 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUpamanyu Madhow
Improving Robustness via Tilted Exponential Layer: A Communication-Theoretic Perspective
Nov 02, 2023
State-of-the-art techniques for enhancing robustness of deep networks mostly rely on empirical risk minimization with suitable data augmentation. In this paper, we propose a complementary approach motivated by communication theory, aimed at enhancing the signal-to-noise ratio at the output of a neural network layer via neural competition during learning and inference. In addition to minimization of a standard end-to-end cost, neurons compete to sparsely represent layer inputs by maximization of a tilted exponential (TEXP) objective function for the layer. TEXP learning can be interpreted as maximum likelihood estimation of matched filters under a Gaussian model for data noise. Inference in a TEXP layer is accomplished by replacing batch norm by a tilted softmax, which can be interpreted as computation of posterior probabilities for the competing signaling hypotheses represented by each neuron. After providing insights via simplified models, we show, by experimentation on standard image datasets, that TEXP learning and inference enhances robustness against noise and other common corruptions, without requiring data augmentation. Further cumulative gains in robustness against this array of distortions can be obtained by appropriately combining TEXP with data augmentation techniques.
Neuro-Inspired Deep Neural Networks with Sparse, Strong Activations
Apr 12, 2022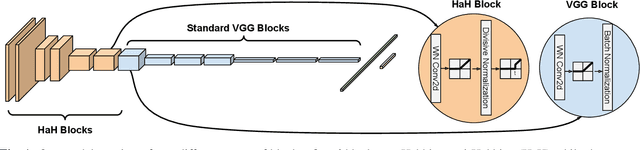

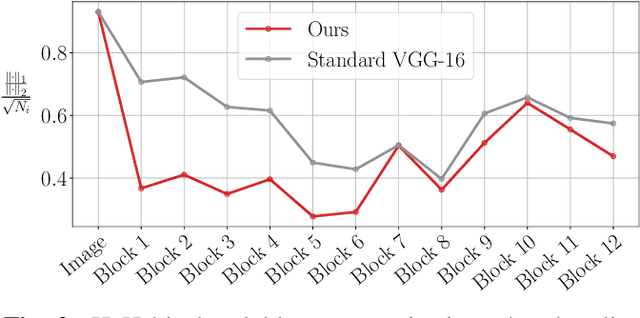
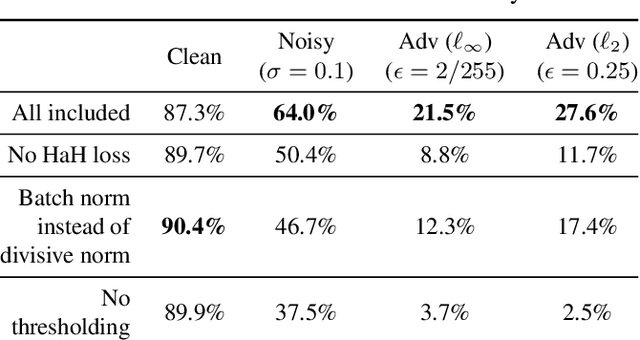
While end-to-end training of Deep Neural Networks (DNNs) yields state of the art performance in an increasing array of applications, it does not provide insight into, or control over, the features being extracted. We report here on a promising neuro-inspired approach to DNNs with sparser and stronger activations. We use standard stochastic gradient training, supplementing the end-to-end discriminative cost function with layer-wise costs promoting Hebbian ("fire together," "wire together") updates for highly active neurons, and anti-Hebbian updates for the remaining neurons. Instead of batch norm, we use divisive normalization of activations (suppressing weak outputs using strong outputs), along with implicit $\ell_2$ normalization of neuronal weights. Experiments with standard image classification tasks on CIFAR-10 demonstrate that, relative to baseline end-to-end trained architectures, our proposed architecture (a) leads to sparser activations (with only a slight compromise on accuracy), (b) exhibits more robustness to noise (without being trained on noisy data), (c) exhibits more robustness to adversarial perturbations (without adversarial training).
