 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYuguang Yang
PP-MeT: a Real-world Personalized Prompt based Meeting Transcription System
Sep 28, 2023
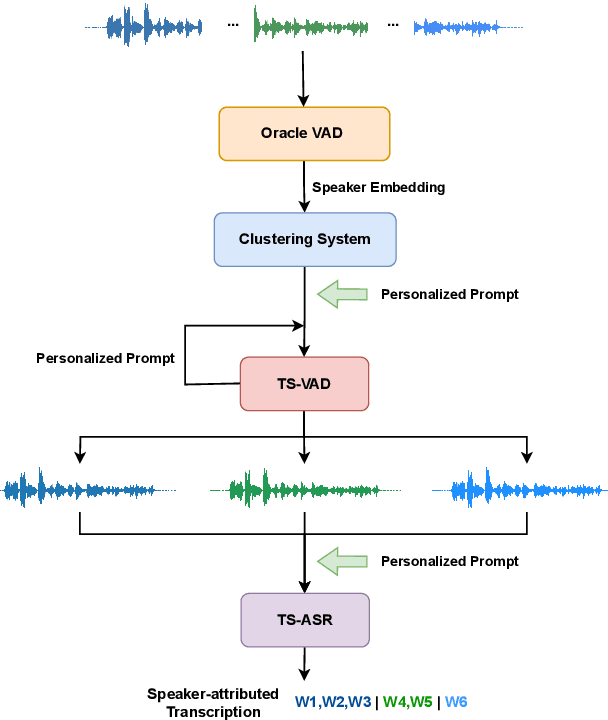
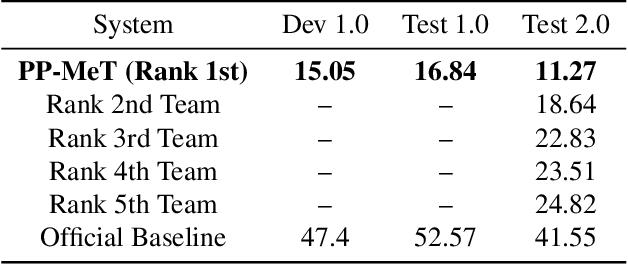
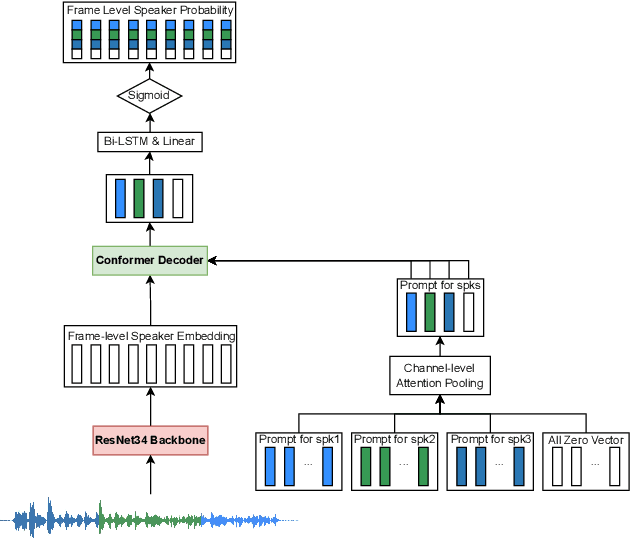

Speaker-attributed automatic speech recognition (SA-ASR) improves the accuracy and applicability of multi-speaker ASR systems in real-world scenarios by assigning speaker labels to transcribed texts. However, SA-ASR poses unique challenges due to factors such as speaker overlap, speaker variability, background noise, and reverberation. In this study, we propose PP-MeT system, a real-world personalized prompt based meeting transcription system, which consists of a clustering system, target-speaker voice activity detection (TS-VAD), and TS-ASR. Specifically, we utilize target-speaker embedding as a prompt in TS-VAD and TS-ASR modules in our proposed system. In constrast with previous system, we fully leverage pre-trained models for system initialization, thereby bestowing our approach with heightened generalizability and precision. Experiments on M2MeT2.0 Challenge dataset show that our system achieves a cp-CER of 11.27% on the test set, ranking first in both fixed and open training conditions.
