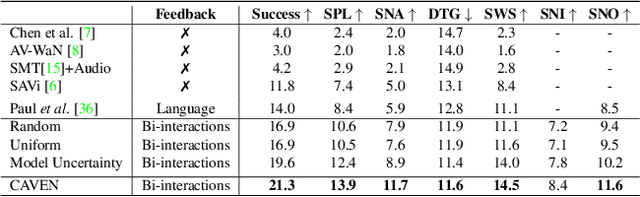
Efficient navigation towards an audio-goal necessitates an embodied agent to not only possess the ability to use audio-visual cues effectively, but also be equipped to actively (but occasionally) seek human/oracle assistance without sacrificing autonomy, e.g., when it is uncertain of where to navigate towards locating a noisy or sporadic audio goal. To this end, we present CAVEN -- a conversational audio-visual embodied navigation agent that is capable of posing navigation questions to a human/oracle and processing the oracle responses; both in free-form natural language. At the core of CAVEN is a multimodal hierarchical reinforcement learning (RL) setup that is equipped with a high-level policy that is trained to choose from one of three low-level policies (at every step), namely: (i) to navigate using audio-visual cues, or (ii) to frame a question to the oracle and receive a short or detailed response, or (iii) ask generic questions (when unsure of what to ask) and receive instructions. Key to generating the agent's questions is our novel TrajectoryNet that forecasts the most likely next steps to the goal and a QuestionNet that uses these steps to produce a question. All the policies are learned end-to-end via the RL setup, with penalties to enforce sparsity in receiving navigation instructions from the oracle. To evaluate the performance of CAVEN, we present extensive experiments on the SoundSpaces framework for the task of semantic audio-visual navigation. Our results show that CAVEN achieves upto 12% gain in performance over competing methods, especially in localizing new sound sources, even in the presence of auditory distractions.
HaLP: Hallucinating Latent Positives for Skeleton-based Self-Supervised Learning of Actions
Apr 01, 2023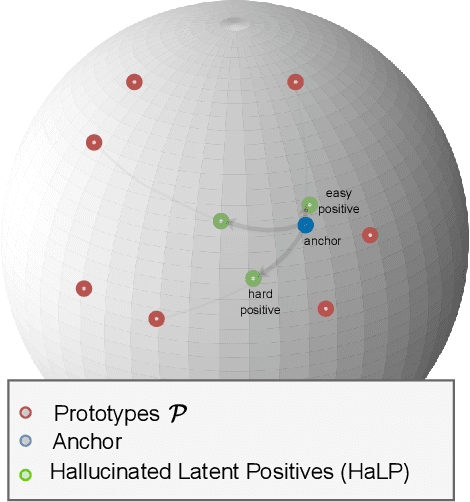

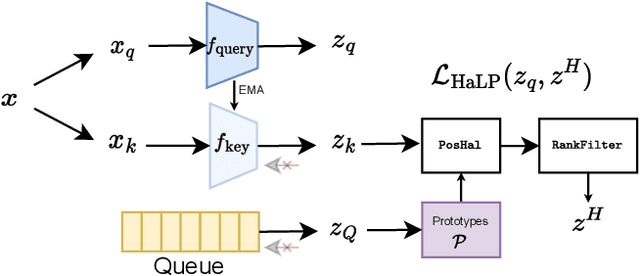
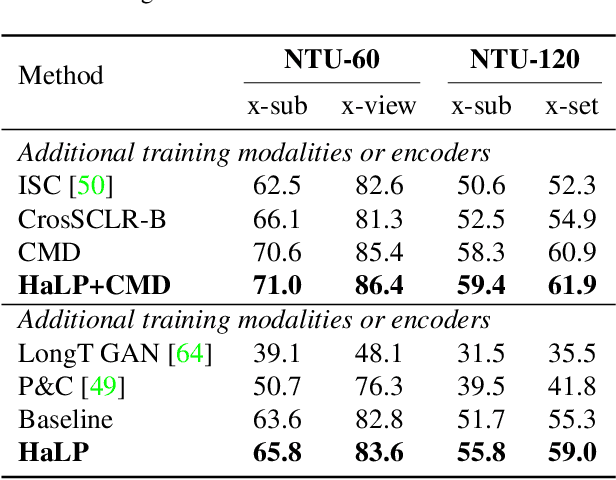
Supervised learning of skeleton sequence encoders for action recognition has received significant attention in recent times. However, learning such encoders without labels continues to be a challenging problem. While prior works have shown promising results by applying contrastive learning to pose sequences, the quality of the learned representations is often observed to be closely tied to data augmentations that are used to craft the positives. However, augmenting pose sequences is a difficult task as the geometric constraints among the skeleton joints need to be enforced to make the augmentations realistic for that action. In this work, we propose a new contrastive learning approach to train models for skeleton-based action recognition without labels. Our key contribution is a simple module, HaLP - to Hallucinate Latent Positives for contrastive learning. Specifically, HaLP explores the latent space of poses in suitable directions to generate new positives. To this end, we present a novel optimization formulation to solve for the synthetic positives with an explicit control on their hardness. We propose approximations to the objective, making them solvable in closed form with minimal overhead. We show via experiments that using these generated positives within a standard contrastive learning framework leads to consistent improvements across benchmarks such as NTU-60, NTU-120, and PKU-II on tasks like linear evaluation, transfer learning, and kNN evaluation. Our code will be made available at https://github.com/anshulbshah/HaLP.