Self-supervised Speaker Recognition Training Using Human-Machine Dialogues
Feb 07, 2022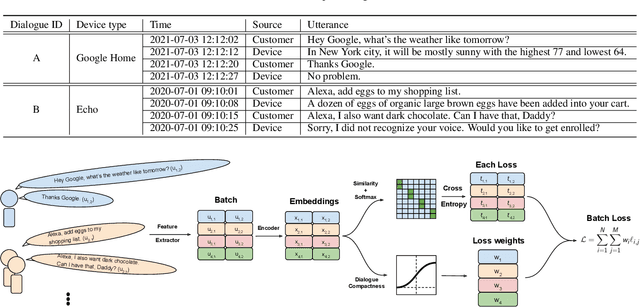
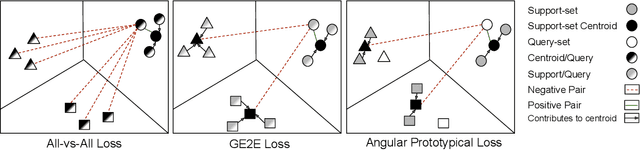
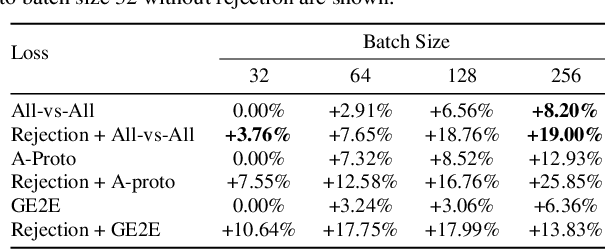
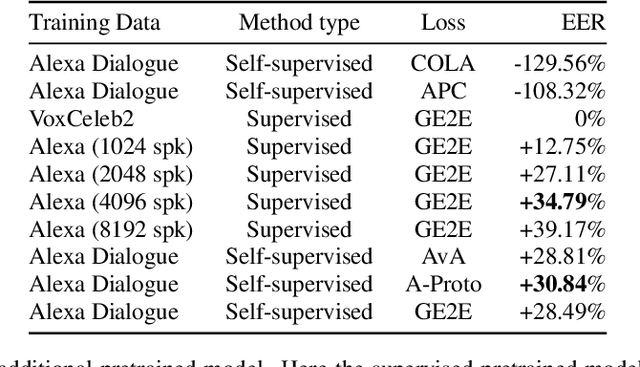
Speaker recognition, recognizing speaker identities based on voice alone, enables important downstream applications, such as personalization and authentication. Learning speaker representations, in the context of supervised learning, heavily depends on both clean and sufficient labeled data, which is always difficult to acquire. Noisy unlabeled data, on the other hand, also provides valuable information that can be exploited using self-supervised training methods. In this work, we investigate how to pretrain speaker recognition models by leveraging dialogues between customers and smart-speaker devices. However, the supervisory information in such dialogues is inherently noisy, as multiple speakers may speak to a device in the course of the same dialogue. To address this issue, we propose an effective rejection mechanism that selectively learns from dialogues based on their acoustic homogeneity. Both reconstruction-based and contrastive-learning-based self-supervised methods are compared. Experiments demonstrate that the proposed method provides significant performance improvements, superior to earlier work. Dialogue pretraining when combined with the rejection mechanism yields 27.10% equal error rate (EER) reduction in speaker recognition, compared to a model without self-supervised pretraining.