PromptVC: Flexible Stylistic Voice Conversion in Latent Space Driven by Natural Language Prompts
Sep 17, 2023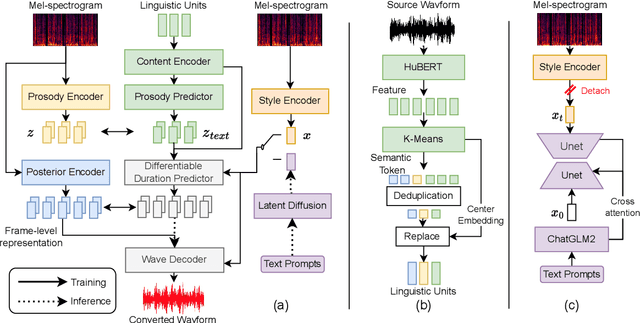

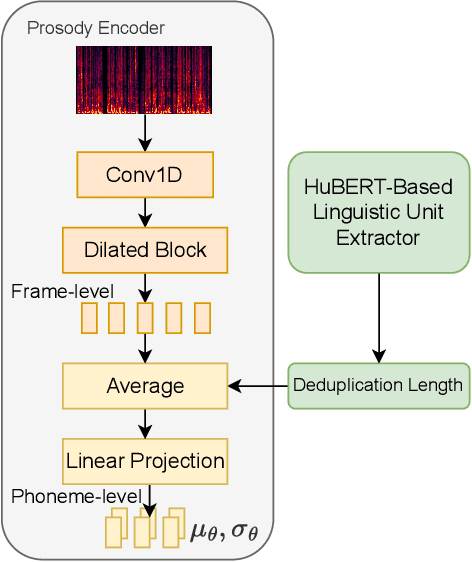
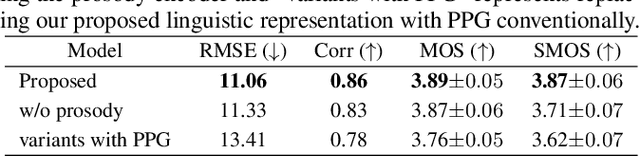
Style voice conversion aims to transform the style of source speech to a desired style according to real-world application demands. However, the current style voice conversion approach relies on pre-defined labels or reference speech to control the conversion process, which leads to limitations in style diversity or falls short in terms of the intuitive and interpretability of style representation. In this study, we propose PromptVC, a novel style voice conversion approach that employs a latent diffusion model to generate a style vector driven by natural language prompts. Specifically, the style vector is extracted by a style encoder during training, and then the latent diffusion model is trained independently to sample the style vector from noise, with this process being conditioned on natural language prompts. To improve style expressiveness, we leverage HuBERT to extract discrete tokens and replace them with the K-Means center embedding to serve as the linguistic content, which minimizes residual style information. Additionally, we deduplicate the same discrete token and employ a differentiable duration predictor to re-predict the duration of each token, which can adapt the duration of the same linguistic content to different styles. The subjective and objective evaluation results demonstrate the effectiveness of our proposed system.
