 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYimi Wang
Self-Enhancement Improves Text-Image Retrieval in Foundation Visual-Language Models
Jun 11, 2023
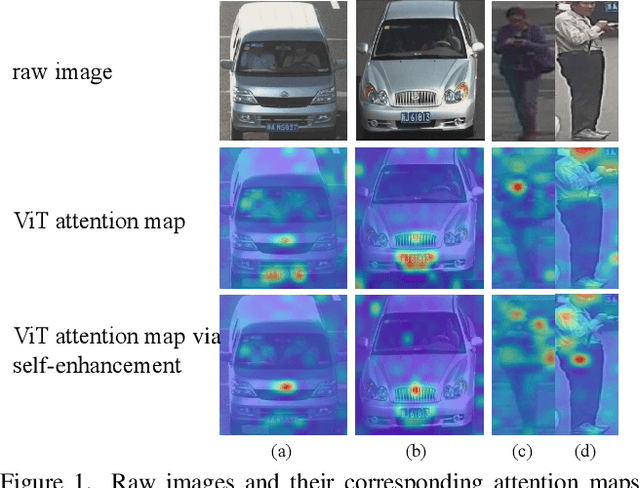
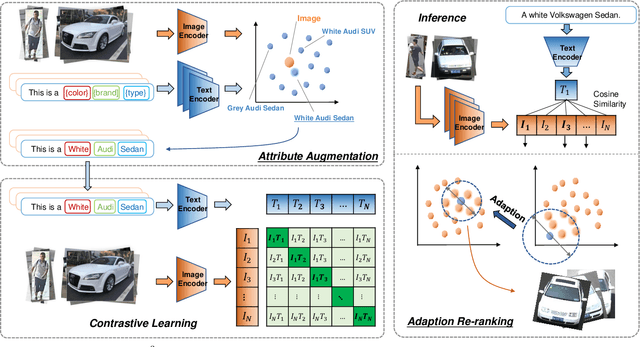

The emergence of cross-modal foundation models has introduced numerous approaches grounded in text-image retrieval. However, on some domain-specific retrieval tasks, these models fail to focus on the key attributes required. To address this issue, we propose a self-enhancement framework, A^{3}R, based on the CLIP-ViT/G-14, one of the largest cross-modal models. First, we perform an Attribute Augmentation strategy to enrich the textual description for fine-grained representation before model learning. Then, we propose an Adaption Re-ranking method to unify the representation space of textual query and candidate images and re-rank candidate images relying on the adapted query after model learning. The proposed framework is validated to achieve a salient improvement over the baseline and other teams' solutions in the cross-modal image retrieval track of the 1st foundation model challenge without introducing any additional samples. The code is available at \url{https://github.com/CapricornGuang/A3R}.
Decom--CAM: Tell Me What You See, In Details! Feature-Level Interpretation via Decomposition Class Activation Map
May 27, 2023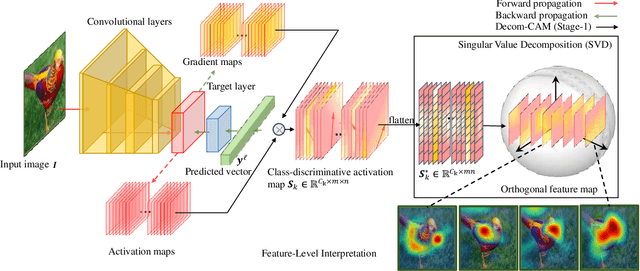


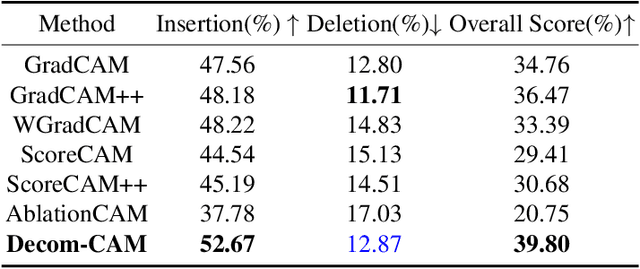
Interpretation of deep learning remains a very challenging problem. Although the Class Activation Map (CAM) is widely used to interpret deep model predictions by highlighting object location, it fails to provide insight into the salient features used by the model to make decisions. Furthermore, existing evaluation protocols often overlook the correlation between interpretability performance and the model's decision quality, which presents a more fundamental issue. This paper proposes a new two-stage interpretability method called the Decomposition Class Activation Map (Decom-CAM), which offers a feature-level interpretation of the model's prediction. Decom-CAM decomposes intermediate activation maps into orthogonal features using singular value decomposition and generates saliency maps by integrating them. The orthogonality of features enables CAM to capture local features and can be used to pinpoint semantic components such as eyes, noses, and faces in the input image, making it more beneficial for deep model interpretation. To ensure a comprehensive comparison, we introduce a new evaluation protocol by dividing the dataset into subsets based on classification accuracy results and evaluating the interpretability performance on each subset separately. Our experiments demonstrate that the proposed Decom-CAM outperforms current state-of-the-art methods significantly by generating more precise saliency maps across all levels of classification accuracy. Combined with our feature-level interpretability approach, this paper could pave the way for a new direction for understanding the decision-making process of deep neural networks.