Generalized Likelihood Ratio Test for Adversarially Robust Hypothesis Testing
Dec 04, 2021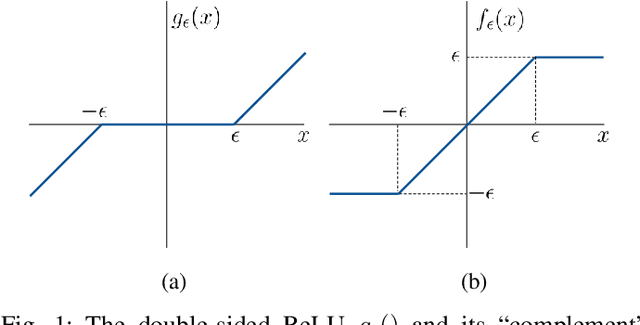
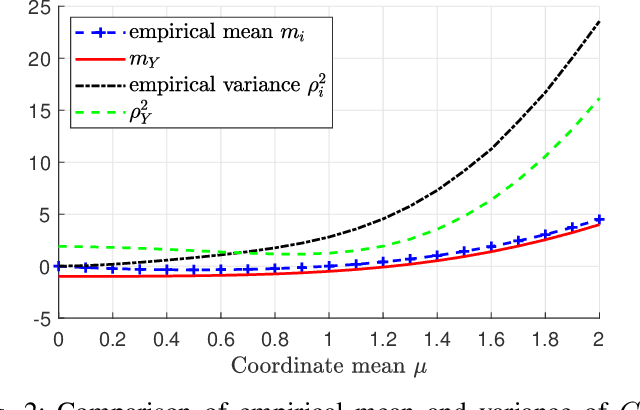
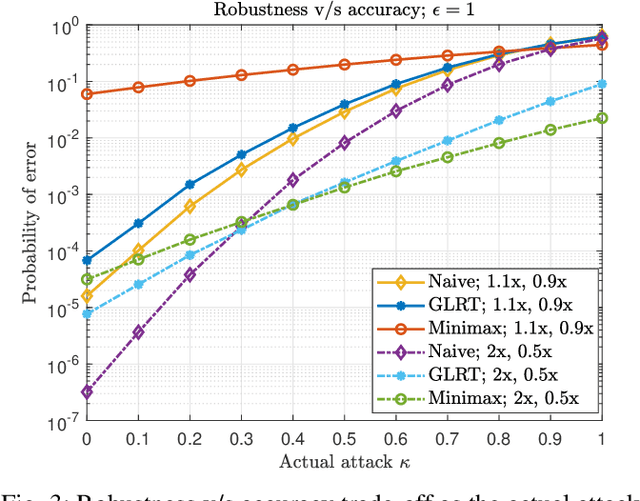
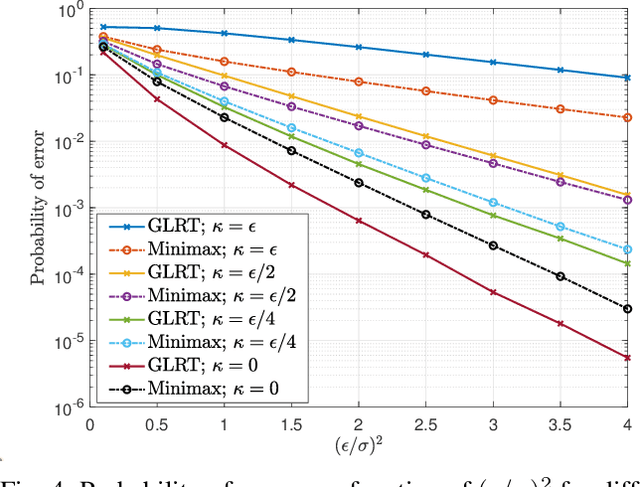
Machine learning models are known to be susceptible to adversarial attacks which can cause misclassification by introducing small but well designed perturbations. In this paper, we consider a classical hypothesis testing problem in order to develop fundamental insight into defending against such adversarial perturbations. We interpret an adversarial perturbation as a nuisance parameter, and propose a defense based on applying the generalized likelihood ratio test (GLRT) to the resulting composite hypothesis testing problem, jointly estimating the class of interest and the adversarial perturbation. While the GLRT approach is applicable to general multi-class hypothesis testing, we first evaluate it for binary hypothesis testing in white Gaussian noise under $\ell_{\infty}$ norm-bounded adversarial perturbations, for which a known minimax defense optimizing for the worst-case attack provides a benchmark. We derive the worst-case attack for the GLRT defense, and show that its asymptotic performance (as the dimension of the data increases) approaches that of the minimax defense. For non-asymptotic regimes, we show via simulations that the GLRT defense is competitive with the minimax approach under the worst-case attack, while yielding a better robustness-accuracy tradeoff under weaker attacks. We also illustrate the GLRT approach for a multi-class hypothesis testing problem, for which a minimax strategy is not known, evaluating its performance under both noise-agnostic and noise-aware adversarial settings, by providing a method to find optimal noise-aware attacks, and heuristics to find noise-agnostic attacks that are close to optimal in the high SNR regime.