GEmo-CLAP: Gender-Attribute-Enhanced Contrastive Language-Audio Pretraining for Speech Emotion Recognition
Jun 16, 2023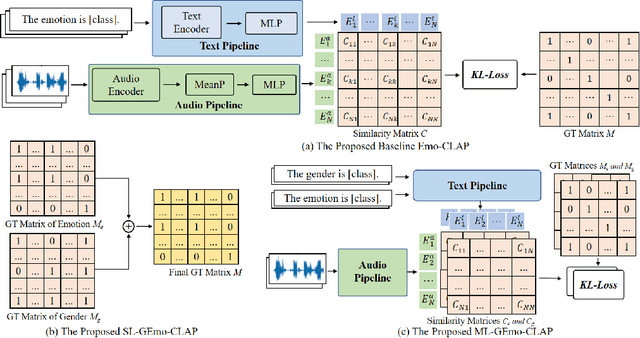
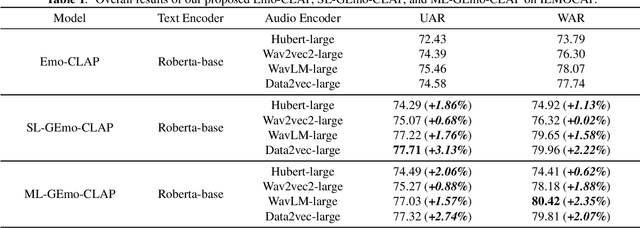
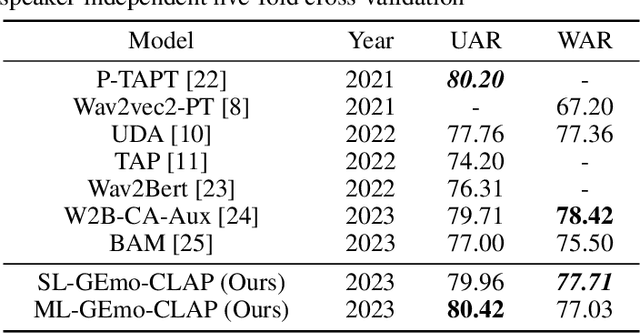
Contrastive learning based pretraining methods have recently exhibited impressive success in diverse fields. In this paper, we propose GEmo-CLAP, a kind of efficient gender-attribute-enhanced contrastive language-audio pretraining (CLAP) model for speech emotion recognition. To be specific, we first build an effective emotion CLAP model Emo-CLAP for emotion recognition, utilizing various self-supervised learning based pre-trained models. Then, considering the importance of the gender attribute in speech emotion modeling, two GEmo-CLAP approaches are further proposed to integrate the emotion and gender information of speech signals, forming more reasonable objectives. Extensive experiments on the IEMOCAP corpus demonstrate that our proposed two GEmo-CLAP approaches consistently outperform the baseline Emo-CLAP with different pre-trained models, while also achieving superior recognition performance compared with other state-of-the-art methods.
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023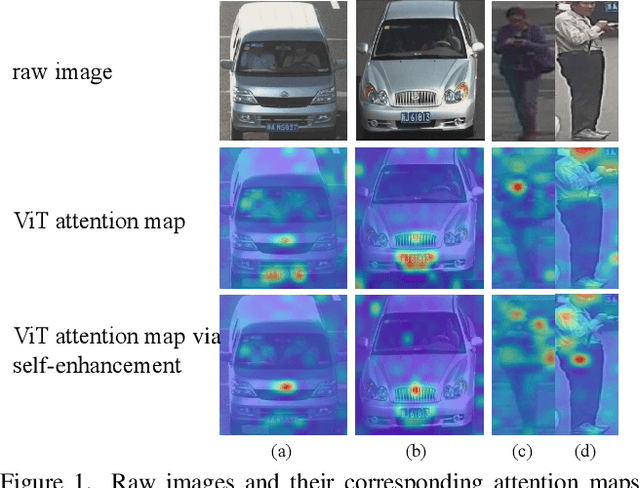
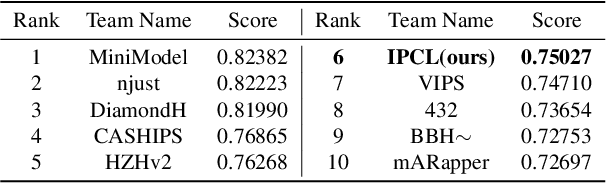
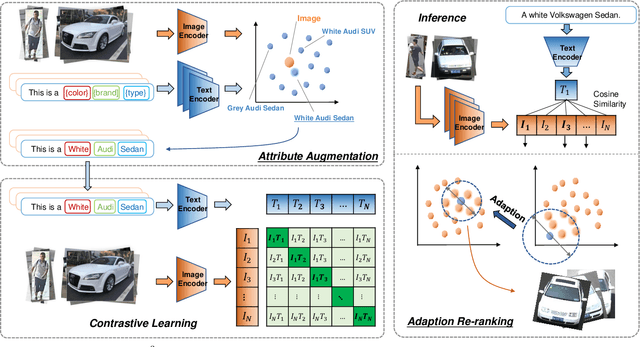

The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
May 27, 2023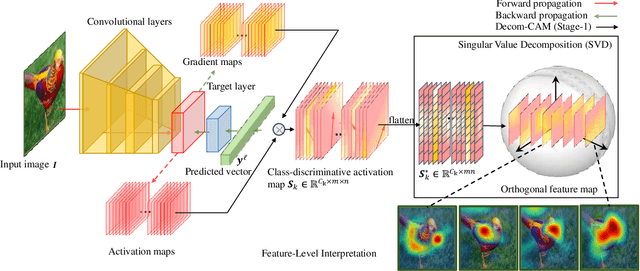