Aligning Step-by-Step Instructional Diagrams to Video Demonstrations
Mar 27, 2023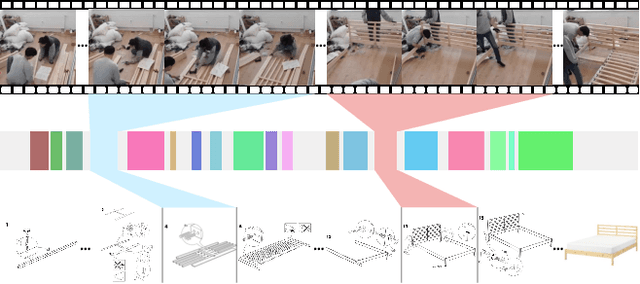
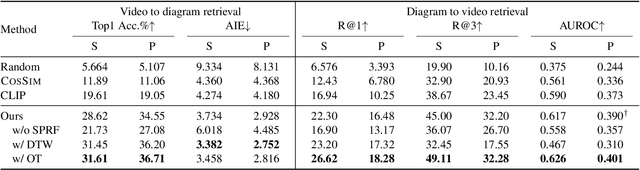
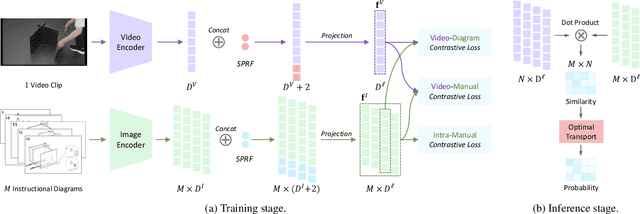
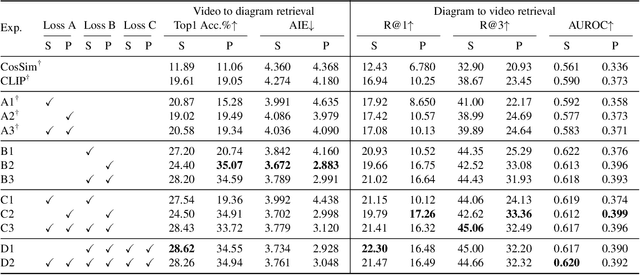
Multimodal alignment facilitates the retrieval of instances from one modality when queried using another. In this paper, we consider a novel setting where such an alignment is between (i) instruction steps that are depicted as assembly diagrams (commonly seen in Ikea assembly manuals) and (ii) video segments from in-the-wild videos; these videos comprising an enactment of the assembly actions in the real world. To learn this alignment, we introduce a novel supervised contrastive learning method that learns to align videos with the subtle details in the assembly diagrams, guided by a set of novel losses. To study this problem and demonstrate the effectiveness of our method, we introduce a novel dataset: IAW for Ikea assembly in the wild consisting of 183 hours of videos from diverse furniture assembly collections and nearly 8,300 illustrations from their associated instruction manuals and annotated for their ground truth alignments. We define two tasks on this dataset: First, nearest neighbor retrieval between video segments and illustrations, and, second, alignment of instruction steps and the segments for each video. Extensive experiments on IAW demonstrate superior performances of our approach against alternatives.
Are Deep Neural Networks SMARTer than Second Graders?