All-Digital LoS MIMO with Low-Precision Analog-to-Digital Conversion
Aug 02, 2021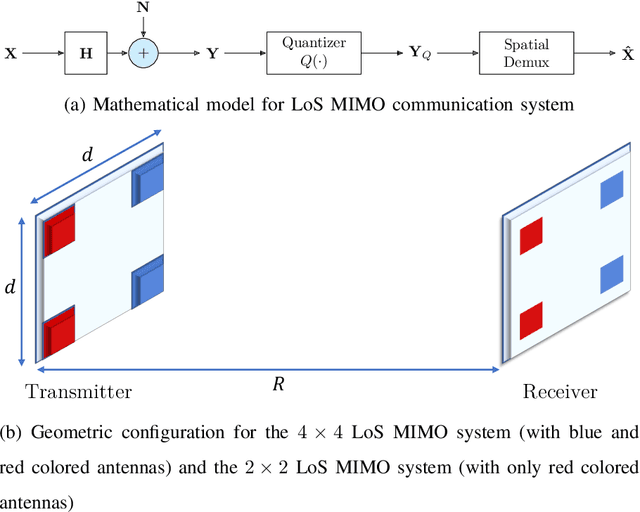
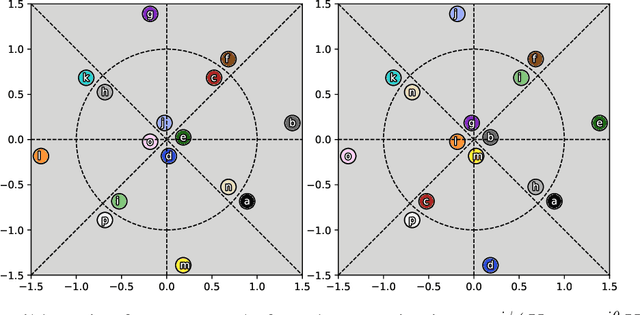
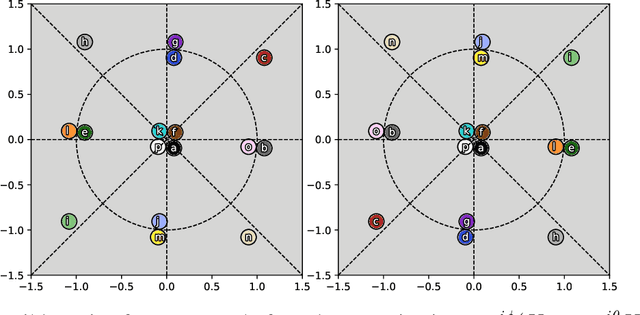
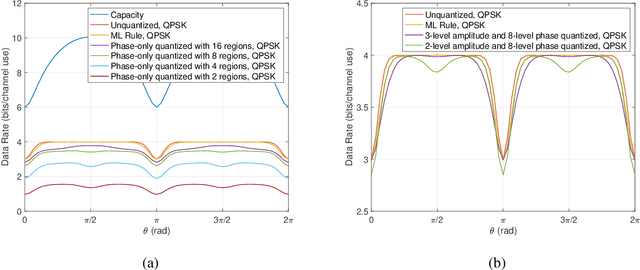
Line-of-sight (LoS) multi-input multi-output (MIMO) systems exhibit attractive scaling properties with increase in carrier frequency: for a fixed form factor and range, the spatial degrees of freedom increase quadratically for 2D arrays, in addition to the typically linear increase in available bandwidth. In this paper, we investigate whether modern all-digital baseband signal processing architectures can be devised for such regimes, given the difficulty of analog-to-digital conversion for large bandwidths. We propose low-precision quantizer designs and accompanying spatial demultiplexing algorithms, considering 2x2 LoS MIMO with QPSK for analytical insight, and 4x4 MIMO with QPSK and 16QAM for performance evaluation. Unlike prior work, channel state information is utilized only at the receiver (i.e., transmit precoding is not employed). We investigate quantizers with regular structure whose high-SNR mutual information approaches that of an unquantized system. We prove that amplitude-phase quantization is necessary to attain this benchmark; phase-only quantization falls short. We show that quantizers based on maximizing per-antenna output entropy perform better than standard Minimum Mean Squared Quantization Error (MMSQE) quantization. For spatial demultiplexing with severely quantized observations, we introduce the novel concept of virtual quantization which, combined with linear detection, provides reliable demodulation at significantly reduced complexity compared to maximum likelihood detection.