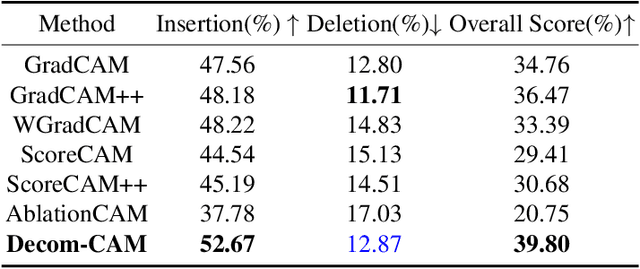
Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.
HYBRIDFORMER: improving SqueezeFormer with hybrid attention and NSR mechanism
Mar 15, 2023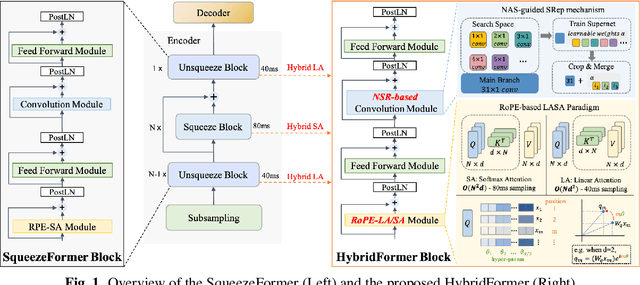
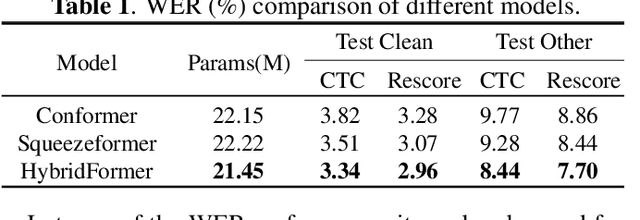
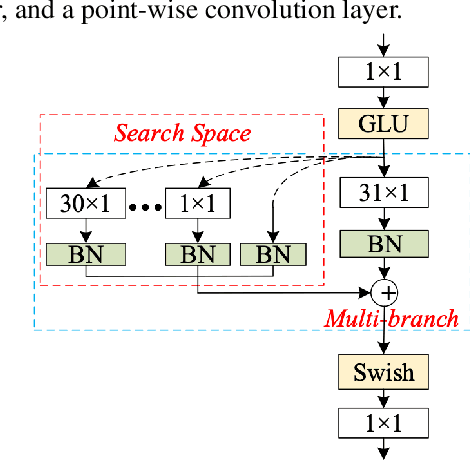
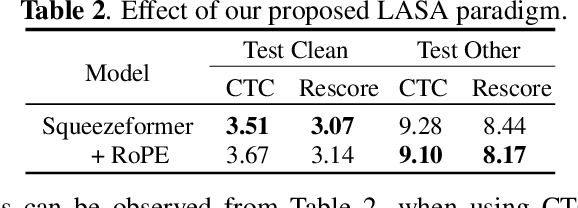
SqueezeFormer has recently shown impressive performance in automatic speech recognition (ASR). However, its inference speed suffers from the quadratic complexity of softmax-attention (SA). In addition, limited by the large convolution kernel size, the local modeling ability of SqueezeFormer is insufficient. In this paper, we propose a novel method HybridFormer to improve SqueezeFormer in a fast and efficient way. Specifically, we first incorporate linear attention (LA) and propose a hybrid LASA paradigm to increase the model's inference speed. Second, a hybrid neural architecture search (NAS) guided structural re-parameterization (SRep) mechanism, termed NSR, is proposed to enhance the ability of the model to extract local interactions. Extensive experiments conducted on the LibriSpeech dataset demonstrate that our proposed HybridFormer can achieve a 9.1% relative word error rate (WER) reduction over SqueezeFormer on the test-other dataset. Furthermore, when input speech is 30s, the HybridFormer can improve the model's inference speed up to 18%. Our source code is available online.