Jan 05, 2023
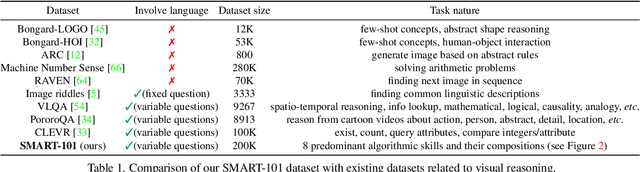
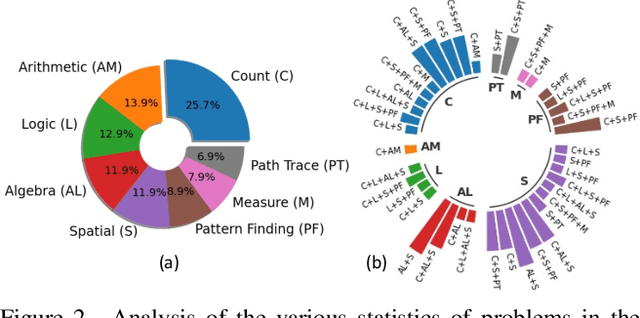
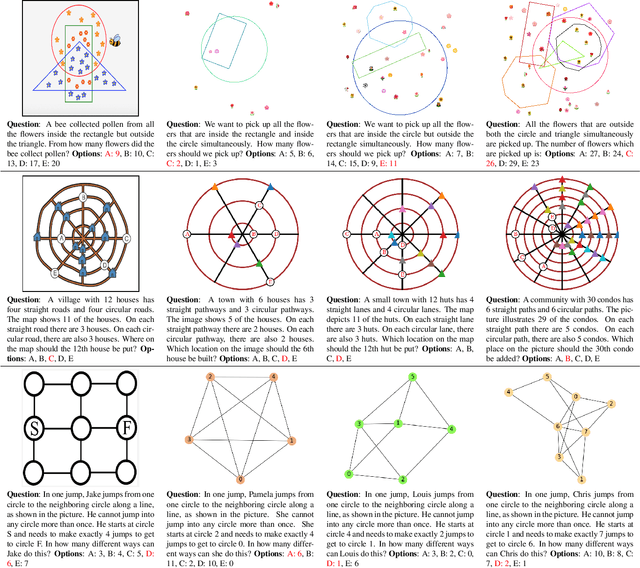
Recent times have witnessed an increasing number of applications of deep neural networks towards solving tasks that require superior cognitive abilities, e.g., playing Go, generating art, question answering (such as ChatGPT), etc. Such a dramatic progress raises the question: how generalizable are neural networks in solving problems that demand broad skills? To answer this question, we propose SMART: a Simple Multimodal Algorithmic Reasoning Task and the associated SMART-101 dataset, for evaluating the abstraction, deduction, and generalization abilities of neural networks in solving visuo-linguistic puzzles designed specifically for children in the 6-8 age group. Our dataset consists of 101 unique puzzles; each puzzle comprises a picture and a question, and their solution needs a mix of several elementary skills, including arithmetic, algebra, and spatial reasoning, among others. To scale our dataset towards training deep neural networks, we programmatically generate entirely new instances for each puzzle while retaining their solution algorithm. To benchmark the performance on the SMART-101 dataset, we propose a vision and language meta-learning model using varied state-of-the-art backbone neural networks. Our experiments reveal that while powerful deep models offer reasonable performances on puzzles that they are trained on, they are not better than random accuracy when analyzed for generalization. We also evaluate the recent ChatGPT large language model on a subset of our dataset and find that while ChatGPT produces convincing reasoning abilities, the answers are often incorrect.