Sparse Coding Frontend for Robust Neural Networks
Apr 12, 2021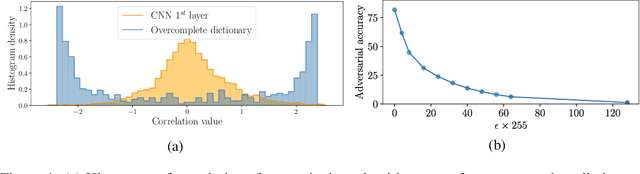

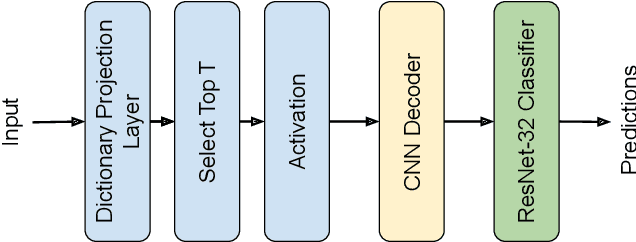
Deep Neural Networks are known to be vulnerable to small, adversarially crafted, perturbations. The current most effective defense methods against these adversarial attacks are variants of adversarial training. In this paper, we introduce a radically different defense trained only on clean images: a sparse coding based frontend which significantly attenuates adversarial attacks before they reach the classifier. We evaluate our defense on CIFAR-10 dataset under a wide range of attack types (including Linf , L2, and L1 bounded attacks), demonstrating its promise as a general-purpose approach for defense.
A Neuro-Inspired Autoencoding Defense Against Adversarial Perturbations
Dec 21, 2020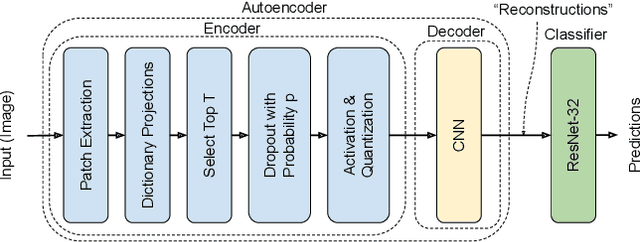

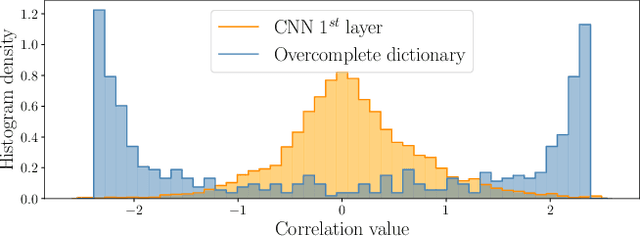
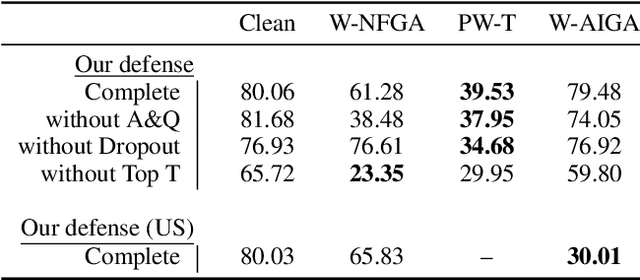
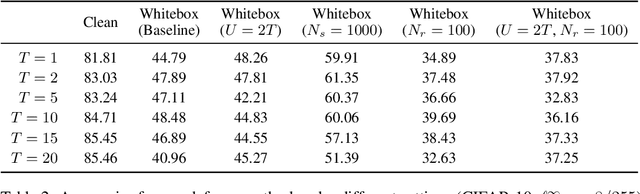
Deep Neural Networks (DNNs) are vulnerable to adversarial attacks: carefully constructed perturbations to an image can seriously impair classification accuracy, while being imperceptible to humans. While there has been a significant amount of research on defending against such attacks, most defenses based on systematic design principles have been defeated by appropriately modified attacks. For a fixed set of data, the most effective current defense is to train the network using adversarially perturbed examples. In this paper, we investigate a radically different, neuro-inspired defense mechanism, starting from the observation that human vision is virtually unaffected by adversarial examples designed for machines. We aim to reject L^inf bounded adversarial perturbations before they reach a classifier DNN, using an encoder with characteristics commonly observed in biological vision: sparse overcomplete representations, randomness due to synaptic noise, and drastic nonlinearities. Encoder training is unsupervised, using standard dictionary learning. A CNN-based decoder restores the size of the encoder output to that of the original image, enabling the use of a standard CNN for classification. Our nominal design is to train the decoder and classifier together in standard supervised fashion, but we also consider unsupervised decoder training based on a regression objective (as in a conventional autoencoder) with separate supervised training of the classifier. Unlike adversarial training, all training is based on clean images. Our experiments on the CIFAR-10 show performance competitive with state-of-the-art defenses based on adversarial training, and point to the promise of neuro-inspired techniques for the design of robust neural networks. In addition, we provide results for a subset of the Imagenet dataset to verify that our approach scales to larger images.