LMEC: Learnable Multiplicative Absolute Position Embedding Based Conformer for Speech Recognition
Dec 05, 2022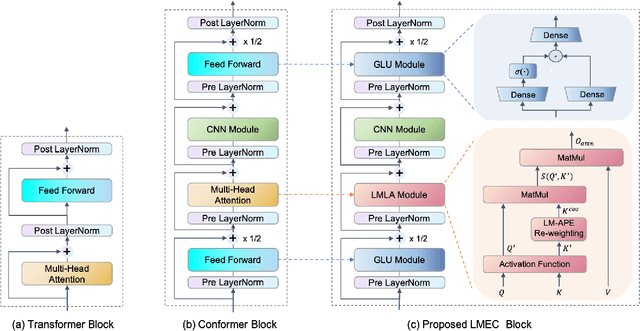

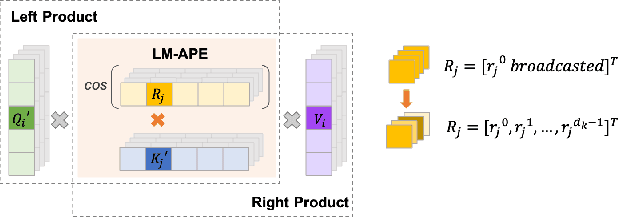
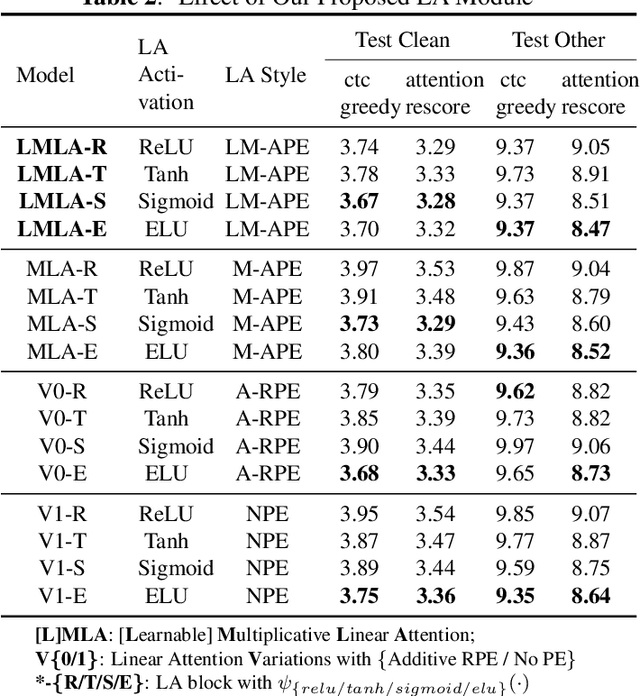
This paper proposes a Learnable Multiplicative absolute position Embedding based Conformer (LMEC). It contains a kernelized linear attention (LA) module called LMLA to solve the time-consuming problem for long sequence speech recognition as well as an alternative to the FFN structure. First, the ELU function is adopted as the kernel function of our proposed LA module. Second, we propose a novel Learnable Multiplicative Absolute Position Embedding (LM-APE) based re-weighting mechanism that can reduce the well-known quadratic temporal-space complexity of softmax self-attention. Third, we use Gated Linear Units (GLU) to substitute the Feed Forward Network (FFN) for better performance. Extensive experiments have been conducted on the public LibriSpeech datasets. Compared to the Conformer model with cosFormer style linear attention, our proposed method can achieve up to 0.63% word-error-rate improvement on test-other and improve the inference speed by up to 13% (left product) and 33% (right product) on the LA module.