Learning Audio-Visual Dynamics Using Scene Graphs for Audio Source Separation
Oct 29, 2022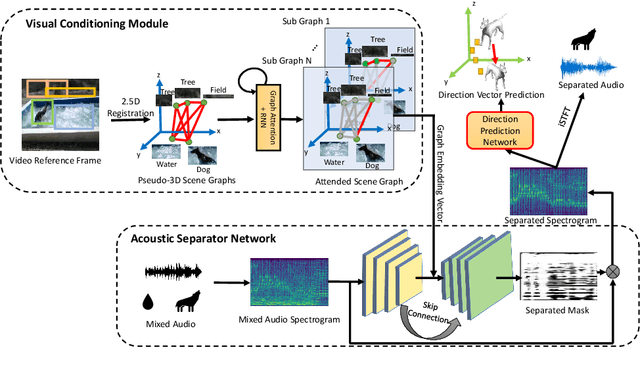
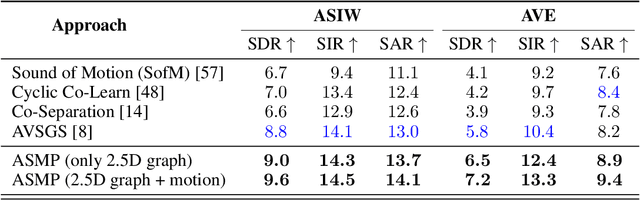
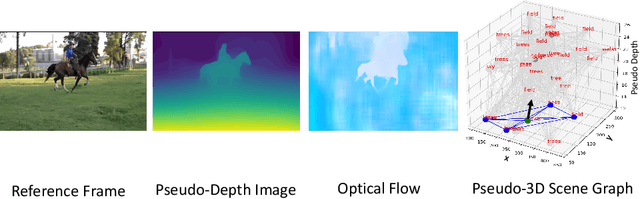
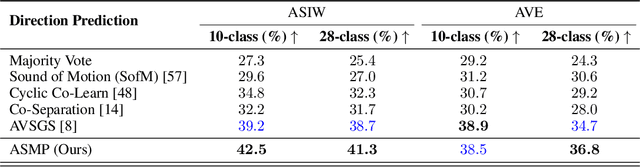
There exists an unequivocal distinction between the sound produced by a static source and that produced by a moving one, especially when the source moves towards or away from the microphone. In this paper, we propose to use this connection between audio and visual dynamics for solving two challenging tasks simultaneously, namely: (i) separating audio sources from a mixture using visual cues, and (ii) predicting the 3D visual motion of a sounding source using its separated audio. Towards this end, we present Audio Separator and Motion Predictor (ASMP) -- a deep learning framework that leverages the 3D structure of the scene and the motion of sound sources for better audio source separation. At the heart of ASMP is a 2.5D scene graph capturing various objects in the video and their pseudo-3D spatial proximities. This graph is constructed by registering together 2.5D monocular depth predictions from the 2D video frames and associating the 2.5D scene regions with the outputs of an object detector applied on those frames. The ASMP task is then mathematically modeled as the joint problem of: (i) recursively segmenting the 2.5D scene graph into several sub-graphs, each associated with a constituent sound in the input audio mixture (which is then separated) and (ii) predicting the 3D motions of the corresponding sound sources from the separated audio. To empirically evaluate ASMP, we present experiments on two challenging audio-visual datasets, viz. Audio Separation in the Wild (ASIW) and Audio Visual Event (AVE). Our results demonstrate that ASMP achieves a clear improvement in source separation quality, outperforming prior works on both datasets, while also estimating the direction of motion of the sound sources better than other methods.
H-SAUR: Hypothesize, Simulate, Act, Update, and Repeat for Understanding Object Articulations from Interactions
Oct 22, 2022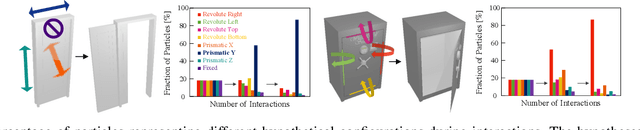

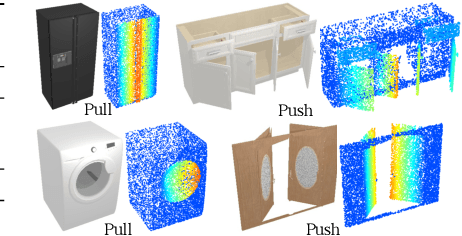
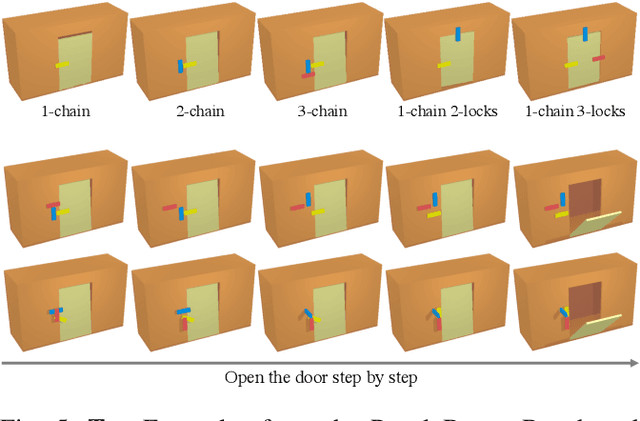
The world is filled with articulated objects that are difficult to determine how to use from vision alone, e.g., a door might open inwards or outwards. Humans handle these objects with strategic trial-and-error: first pushing a door then pulling if that doesn't work. We enable these capabilities in autonomous agents by proposing "Hypothesize, Simulate, Act, Update, and Repeat" (H-SAUR), a probabilistic generative framework that simultaneously generates a distribution of hypotheses about how objects articulate given input observations, captures certainty over hypotheses over time, and infer plausible actions for exploration and goal-conditioned manipulation. We compare our model with existing work in manipulating objects after a handful of exploration actions, on the PartNet-Mobility dataset. We further propose a novel PuzzleBoxes benchmark that contains locked boxes that require multiple steps to solve. We show that the proposed model significantly outperforms the current state-of-the-art articulated object manipulation framework, despite using zero training data. We further improve the test-time efficiency of H-SAUR by integrating a learned prior from learning-based vision models.