Adversarially Robust Classification based on GLRT
Nov 16, 2020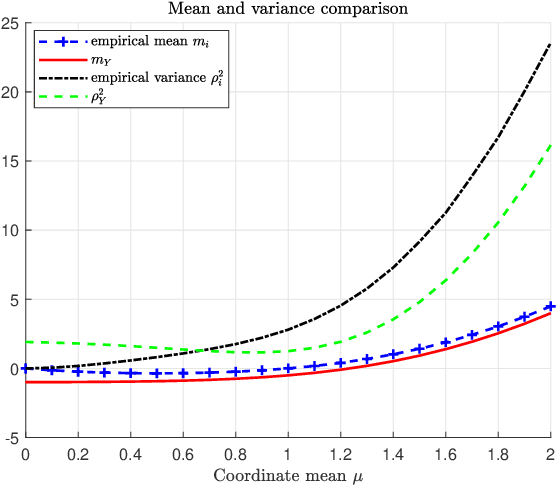
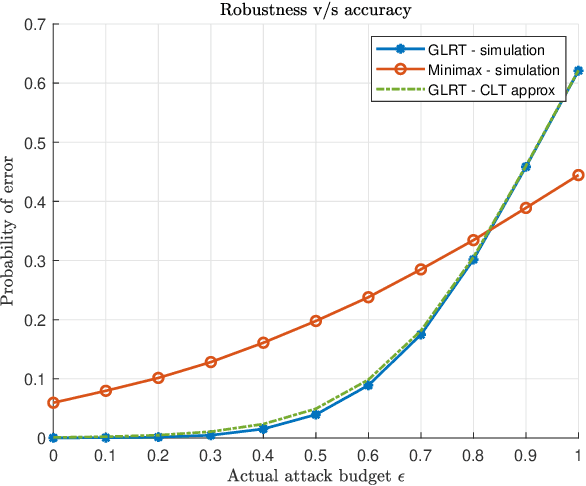
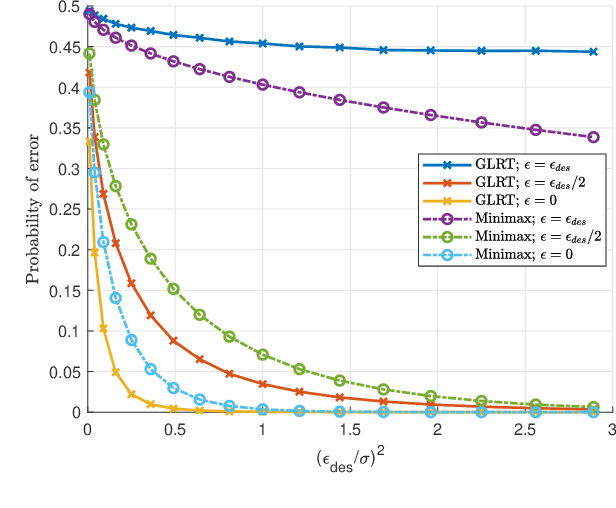
Machine learning models are vulnerable to adversarial attacks that can often cause misclassification by introducing small but well designed perturbations. In this paper, we explore, in the setting of classical composite hypothesis testing, a defense strategy based on the generalized likelihood ratio test (GLRT), which jointly estimates the class of interest and the adversarial perturbation. We evaluate the GLRT approach for the special case of binary hypothesis testing in white Gaussian noise under $\ell_{\infty}$ norm-bounded adversarial perturbations, a setting for which a minimax strategy optimizing for the worst-case attack is known. We show that the GLRT approach yields performance competitive with that of the minimax approach under the worst-case attack, and observe that it yields a better robustness-accuracy trade-off under weaker attacks, depending on the values of signal components relative to the attack budget. We also observe that the GLRT defense generalizes naturally to more complex models for which optimal minimax classifiers are not known.