 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYu Pan
GMP-ATL: Gender-augmented Multi-scale Pseudo-label Enhanced Adaptive Transfer Learning for Speech Emotion Recognition via HuBERT
May 03, 2024
The continuous evolution of pre-trained speech models has greatly advanced Speech Emotion Recognition (SER). However, there is still potential for enhancement in the performance of these methods. In this paper, we present GMP-ATL (Gender-augmented Multi-scale Pseudo-label Adaptive Transfer Learning), a novel HuBERT-based adaptive transfer learning framework for SER. Specifically, GMP-ATL initially employs the pre-trained HuBERT, implementing multi-task learning and multi-scale k-means clustering to acquire frame-level gender-augmented multi-scale pseudo-labels. Then, to fully leverage both obtained frame-level and utterance-level emotion labels, we incorporate model retraining and fine-tuning methods to further optimize GMP-ATL. Experiments on IEMOCAP show that our GMP-ATL achieves superior recognition performance, with a WAR of 80.0\% and a UAR of 82.0\%, surpassing state-of-the-art unimodal SER methods, while also yielding comparable results with multimodal SER approaches.
DPGAN: A Dual-Path Generative Adversarial Network for Missing Data Imputation in Graphs
Apr 26, 2024Missing data imputation poses a paramount challenge when dealing with graph data. Prior works typically are based on feature propagation or graph autoencoders to address this issue. However, these methods usually encounter the over-smoothing issue when dealing with missing data, as the graph neural network (GNN) modules are not explicitly designed for handling missing data. This paper proposes a novel framework, called Dual-Path Generative Adversarial Network (DPGAN), that can deal simultaneously with missing data and avoid over-smoothing problems. The crux of our work is that it admits both global and local representations of the input graph signal, which can capture the long-range dependencies. It is realized via our proposed generator, consisting of two key components, i.e., MLPUNet++ and GraphUNet++. Our generator is trained with a designated discriminator via an adversarial process. In particular, to avoid assessing the entire graph as did in the literature, our discriminator focuses on the local subgraph fidelity, thereby boosting the quality of the local imputation. The subgraph size is adjustable, allowing for control over the intensity of adversarial regularization. Comprehensive experiments across various benchmark datasets substantiate that DPGAN consistently rivals, if not outperforms, existing state-of-the-art imputation algorithms. The code is provided at \url{https://github.com/momoxia/DPGAN}.
Uncertainty Estimation and Quantification for LLMs: A Simple Supervised Approach
Apr 24, 2024Large language models (LLMs) are highly capable of many tasks but they can sometimes generate unreliable or inaccurate outputs. To tackle this issue, this paper studies the problem of uncertainty estimation and calibration for LLMs. We begin by formulating the uncertainty estimation problem for LLMs and then propose a supervised approach that takes advantage of the labeled datasets and estimates the uncertainty of the LLMs' responses. Based on the formulation, we illustrate the difference between the uncertainty estimation for LLMs and that for standard ML models and explain why the hidden activations of the LLMs contain uncertainty information. Our designed approach effectively demonstrates the benefits of utilizing hidden activations for enhanced uncertainty estimation across various tasks and shows robust transferability in out-of-distribution settings. Moreover, we distinguish the uncertainty estimation task from the uncertainty calibration task and show that a better uncertainty estimation mode leads to a better calibration performance. In practice, our method is easy to implement and is adaptable to different levels of model transparency including black box, grey box, and white box, each demonstrating strong performance based on the accessibility of the LLM's internal mechanisms.
PromptCodec: High-Fidelity Neural Speech Codec using Disentangled Representation Learning based Adaptive Feature-aware Prompt Encoders
Apr 13, 2024Neural speech codec has recently gained widespread attention in generative speech modeling domains, like voice conversion, text-to-speech synthesis, etc. However, ensuring high-fidelity audio reconstruction of speech codecs under low bitrate remains an open and challenging issue. In this paper, we propose PromptCodec, a novel end-to-end neural speech codec using feature-aware prompt encoders based on disentangled representation learning. By incorporating prompt encoders to capture representations of additional input prompts, PromptCodec can distribute the speech information requiring processing and enhance its representation capabilities. Moreover, a simple yet effective adaptive feature weighted fusion approach is introduced to integrate features of different encoders. Meanwhile, we propose a novel disentangled representation learning strategy based on structure similarity index measure to optimize PromptCodec's encoders to ensure their efficiency, thereby further improving the performance of PromptCodec. Experiments on LibriTTS demonstrate that our proposed PromptCodec consistently outperforms state-of-the-art neural speech codec models under all different bitrate conditions while achieving superior performance with low bitrates.