Improving fairness in speaker verification via Group-adapted Fusion Network
Feb 23, 2022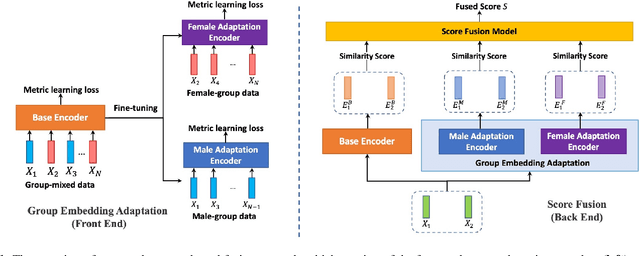
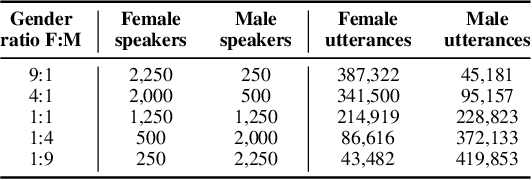

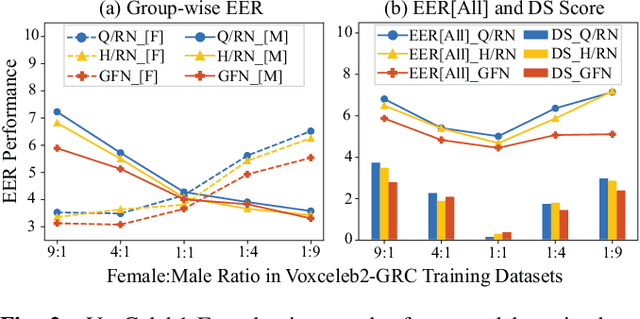
Modern speaker verification models use deep neural networks to encode utterance audio into discriminative embedding vectors. During the training process, these networks are typically optimized to differentiate arbitrary speakers. This learning process biases the learning of fine voice characteristics towards dominant demographic groups, which can lead to an unfair performance disparity across different groups. This is observed especially with underrepresented demographic groups sharing similar voice characteristics. In this work, we investigate the fairness of speaker verification models on controlled datasets with imbalanced gender distributions, providing direct evidence that model performance suffers for underrepresented groups. To mitigate this disparity we propose the group-adapted fusion network (GFN) architecture, a modular architecture based on group embedding adaptation and score fusion. We show that our method alleviates model unfairness by improving speaker verification both overall and for individual groups. Given imbalanced group representation in training, our proposed method achieves overall equal error rate (EER) reduction of 9.6% to 29.0% relative, reduces minority group EER by 13.7% to 18.6%, and results in 20.0% to 25.4% less EER disparity, compared to baselines. The approach is applicable to other types of training data skew in speaker recognition systems.
Self-supervised Speaker Recognition Training Using Human-Machine Dialogues
Feb 07, 2022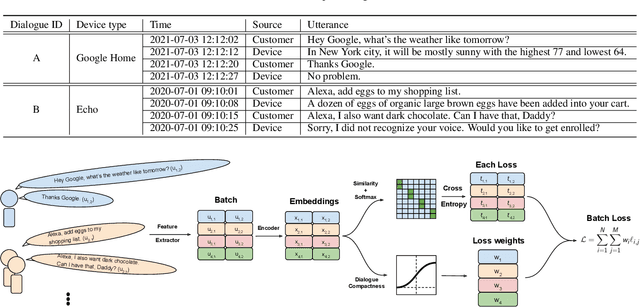
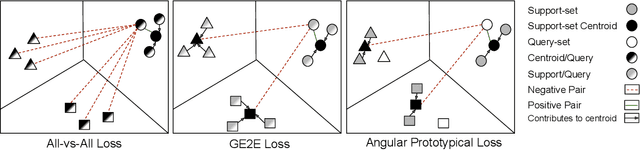
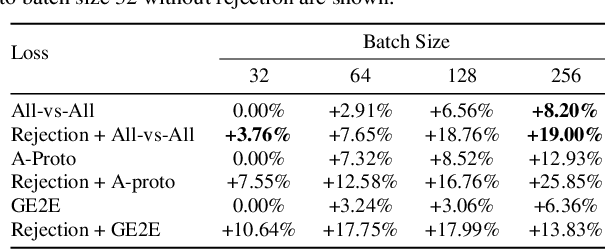
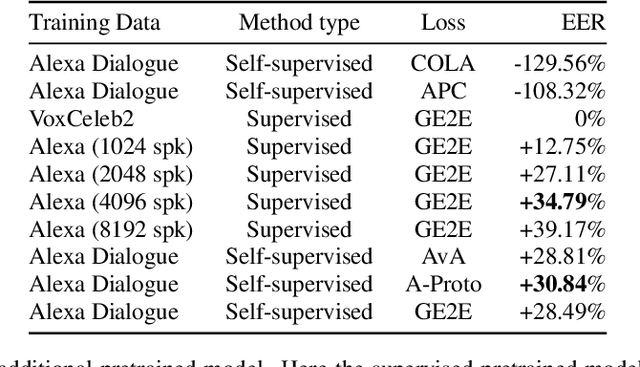
Speaker recognition, recognizing speaker identities based on voice alone, enables important downstream applications, such as personalization and authentication. Learning speaker representations, in the context of supervised learning, heavily depends on both clean and sufficient labeled data, which is always difficult to acquire. Noisy unlabeled data, on the other hand, also