AVLEN: Audio-Visual-Language Embodied Navigation in 3D Environments
Oct 14, 2022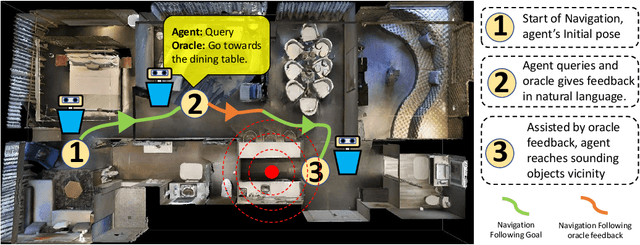
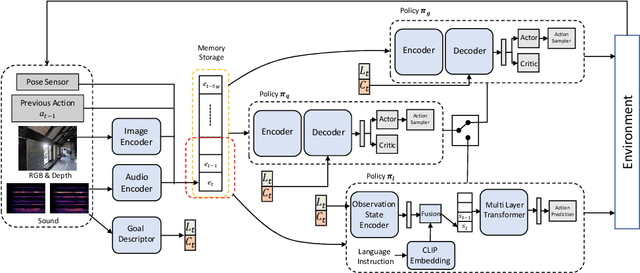
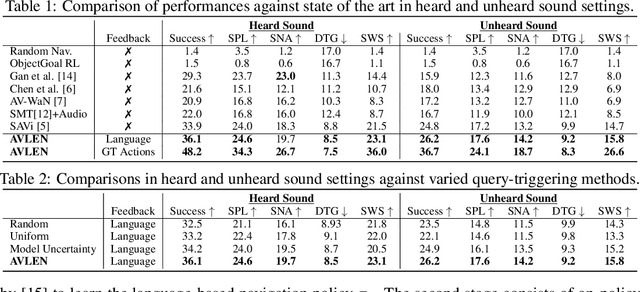

Recent years have seen embodied visual navigation advance in two distinct directions: (i) in equipping the AI agent to follow natural language instructions, and (ii) in making the navigable world multimodal, e.g., audio-visual navigation. However, the real world is not only multimodal, but also often complex, and thus in spite of these advances, agents still need to understand the uncertainty in their actions and seek instructions to navigate. To this end, we present AVLEN~ -- an interactive agent for Audio-Visual-Language Embodied Navigation. Similar to audio-visual navigation tasks, the goal of our embodied agent is to localize an audio event via navigating the 3D visual world; however, the agent may also seek help from a human (oracle), where the assistance is provided in free-form natural language. To realize these abilities, AVLEN uses a multimodal hierarchical reinforcement learning backbone that learns: (a) high-level policies to choose either audio-cues for navigation or to query the oracle, and (b) lower-level policies to select navigation actions based on its audio-visual and language inputs. The policies are trained via rewarding for the success on the navigation task while minimizing the number of queries to the oracle. To empirically evaluate AVLEN, we present experiments on the SoundSpaces framework for semantic audio-visual navigation tasks. Our results show that equipping the agent to ask for help leads to a clear improvement in performance, especially in challenging cases, e.g., when the sound is unheard during training or in the presence of distractor sounds.