Cumulative Distribution Function based General Temporal Point Processes
Feb 01, 2024Temporal Point Processes (TPPs) hold a pivotal role in modeling event sequences across diverse domains, including social networking and e-commerce, and have significantly contributed to the advancement of recommendation systems and information retrieval strategies. Through the analysis of events such as user interactions and transactions, TPPs offer valuable insights into behavioral patterns, facilitating the prediction of future trends. However, accurately forecasting future events remains a formidable challenge due to the intricate nature of these patterns. The integration of Neural Networks with TPPs has ushered in the development of advanced deep TPP models. While these models excel at processing complex and nonlinear temporal data, they encounter limitations in modeling intensity functions, grapple with computational complexities in integral computations, and struggle to capture long-range temporal dependencies effectively. In this study, we introduce the CuFun model, representing a novel approach to TPPs that revolves around the Cumulative Distribution Function (CDF). CuFun stands out by uniquely employing a monotonic neural network for CDF representation, utilizing past events as a scaling factor. This innovation significantly bolsters the model's adaptability and precision across a wide range of data scenarios. Our approach addresses several critical issues inherent in traditional TPP modeling: it simplifies log-likelihood calculations, extends applicability beyond predefined density function forms, and adeptly captures long-range temporal patterns. Our contributions encompass the introduction of a pioneering CDF-based TPP model, the development of a methodology for incorporating past event information into future event prediction, and empirical validation of CuFun's effectiveness through extensive experimentation on synthetic and real-world datasets.
Preparing Lessons for Progressive Training on Language Models
Jan 18, 2024The rapid progress of Transformers in artificial intelligence has come at the cost of increased resource consumption and greenhouse gas emissions due to growing model sizes. Prior work suggests using pretrained small models to improve training efficiency, but this approach may not be suitable for new model structures. On the other hand, training from scratch can be slow, and progressively stacking layers often fails to achieve significant acceleration. To address these challenges, we propose a novel method called Apollo, which prep\textbf{a}res lessons for ex\textbf{p}anding \textbf{o}perations by \textbf{l}earning high-\textbf{l}ayer functi\textbf{o}nality during training of low layers. Our approach involves low-value-prioritized sampling (LVPS) to train different depths and weight sharing to facilitate efficient expansion. We also introduce an interpolation method for stable model depth extension. Experiments demonstrate that Apollo achieves state-of-the-art acceleration ratios, even rivaling methods using pretrained models, making it a universal and efficient solution for training deep models while reducing time, financial, and environmental costs.
Reusing Pretrained Models by Multi-linear Operators for Efficient Training
Oct 16, 2023



Training large models from scratch usually costs a substantial amount of resources. Towards this problem, recent studies such as bert2BERT and LiGO have reused small pretrained models to initialize a large model (termed the ``target model''), leading to a considerable acceleration in training. Despite the successes of these previous studies, they grew pretrained models by mapping partial weights only, ignoring potential correlations across the entire model. As we show in this paper, there are inter- and intra-interactions among the weights of both the pretrained and the target models. As a result, the partial mapping may not capture the complete information and lead to inadequate growth. In this paper, we propose a method that linearly correlates each weight of the target model to all the weights of the pretrained model to further enhance acceleration ability. We utilize multi-linear operators to reduce computational and spacial complexity, enabling acceptable resource requirements. Experiments demonstrate that our method can save 76\% computational costs on DeiT-base transferred from DeiT-small, which outperforms bert2BERT by +12.0\% and LiGO by +20.7\%, respectively.
A Neural Tangent Kernel View on Federated Averaging for Deep Linear Neural Network
Oct 09, 2023Federated averaging (FedAvg) is a widely employed paradigm for collaboratively training models from distributed clients without sharing data. Nowadays, the neural network has achieved remarkable success due to its extraordinary performance, which makes it a preferred choice as the model in FedAvg. However, the optimization problem of the neural network is often non-convex even non-smooth. Furthermore, FedAvg always involves multiple clients and local updates, which results in an inaccurate updating direction. These properties bring difficulties in analyzing the convergence of FedAvg in training neural networks. Recently, neural tangent kernel (NTK) theory has been proposed towards understanding the convergence of first-order methods in tackling the non-convex problem of neural networks. The deep linear neural network is a classical model in theoretical subject due to its simple formulation. Nevertheless, there exists no theoretical result for the convergence of FedAvg in training the deep linear neural network. By applying NTK theory, we make a further step to provide the first theoretical guarantee for the global convergence of FedAvg in training deep linear neural networks. Specifically, we prove FedAvg converges to the global minimum at a linear rate $\mathcal{O}\big((1-\eta K /N)^t\big)$, where $t$ is the number of iterations, $\eta$ is the learning rate, $N$ is the number of clients and $K$ is the number of local updates. Finally, experimental evaluations on two benchmark datasets are conducted to empirically validate the correctness of our theoretical findings.