provides valuable information that can be exploited using self-supervised training methods. In this work, we investigate how to pretrain speaker recognition models by leveraging dialogues between customers and smart-speaker devices. However, the supervisory information in such dialogues is inherently noisy, as multiple speakers may speak to a device in the course of the same dialogue. To address this issue, we propose an effective rejection mechanism that selectively learns from dialogues based on their acoustic homogeneity. Both reconstruction-based and contrastive-learning-based self-supervised methods are compared. Experiments demonstrate that the proposed method provides significant performance improvements, superior to earlier work. Dialogue pretraining when combined with the rejection mechanism yields 27.10% equal error rate (EER) reduction in speaker recognition, compared to a model without self-supervised pretraining.
ASR-Aware End-to-end Neural Diarization
Feb 02, 2022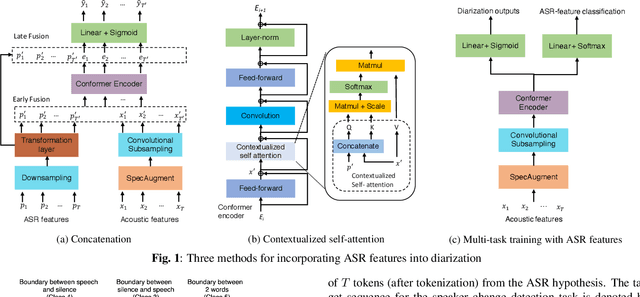
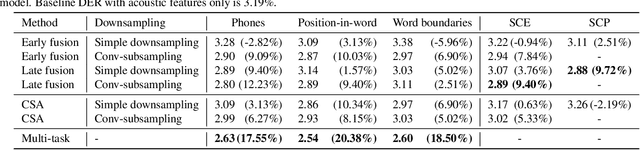
We present a Conformer-based end-to-end neural diarization (EEND) model that uses both acoustic input and features derived from an automatic speech recognition (ASR) model. Two categories of features are explored: features derived directly from ASR output (phones, position-in-word and word boundaries) and features derived from a lexical speaker change detection model, trained by fine-tuning a pretrained BERT model on the ASR output. Three modifications to the Conformer-based EEND architecture are proposed to incorporate the features. First, ASR features are concatenated with acoustic features. Second, we propose a new attention mechanism called contextualized self-attention that utilizes ASR features to build robust speaker representations. Finally, multi-task learning is used to train the model to minimize classification loss for the ASR features along with diarization loss. Experiments on the two-speaker English conversations of Switchboard+SRE data sets show that multi-task learning with position-in-word information is the most effective way of utilizing ASR features, reducing the diarization error rate (DER) by 20% relative to the baseline.