Exploring Federated Optimization by Reducing Variance of Adaptive Unbiased Client Sampling
Oct 04, 2023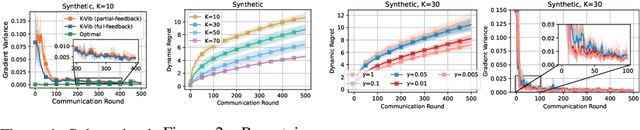
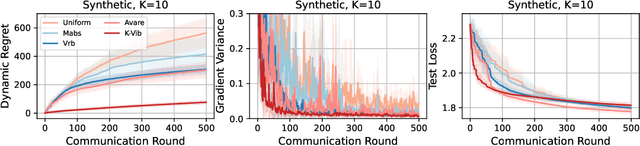
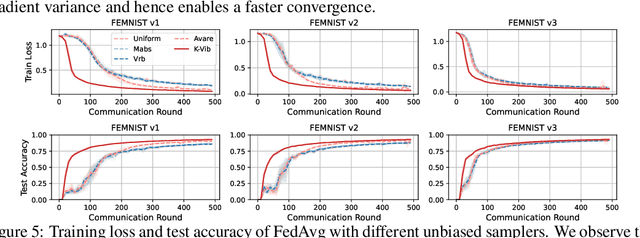
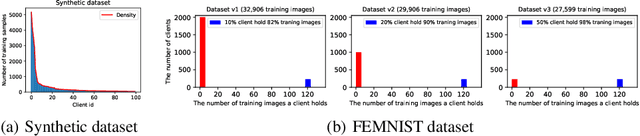
Federated Learning (FL) systems usually sample a fraction of clients to conduct a training process. Notably, the variance of global estimates for updating the global model built on information from sampled clients is highly related to federated optimization quality. This paper explores a line of "free" adaptive client sampling techniques in federated optimization, where the server builds promising sampling probability and reliable global estimates without requiring additional local communication and computation. We capture a minor variant in the sampling procedure and improve the global estimation accordingly. Based on that, we propose a novel sampler called K-Vib, which solves an online convex optimization respecting client sampling in federated optimization. It achieves improved a linear speed up on regret bound $\tilde{\mathcal{O}}\big(N^{\frac{1}{3}}T^{\frac{2}{3}}/K^{\frac{4}{3}}\big)$ with communication budget $K$. As a result, it significantly improves the performance of federated optimization. Theoretical improvements and intensive experiments on classic federated tasks demonstrate our findings.
Tackling Hybrid Heterogeneity on Federated Optimization via Gradient Diversity Maximization
Oct 04, 2023
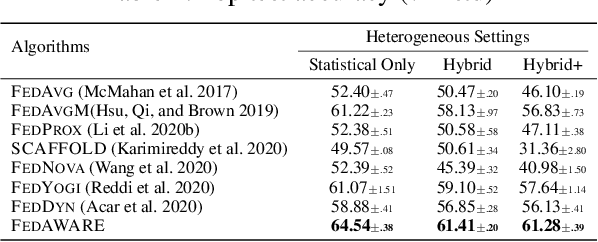
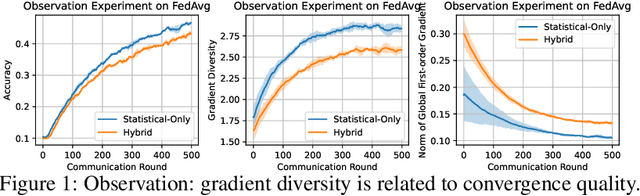
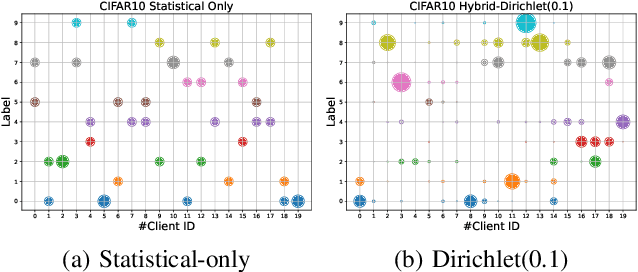
Federated learning refers to a distributed machine learning paradigm in which data samples are decentralized and distributed among multiple clients. These samples may exhibit statistical heterogeneity, which refers to data distributions are not independent and identical across clients. Additionally, system heterogeneity, or variations in the computational power of the clients, introduces biases into federated learning. The combined effects of statistical and system heterogeneity can significantly reduce the efficiency of federated optimization. However, the impact of hybrid heterogeneity is not rigorously discussed. This paper explores how hybrid heterogeneity affects federated optimization by investigating server-side optimization. The theoretical results indicate that adaptively maximizing gradient diversity in server update direction can help mitigate the potential negative consequences of hybrid heterogeneity. To this end, we introduce a novel server-side gradient-based optimizer \textsc{FedAWARE} with theoretical guarantees provided. Intensive experiments in heterogeneous federated settings demonstrate that our proposed optimizer can significantly enhance the performance of federated learning across varying degrees of hybrid heterogeneity.